Dynamically Scaling Containers With KEDA and IBM App Connect
This article demonstrates how to integrate Kubernetes Event-Driven Autoscaling (KEDA) with App Connect Enterprise to automatically scale containers as needed.
Join the DZone community and get the full member experience.
Join For FreePlanning for highly variable workloads has always been a difficult art, with the attendant risks of over-provisioning (leading to waste) or under-provisioning (leading to poor performance) of computing resources, but container-based solutions can handle the challenge in ways that would have been difficult in a static VM world.
To address this in some common cases, KEDA (Kubernetes Event-Driven Autoscaling) provides a way to automatically scale containers based on metrics such as IBM MQ queue depths, allowing scaling up as needed and then down to zero when the load dies away.
KEDA can be combined with App Connect Enterprise (ACE) to dynamically scale ACE flows using standard Kubernetes technology, allowing flows to be started and stopped based on demand. This has the potential to reduce overall resource consumption, and the combination of KEDA and ACE can be explored using demo artifacts that illustrate how to make the technologies work together.
Quick summary: ACE fits naturally in Kubernetes so standard KEDA techniques work without modification, and a publicly-available demo shows how to do this.
What KEDA Does
To help understand what KEDA does and how it might be useful, consider the following timeline showing the lifecycle of ACE containers:
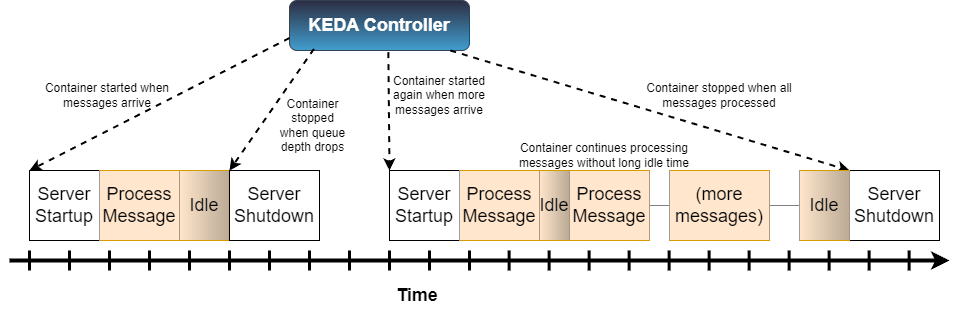
The system starts with no ACE containers running at all, and KEDA starts the initial ACE container when the first messages arrive. This could be when the first message appears or after a certain number of messages has arrived (see KEDA docs), but once ACE starts up, then it will process messages as usual.
ACE container lifetime is variable in the picture, with two examples shown here. The first sequence shows KEDA starting ACE when the first (and only) message arrives, and then after a configurable idle time, the ACE container is shut down again. In this case, the messages have significant gaps between them, so the server shuts down after each one to avoid consuming resources when there is no work.
The second case shows a variable rate of messages arriving, with the initial message being followed by a short pause (not long enough for KEDA to shut the container down) which is then followed by a burst of messages. This case amortizes the startup/shutdown cost over more messages, and so it is, in one sense, more efficient, but not all real-world scenarios look like this.
The previous timeline showed ACE containers scaling down to zero when there was no work, but KEDA does not have to operate this way. In the following timeline, one ACE container is always running, with more containers being started if the queue depth rises too far:
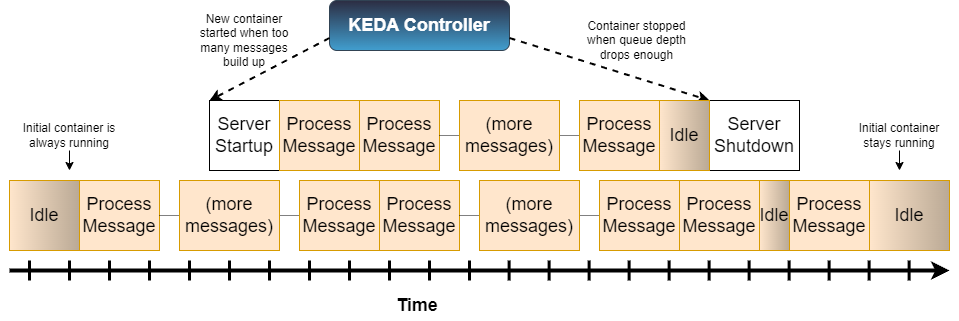
In this case, KEDA only steps in when there are too many messages and stops the server when the original server can handle the load by itself. This approach consumes more resources when no messages are arriving, but also provides a lower-latency response when messages do arrive, there is no need to wait for a server to start up before messages can be processed.
While these examples are shown using messages and queues, KEDA provides scalers that check Kafka topics, Blob storage, PostgreSQL, and many others; see https://keda.sh/docs/2.16/scalers/ for the complete list.
Why This Could Be Useful (And Some Cases Where It Isn’t)
Efficiency is often considered desirable, but there are also some specific benefits to dynamic scaling:
- Reducing environmental impact. KEDA can help "build sustainable platforms by optimizing workload scheduling and scale-to-zero" (see KEDA main page), avoiding the resource waste that sometimes accompanies cloud computing.
- Aligning costs with actual usage. Containers run only when there is work, making it very clear which applications are being used heavily.
- Reducing overall cluster size. If some workloads run only during the day while others run batch jobs overnight, KEDA can automatically scale them up and down as needed without the need for manual scheduling. Standard Kubernetes horizontal pod autoscaling cannot easily scale containers to zero, while KEDA expects to do so.
- Scaling containers that use non-HTTP protocols. Knative does a very good job with HTTP traffic, and Knative Events can handle some other cases, but KEDA offers a much broader array of possible transports and systems.
However, situations, where latency must be kept to a minimum in all cases, are not good candidates for a scale-to-zero KEDA solution: some messages will have to wait until a server is starting up for the first time, and this delay may be unacceptable. ACE v12/v13 startup can be optimized down to a few seconds in some cases, but this may still be too long for some scenarios.
How KEDA Operates
Conceptually, KEDA monitors available work and then changes the number of replicas on Kubernetes objects to handle the available work. For the IBM MQ and ACE scenario, this looks as follows (picture from the ACE KEDA demo repo):
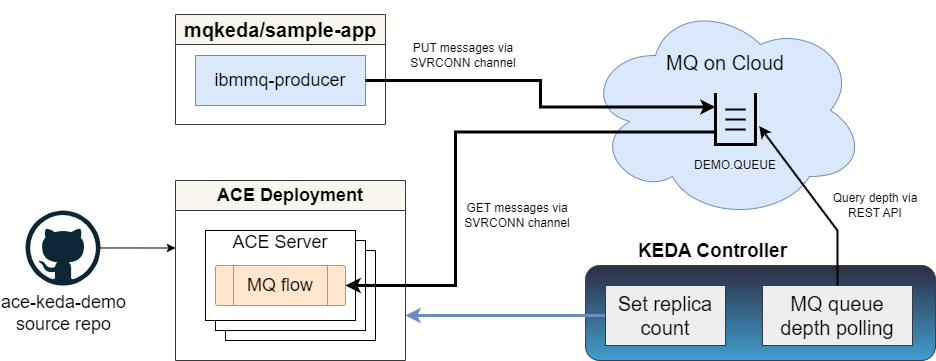
KEDA installation is relatively straightforward, with a simple kubectl apply on Kubernetes and an even simpler operator install for OpenShift using RedHat's Custom Metrics Autoscaler. As is often the case, however, there are many details that need to line up for this approach to work.
One example is KEDA needing security credentials that allow it to poll the queue depths, and in this case, this means using the MQ REST API instead of the client channel connections used for actual messaging. There are also many parameters that can affect scaling, such as cooldown periods, polling intervals, etc.
An example definition for scaling the ace-keda-demo ACE deployment in response to the DEMO.QUEUE depth on queue manager MQoC might look as follows:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: ace-keda-demo
labels:
deploymentName: ace-keda-demo
spec:
scaleTargetRef:
name: ace-keda-demo
pollingInterval: 10 # Optional. Default: 30 seconds
cooldownPeriod: 30 # Optional. Default: 300 seconds
maxReplicaCount: 4 # Optional. Default: 100
triggers:
- type: ibmmq
metadata:
host: 'https://web-mqoc-ge59.qm.us-south.mq.appdomain.cloud/ibmmq/rest/v3/admin/action/qmgr/MQoC/mqsc'
queueManager: 'MQoC' # Your queue manager
queueName: 'DEMO.QUEUE' # Your queue name
unsafeSsl: "false"
authenticationRef:
name: ace-keda-demo-triggerThe authenticationRef points to a secret that contains the required credentials, but KEDA can also read secrets from environment variables in the target Deployment to avoid having to maintain the same secret in multiple places.
See https://keda.sh/docs/2.16/concepts/ for more details on how KEDA is designed or continue reading to try it out locally with the ACE KEDA demo.
ACE Demo
The demo artifacts are available at https://github.com/tdolby-at-uk-ibm-com/ace-keda-demo and provide a working example using a simple ACE flow scaled using KEDA based on IBM MQ queue depths. This demo can run in Minikube for a local test or run in OpenShift for a larger demonstration that can scale much further, with no need to purchase ACE or MQ: the demo can run using the evaluation edition of ACE and a free MQ on Cloud instance.
Tekton pipelines are used to build the application, which is a simple application that prints out incoming messages to the console:

The application is designed to be simple to make the demo simpler to run, but the same approach can scale to any ACE flow that relies on MQInput nodes. Other transports can also be used, including JMS and Kafka. ACE itself fits naturally into the Kubernetes world, and so scaling ACE is (from a KEDA point of view) no different from scaling any other application container, and this includes scaling Cloud Pak for Integration (CP4i) IntegrationRuntime containers.
This demo repo was originally created for a presentation on Serverless computing but has been enhanced and simplified for ACE v13.
Other ACE Demo Notes
- The repo uses Google's Crane tool to build container images quickly in a Tekton pipeline (which is probably worthy of a blog just by itself!)
- KEDA can poll MQ container-based queue managers if the REST API is available and KEDA has credentials. This relies on using a recent version of MQ: as described at https://www.ibm.com/docs/en/ibm-mq/9.3?topic=containers-support-mq-in, prior to the IBM MQ Operator 3.0 and IBM MQ 9.3.4 REST APIs were not supported.
- KEDA can be fussy about certificates, so it helps to have a well-known CA issuing certificates when using MQ in containers. MQ on Cloud uses such certificates, and no issues were found during testing.
Summary
KEDA offers one path to more efficient usage of container resources and works well with ACE due to the way ACE is designed (it would be much harder with IIB!). Regardless of whether ACE is used in CP4i containers or plain Kubernetes, KEDA is worth considering as a way to help manage compute resources, and the ACE KEDA demo shows a simple way to integrate the two technologies.
Published at DZone with permission of Trevor Dolby. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments