Effective API Design: 5 Principles to Keep Customers Coming Back
Join the DZone community and get the full member experience.
Join For FreeEditor’s Note: The following is an article written for and published in DZone’s 2021 API Design and Management Trend Report.
It is easy to get lost in the hype and excitement of our technological decisions — which database to use, which dependency injection framework works best, and which programming language is superior — and lose focus on our goal: Create an application that most effectively solves a customer’s problem. While languages and tools are an important facet of software design, they are not the only aspects we must consider.
In the end, our application is only practical if a client can easily access it through the interfaces we define. This requires effective API design. In this article, we will look at five of the most important principles of effective API design: independence, simplicity, consistency, error handling, and versioning.
Principles of Effective API Design
The goal of our APIs is to allow clients — anyone, including us, who consumes our APIs — to easily do useful work and obtain desired information. Since our clients can only access our application through its APIs, it is irrelevant how well our application is written if it has a poor interface.
Figure 1
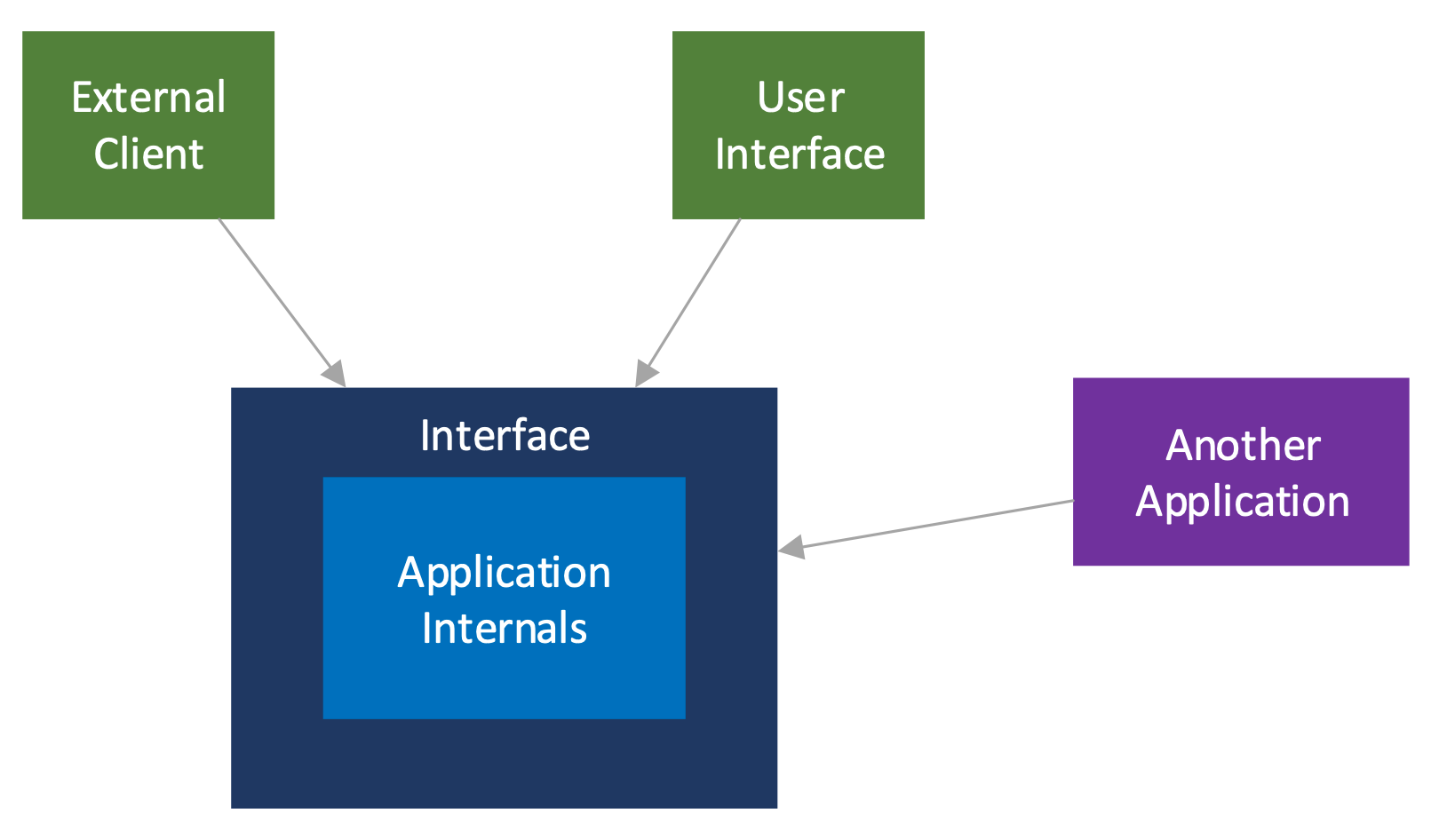
To design our APIs, we must consider what clients will find useful. Some of these facets are specific to a particular domain — such as using familiar terms — but others are universal.
Five of the most important principles are:
- Language independence – Letting clients select a programming language
- Simplicity – Minimal representation of data
- Consistency – Uniform representation of data
- Error handling – Concise notification when something goes wrong
- Versioning – Adding or removing features without breaking existing clients
There are countless other principles that go into effective API design, but these five represent the foundation for creating APIs that clients enjoy using. To make our APIs useful, we first have to reach the widest audience possible.
Language Independence
We all have our favorite languages and technologies, but imposing those choices on our clients limits the adoptability of our APIs. For example, if we choose to create a Java Messaging Service (JMS) API, we are pigeonholing our clients into using a Java EE-compliant implementation to consume the API.
Instead, we should always select the most language-agnostic option possible. In the current software environment, that means favoring choices like REST APIs (preferably using JSON request and response bodies), Advanced Message Queuing Protocol (AMQP), or even Protocol Buffers (protobuf). Each of these options has implementations in many of the popular languages, including Java, Python, and Ruby. By abstracting the programming language from the API design, we allow our client to select which programming language best suits their needs. This flexibility means that more customers can adopt and utilize our APIs.
This is an excerpt from DZone's 2021 API Design and Management Trend Report.
For more:
Read the Report
Simplicity
Simplicity has two major benefits: One for us and one for our clients. The benefit to us is that a simple API usually means less work on our part — less code, less tests, less room for errors, less development time, and less repetition. The benefit for our clients is that the code that consumes our API can be simpler — and likely smaller. Similar to our code, the code required to consume our APIs grows in proportion to complexity of our APIs (not to mention the additional tests and stubs for the client).
To ensure our API is as simple as possible, we should follow a few basic rules:
- Go with the simpler of two designs unless there is a very compelling reason not to.
- Use primitives, such as strings and numbers, as values whenever possible and only introduce new data structures when necessary.
- Only include information that is needed (i.e., follow the YAGNI principle) — future proofing results in more code to maintain and a larger API to consume.
Consistency
As clients use our APIs — especially those that use it frequently — they will begin to pick up on our conventions and come to expect them throughout the entire API. For example, if we have REST status resource with a key and display name, we can represent it in numerous ways, including as a nested object:
xxxxxxxxxx
{
"status": {
"key": "STARTED",
"displayName": "Started"
}
}
Or as two separate fields:
xxxxxxxxxx
{
"statusKey": "STARTED",
"statusDisplayName": "Started"
}
The best option will depend on the context and the nature of the API itself, but whichever we choose, we should stick with it and use it consistently. Staying consistent reaps some important benefits:
- Clients know that the common representation means that the resource has the same meaning everywhere it is used.
- Clients can create common code to handle the common representation.
- Clients can quickly understand the resource anywhere it appears because they have seen it before.
There are times when we have to break convention and use a different representation, but we should limit those cases to when we have a strong, compelling reason.
Error Handling
Although we want our applications to work as expected all the time, in real-world applications, this is not always possible. Failures can appear in both the request that a client sends us, as well as the responses we generate. For example, our API may be designed to find the address associated with a registered user, but if there is no user associated with the supplied user ID, then our API must signal an error.
Generally, a useful approach is to categorize an error and then provide details about that specific error. For REST APIs, that means using HTTP status codes and providing the details of the error in the response body. For message-based APIs, that means having some error code and some supplemental data — in the header or in the message body — to distinguish which specific error occurred.
While the error category may seem sufficient, there can be multiple reasons for one type of error. For example, if we return a 401 Unauthorized response from a REST API, the client may not know if the error is due to an incorrect username, incorrect password, or incorrect session ID. These details are important if we expect our client to handle errors in our API. Therefore, we must provide pertinent and detailed information about the error (without sacrificing simplicity).
Versioning
One of more overlooked aspects of effective API design is versioning. For most projects, it is difficult to see where our API will be six months, a year, or even five years from now, but it is important to prepare for the future. Eventually, our APIs will evolve and we will add new features and remove unneeded ones, but we cannot break existing clients. If a client expects a resource to be available or a message to have a specific format, it would be poor API design to change those existing expectations (especially without deprecating them first and giving the client time to adapt).
Instead, we need to version our APIs. For REST APIs, we can include some version string (such as v1) in the URL:
/api/v1/foo/bar
This allows clients to continue to call /api/v1, even when version 2 releases, ensuring that the APIs that the customer depends on remain stable. For message-based APIs, this may mean including a version header that distinguishes one version of a message from another.
Figure 2
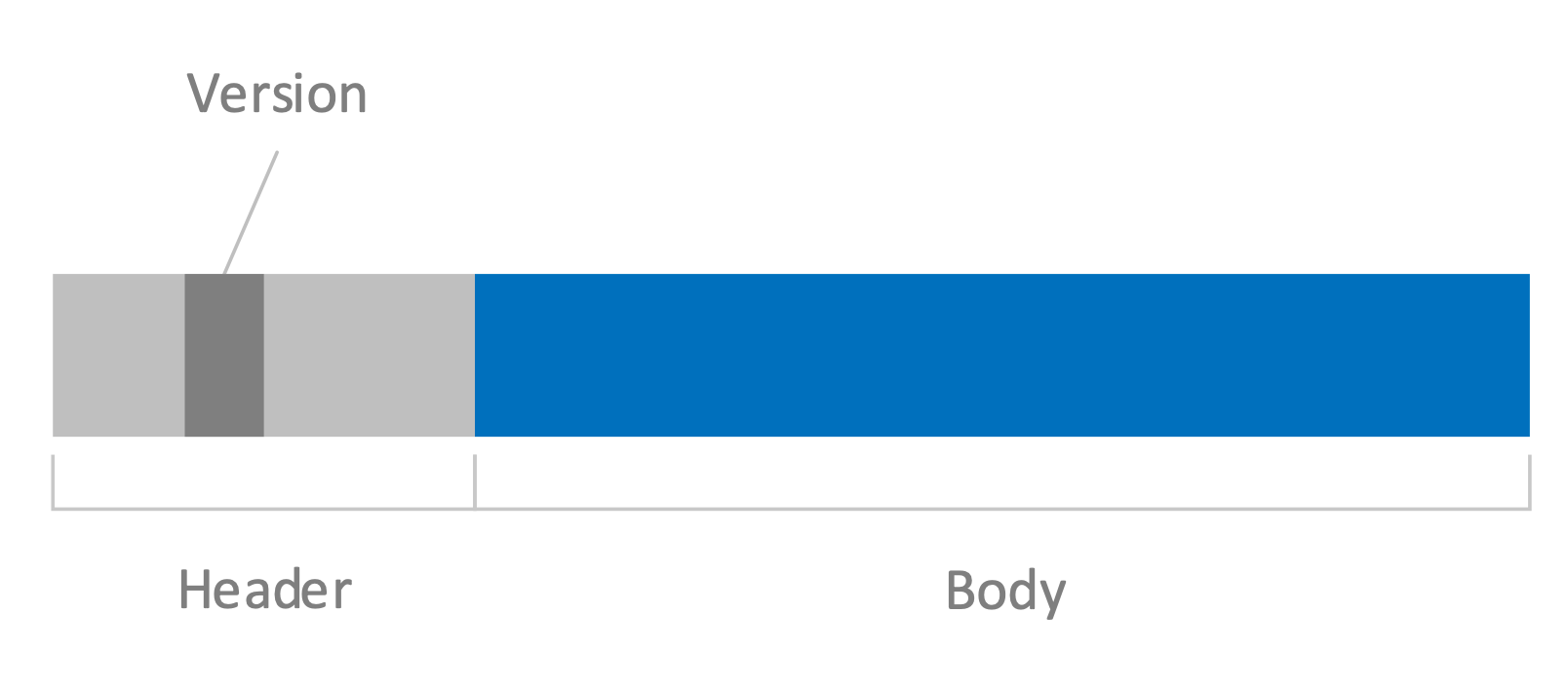
Regardless of the mechanism we choose, it is important to plan for the future and consider the stability of our clients. This simple addition will go a long way in keeping customers for a long time and reducing their anxiety each time we release a new version of our APIs.
Conclusion
There are countless, small details that go into making APIs that effectively solve our customer’s problems. This alone can bog us down in pursuit of a perfect API design. Instead, we should focus on the most important tenets of effective API design — namely language independence, simplicity, consistency, error handling, and versioning. While not comprehensive, these alone can dramatically improve our API designs and make our APIs a pleasure to use.
Opinions expressed by DZone contributors are their own.
Comments