Effective MongoDB Indexing (Part 1)
Understanding and using indexes effectively is of paramount importance when optimizing MongoDB performance. This series will help you do this to your best ability!
Join the DZone community and get the full member experience.
Join For FreeAn index is an object with its own unique storage that provides a fast access path into a collection. Indexes exist primarily to enhance performance, so understanding and using indexes effectively is therefore of paramount importance when optimizing MongoDB performance.
B-Tree Indexes
The B-tree (“balanced tree”) index is MongoDB’s default index structure. Below is a high-level overview of B-tree index structure.
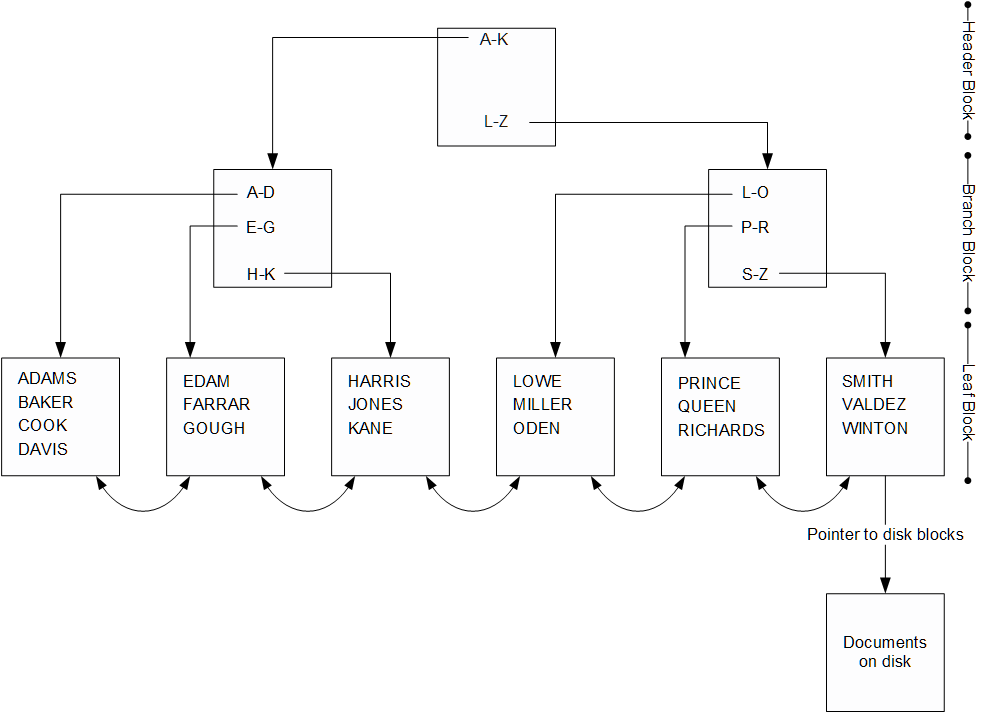
The B-tree index has a hierarchical tree structure. At the top of the tree is the header block. This block contains pointers to the appropriate branch block for any given range of key values. The branch block will usually point to the appropriate leaf block for a more specific range or, for a larger index, point to another branch block. The leaf block contains a list of key values and pointers to the location of documents on disk.
Examining the diagram above, let’s imagine how MongoDB would traverse this index. Should we need to access the record for “BAKER,” we would first consult the header block. The header block would tell us that key values starting with A through K are stored in the leftmost branch block. Accessing this branch block, we find that key values starting with A through D are stored in the leftmost leaf block. Consulting this leaf block, we find the value “BAKER” and its associated disk location, which we would then use to get to the document concerned.
Leaf blocks contain links to both the previous and the next leaf block. This allows us to scan the index in either ascending or descending order and allows range queries using $gt or $lt operators to be processed using the index.
B-tree indexes have the following advantages over other indexing strategies:
- Because each leaf node is at the same depth, performance is very predictable. In theory, no document in the collection will be more than three or four I/Os away.
- B-trees offer good performance for large collections because the depth is at most four (one header block, two levels of branch blocks and one level of leaf block). Generally, no document will take more than four I/Os to locate. In fact, because the header block will almost always be already loaded in memory, and branch blocks usually loaded in memory, the actual number of physical disk reads is usually only one or two.
- The B-tree index supports range queries as well as exact lookups. This is possible because of the links to the previous and next leaf blocks.
The B-tree index provides flexible and efficient query performance. However, maintaining the B-tree when changing data can be expensive. For instance, consider inserting a document with the key value “NIVEN” into the collection in our diagram above. To insert the collection, we must add a new entry into the “L-O” block. If there is free space within this block, then the cost is substantial, but perhaps not excessive. But what happens if there is no free space in the block?
If there is no free space within a leaf block for a new entry, then an index split is required. A new block must be allocated and half of the entries in the existing block moved into the new block. As well as this, there is a requirement to add a new entry to the branch block (in order to point to the newly created leaf block). If there is no free space in the branch block, then the branch block must also be split.
These index splits are an expensive operation: new blocks must be allocated and index entries moved from one block to another.
Index Selectivity
The selectivity of an attribute or group of attributes is a common measure of the usefulness of an index on those attributes. documents or indexes are selective if they have a large number of unique values or few duplicate values. For instance, the DATE_AND_TIME_OF_BIRTH attribute will be very selective while the GENDER attribute will not be selective.
Selective indexes are more efficient than non-selective indexes because they point more directly to specific values. The MongoDB optimizer will usually use the most selective index.
Unique Indexes
A unique index is one that prevents any duplicate values for the attributes that make up the index. If you try to create a unique index on a collection that contains such duplicate values you will receive an error. Similarly, you will also receive an error if you try and insert a document that contains duplicate unique index key values.
A unique index is typically created in order to prevent duplicate values rather than to improve performance. However, unique index documents are usually very efficient — they point to exactly one document and are therefore very selective.
Concatenated Indexes
A concatenated index is simply an index comprising more than one attribute. The advantage of a concatenated key is that it is often more selective than a single key index. The combination of attributes will point to a smaller number of documents than indexes composed of the individual attributes. A concatenated index that contains all of the attributes referred to in find() or $match clause will be particularly effective.
If you frequently query on more than one document within a collection, then creating a concatenated index for these documents is an excellent idea. For instance, we may query the people collection by Surname and Firstname. In that case, we would probably want to create an index on both Surname and Firstname. For instance:
db.people.createIndex({ "Surname":1 ,"Firstname":1} );Using such an index, we could rapidly find all people matching a given Surname\Firstname combination. Such an index will be far more effective than an index on Surname alone, or separate indexes on Surname and Firstname.
If a concatenated index could only be used when all of its keys appeared a find() or $match, then concatenated indexes would probably be of pretty limited use. Luckily, a concatenated index can be used very effectively providing any of the initial or leading attributes are used. Leading attributes are those that are specified earliest in the index definition.
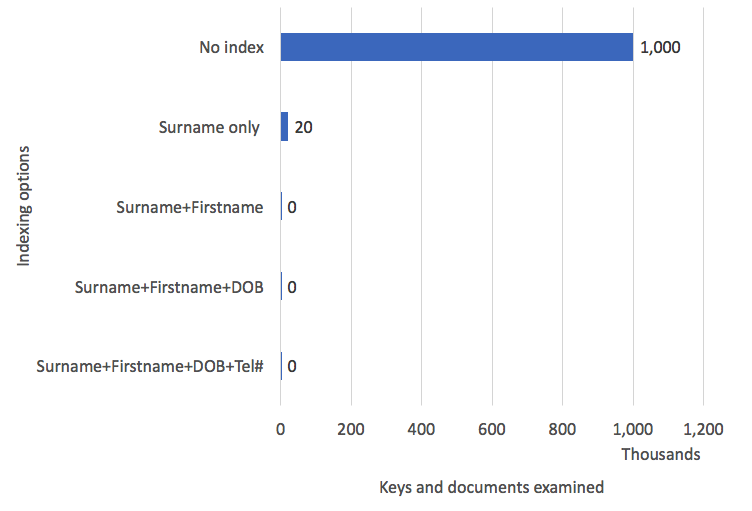
The figure above shows the improvements gained as attributes are added to a concatenated index. The query involved was in a 1,000,000-document people collection:
db.people.find(
{
Firstname: "KAREN",
Surname: "SMITH",
dob: ISODate("2006-01-21T05:55:32.520Z")
},
{ _id: 0, tel: 1 }
);We are retrieving a phone number by providing surname, firstname, and dob.
A full collection scan required that we access all the 1,000,000 documents. Indexing on surname alone reduced this to 20,028 documents — effectively, all the “SMITHS” in the collection. Adding firstname got the number of documents down to 188. By adding dob we were down to two accesses: access one index entry and from there access the collection to get the telephone number. The final optimisation is to add the telephone number tel attribute. Now we don’t have to access the collection at all — everything we need is in the index. This is sometimes referred to as a “covering” index.
Note that a covering index usually requires that the query include a projection that eliminates all attributes other than the attribute included in the index.
Guidelines for Concatenated Indexes
The following guidelines will help in deciding when to use concatenated indexes, and how to decide which attributes should be included and in which order.
- Create a concatenated index for attributes in a collection which appear together in a
find()or$matchcondition. - If attributes sometimes appear on their own in a
find()or$matchcondition, place them at the start of the index. - A concatenated index is more useful if it also supports queries where not all attributes are specified. For instance,
createIndex({"Surname":1,"Firstname":1})is more useful thancreateIndex({"Firstname":1,"Surname":1})because queries againstsurnameonly are more likely to occur than queries againstfirstnameonly. - The more selective an attribute is, the more useful it will be at the leading end of the index. However, note that WiredTiger index compression can radically shrink indexes. Index compression is more effective when leading columns are less selective. So you might have to experiment with index order if the order of attributes is not dictated by the first three considerations above.
Try out dbKoda, an open-source, free IDE now available for MongoDB! You can experiment with indexing options, build queries and aggregates and analyze explain plans from within a modern graphical interface.
If you enjoyed this article and want to learn more about MongoDB, check out this collection of tutorials and articles on all things MongoDB.
Published at DZone with permission of Guy Harrison. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments