Multi-Threaded Geo Web Crawler In Java
Dive Deep Into the Details of an [~Efficient Multi-Threaded Java Web Crawling System~] called Mowglee that uses Geography as the Main Classifying Criteria for Crawling.
Join the DZone community and get the full member experience.
Join For Free[Updates to the Article and Codebase / Code Snippets ~ 17/Feb/2021]
- Fixed Possible Con. Leaks in Network Connections
- Fixed Poor Code and Bad Programming Practices
- Improved Code Formatting, Practiced Clean Code*
- Mowglee v0.02a is Released (Previously, v0.01a')
This article provides the implementation of a web crawling system called Mowglee that uses geography as the main classifying criteria for crawling. Also, it runs in a multi-threaded mode that provides a default implementation of the robot's exclusion protocol, sitemap generation, data classifiers, data analyzers, and a general framework for application to be built of a web crawler. The implementation is in core Java. Mowglee is a multi-threaded geo web crawler in Java.
To do this, you should have intermediate to expert level core Java skills, an understanding of the intricacies of multi-threading in Java, and an understanding of the real-world usage of and need for web crawlers.
What You Will Learn
How to write simple and distributed node-based web crawlers in core Java.
How to design a web crawler for geographic affinity.
How to write multi-threaded or asynchronous task executor-based crawlers.
How to write web crawlers that have modular or pluggable architecture.
How to analyze multiple types of structured or unstructured data. (Covered Minimally)
Geo Crawling
The crawling system that I describe here works to maximize geography penetration in terms of higher reachability. It uses the most important or higher throughput hyperlinks of a specific geography as the starting points or crawl homes. The throughput refers to a number of varied links, text, or media with a higher data relevance for a given geography. It is developed using concepts of asynchronous task execution and multi-threading in Java.
The crawler is called Mowglee. It would be better to keep the 'user-agent' name the same, but you can add your own variant. For example, if you want to add the word 'raremile' to identify your variant, rename the user-agent 'mowglee-raremile'. Please make sure you have JDK 1.6+ installed on your system before you try to run this. Some of these classes have their own main() method, but they were written only for unit testing.
The main class to run the application is in.co.mowglee.crawl.core.Mowglee. You can also run the bundled JAR file under dist using java –jar mowglee.jar . If you are using JDK 6 for execution (recommended), then you can use jvisualvm for profiling.
In the figure, the class Mowglee is shown as MowgleeCentral.

Figure 1: Mowglee — Core Crawler
Mowglee's core crawling system uses a hierarchy of crawlers for efficient crawling. MowgleeCrawl is a class that sequentially invokes all crawl types in Mowglee: static crawling, periphery crawling, and site crawling.
MowgleeStaticCrawl is the starting class for the crawling process. This will read the static geographical home page or crawl home. You may configure multiple crawl homes for each geography and start a MowgleeStaticCrawl process for each of them. You can visualize this as a very loose representation of a multi-agent system. There is a default safe waiting period of ten seconds that can be configured as per your needs. This is to make sure that all data is available from other running processes or other running threads before we begin the main crawl.
MowgleePeripheryCrawl is the pass one crawler that deduces the top-level domains from a given page or hyperlink. It is built with the sole purpose of making MowgleeSiteCrawl (Pass 2) easier and more measurable. The periphery crawl process can also be used to remove any duplicate top-level domains across crawls for a more concentrated effort for the next pass. In Pass 1, we only concentrate on the links and not the data.
MowgleeSiteCrawl is the Pass 2 crawler for instantiating individual thread pools using the JDK 6 executor service for each MowgleeSite. The Mowglee crawl process at this stage is very extensive and very intrusive in terms of the type of data to detect. In Pass 2, we classify link types as protocol, images, video, or audio, and we also try to gain information on metadata for the page. The most important aspect of this phase is that we do analysis in a dynamic yet controlled fashion, as we try to increase the thread pool size as per the number of pages on the site.
Mowglee is organized as a set of workers within each of these crawling passes. For Pass 1, the actual work of reading and deduction is done by MowgleePeripheryWorker. For Pass 2, the work of reading and analyzing links is done by MowgleeSiteWorker. The helper classes that it uses during this includes data analyzers, as explained later.
MowgleePeripheryWorker uses MowgleeDomainMap for storing the top-level domains. The most important lines of code are in MowgleeUrlStream and are used to open a socket to any given URL and read its contents, which are provided below.
StringBuffer httpUrlContents = new StringBuffer();
InputStream inputStream = null;
InputStreamReader inputStreamReader = null;
MowgleeLogger mowgleeLogger = MowgleeLogger.getInstance("FILE");
// Check if the url is http
try {
if (crawlMode.equals(MowgleeConstants.MODE_STATIC_CRAWL)) {
mowgleeLogger.log("trying to open the file from " + httpUrl, MowgleeUrlStream.class);
inputStream = new FileInputStream(new File(httpUrl));
inputStreamReader = new InputStreamReader(inputStream);
} else {
mowgleeLogger.log("trying to open a socket to " + httpUrl, MowgleeUrlStream.class);
inputStream = new URL(httpUrl).openStream();
inputStreamReader = new InputStreamReader(inputStream);
}
// defensive
StringBuffer urlContents = new StringBuffer();
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String currentLine = bufferedReader.readLine();
while (currentLine != null) {
urlContents.append(currentLine);
currentLine = bufferedReader.readLine();
}
if (httpUrl != null & httpUrl.trim().length() > 0) {
MowgleePageReader mowgleePageReader = new MowgleePageReader();
mowgleePageReader.read(httpUrl, urlContents, crawlMode);
mowgleeLogger.log("the size of read contents are " + new String(urlContents).trim().length(),
MowgleeUrlStream.class);
}
// severe error fixed - possible memory leak in case of an exception! - [connection leak fixed]
// inputStream.close();
} catch (FileNotFoundException e) {
mowgleeLogger.log("the url was not found on the server due to " + e.getLocalizedMessage(),
MowgleeUrlStream.class);
} catch (MalformedURLException e) {
mowgleeLogger.log("the url was either malformed or does not exist", MowgleeUrlStream.class);
} catch (IOException e) {
mowgleeLogger.log("an error occured while reading the url due to " + e.getLocalizedMessage(),
MowgleeUrlStream.class);
} finally {
try {
// close the connection / file input stream
if (inputStream != null)
inputStream.close();
} catch (IOException e) {
mowgleeLogger.log("an error occured while closing the connection " + e.getLocalizedMessage(),
MowgleeUrlStream.class);
}
}
Listing 1: Mowglee — Opening Stream/Crawling.

Figure 2: Mowglee — Analyzers.
In Mowglee, there are various analyzers for multiple types of data and media. The analyzer that is implemented as part of this codebase is MowgleeLinkAnalyzer. It uses MowgleeSiteMap as the memory store for all links within a given top-level domain. It also maintains a list of visited and collected URLs from all the crawled and analyzed hyperlinks within a given top level domain.
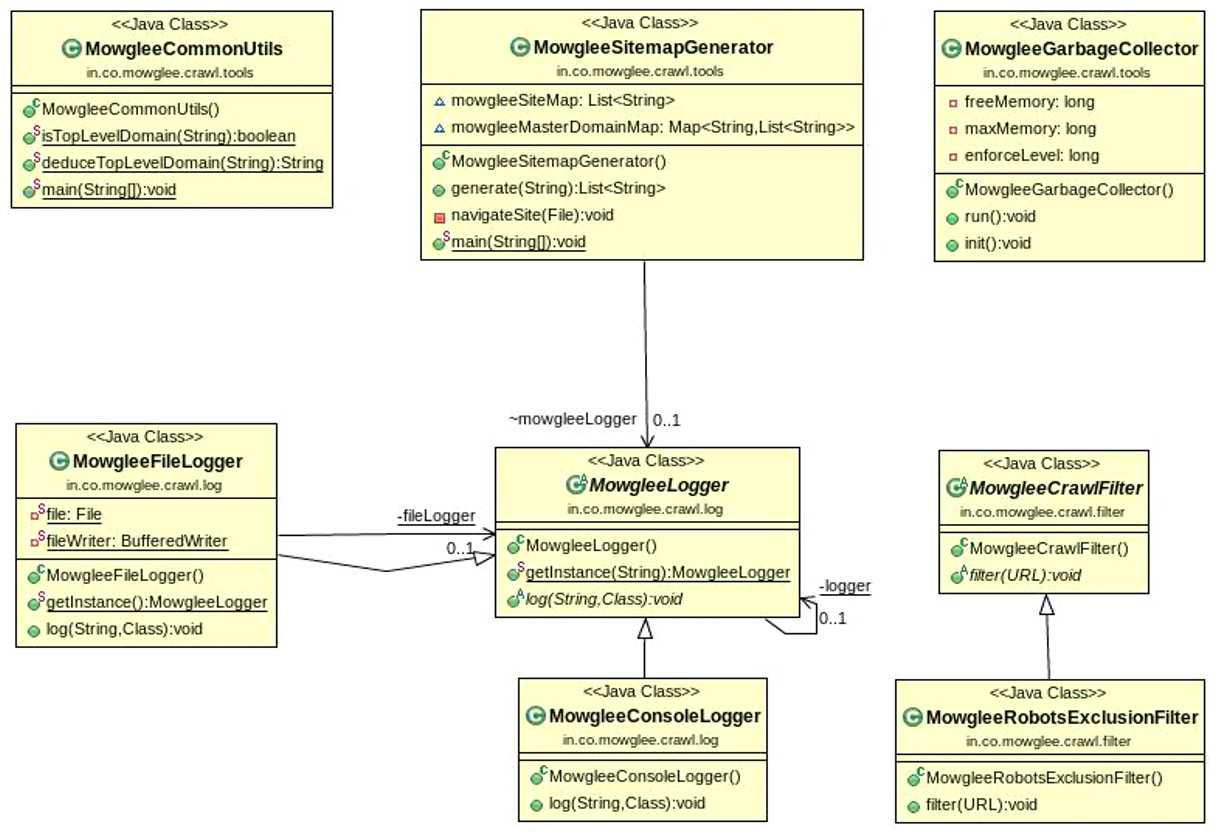
Figure 3: Mowglee – Filter, Logger, and Utilities.
MowgleeGarbageCollector is a daemon thread that is instantiated and started at the time of running the main application. As there are a large number of objects instantiated per thread, this thread tries to control and enforce the internal garbage collection mechanism within safe limits of memory usage. MowgleeLogger provides the abstract class for all types of loggers in Mowglee. Also, there is an implementation of RobotsExclusionProtocol provided under MowgleeRobotsExclusionFilter. This inherits from MowgleeCrawlFilter. All other types of filters that are closer to the functioning of a crawler system may extend from this particular class.
MowgleeCommonUtils provides a number of common helper functions, such as deduceTopLevelDomain(). owgleeSitemapGenerator is the placeholder class for generating the sitemap as per the sitemaps protocol, and a starting point for a more extensive or custom implementation. The implementations for analyzing images, video, and audio can be added. Only the placeholders are provided along.
Applications
The following would be the ideal applications of this category of web crawlers.
Website Governance and Government Enforcements
The enforcement of any localized or customized geographical rules can be done using this system. Also, any type of classification that is either done through manual deduction or automatic detection of patterns of data for any administrative purposes can be easily done through the generated data.
Ranking Sites and Links
The ranking of sites and links for a search engine system that is further localized to a particular geography or to specific areas can be performed on the data from this site. It would be easier to find relations and click patterns of links within the same geography.
Analytics and Data Patterns
The data collected from this crawler can be analyzed using third-party or custom tools for further knowledge creation. Also, relevant digital repositories can be created from generated volumes of data.
Advertising on the Basis of Keywords
An important application would be to drive advertising based on the data collected from this crawling system. An analyzer can be used to find specific terms, keywords, phrases, and embed relevant advertising or to generate advice for advertisers.
Enhancements
Following are some enhancements involving this category of web crawlers.
Store Using Graph Database
You may add your implementation of the graph database or use one of the popular NoSQL graph storage options. The starting point is the MowgleePersistenceCore class.
Varied Analyzers
You can add more analyzers for your own organizational or academic needs. The base class that you have to extend is MowgleeAnalyzer , and you can refer to MowgleeLinkAnalyzer to understand the analyzer's implementation.
Focused Classifiers
You can add a hierarchy of classifiers or plugins to automatically classify the data based on terms, keywords, geographic lingo, or phrases. An example is MowgleeReligiousAbusePlugin.
Complex Deduction Mechanisms
More complex deduction mechanisms to create further relevance of crawling within a specific geography may be added. This includes ignoring links outside of a geographic region, country, or even continent for a specific crawl session. At a higher level, such as at the continent level, this may be implemented as a coordinated multi-agent system.
Sitemap Generation
A starting point for the sitemap generation mechanism is provided here. You may also either use other sitemap generation libraries internally or develop your own custom implementation to enhance this functionality.
Conclusion
Mowglee does not guarantee that a sitemap will be created or used for crawling. It uses an async mechanism and makes sure that all links that may be not reachable from within a site to itself are also crawled. Mowglee does not have a termination mechanism currently. I have provided a placeholder for you to decide as per your usage. This could be based on the number of top level domains crawled, data volume, number of pages crawled, geography boundaries, types of sites to crawl, or an arbitrary mechanism.
Please shut down all applications on your system to dedicate all available system resources to Mowglee. The default starting crawl point is http://www.timesofindia.com. You may try by changing the starting crawl point to other sites as well. In the current form, you can use the mowglee.crawl file to read the crawl analysis. There is no other storage mechanism provided. You may keep this file open in an editor like EditPlus to continuously monitor its contents.
This article should have given you an excellent grounding in building a layered multi-threaded crawler, especially for applications that need geographically-based classifications and affinity. It should also help you save time (by re-using this codebase) to build your crawlers or applications out of this. You may also want to build enhancements out of Mowglee as mentioned above and post it back on DZone for the benefit of the entire community!
[Trivia Facts About the Piece of Code / Software]
Mowglee, Efficient Geo Web Crawler [Core Java]
Mowglee v0.02a (2021) - http://bit.do/mowglee
-
0. Published on My Own Online Technical Blog and Site – Techila Shots (.in)
1. Published in Online (Java) Developer Magazine – DZone
2. Article in Online/Print Java Magazine – JavaMag (.org)
3. Published in [CS] Mag – Computer Society of India Communications
4. Final Project for Part-Time AI Course at Indian Institute of Science (IISc)
Opinions expressed by DZone contributors are their own.
Comments