Engineering Evidence‑Grounded Review Pipelines With Hybrid RAG and LLMs
For high-stakes reviews, our Hybrid RAG and LLM framework ensures auditable AI by forcing structured, verified, and calibrated outputs
Join the DZone community and get the full member experience.
Join For FreeUnchecked language generation is not a harmless bug — it is a costly liability in regulated domains.
- A single invented citation in a visa evaluation can derail an application and triggering months of appeal.
- A hallucinated clause in a compliance report can result in penalties.
- A fabricated reference in a clinical review can jeopardize patient safety.
Large language models (LLMs) are not “broken”; they are simply unaccountable. Retrieval‑augmented generation (RAG) helps, but standard RAG remains brittle:
- Retrieval can miss critical evidence.
- Few pipelines verify whether generated statements are actually supported by retrieved text.
- Confidence scores are often uncalibrated or misleading.
If you are an engineer who is building applications that require a high level of trust, such as immigration, healthcare, or compliance, then "a chatbot with context" is nowhere near sufficient. You need methods that verify every claim, clearly signal uncertainty, and incorporate expert oversight.
This article describes a Hybrid RAG + LLM framework built with Django, FAISS, and open‑source NLP stacks. It combines:
- Dual‑track retrieval
- JSON‑enforced outputs
- Automated claim verification
- Confidence calibration
- Human oversight
Think of it as a pipeline that transforms LLMs from creative storytellers into auditable assistants.
Ingestion and Chunking
High‑stakes reviews involve messy, heterogeneous corpora: scanned PDFs, Word documents, HTML guidelines, and plain‑text notes. Each format introduces unique challenges.
Common pitfalls:
- Headers, tables, and references are often flattened or distorted.
- Unicode quirks (smart quotes, zero‑width spaces) corrupt embeddings.
- Personally Identifiable Information (PII) must be redacted.
Pipeline:
- Convert all documents to clean UTF‑8 text.
- Preserve structural elements (e.g. convert tables to JSON rather than flattening them).
- Split content into 400–800-token windows with ~15% overlap to maintain contextual continuity.
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=800,
chunk_overlap=120
)
chunks = splitter.split_text(cleaned_doc)This ensures safe, structured ingestion for downstream retrieval.
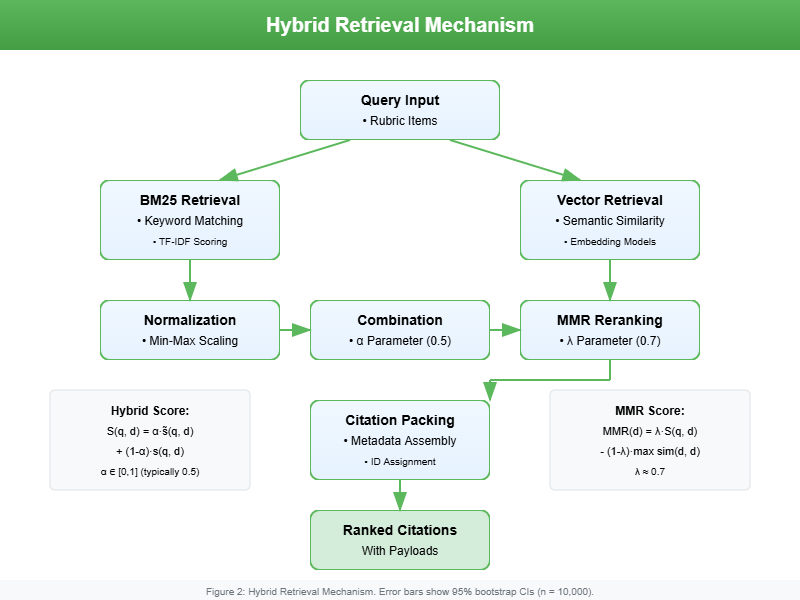
Hybrid Retrieval Engine
Keep in mind that no single retrieval method is sufficient on its own:
- BM25 (sparse retrieval): strong keyword precision.
- Dense embeddings: robust to paraphrasing and semantic variation.
We combine both using a hybrid scoring function:
S(q, d) = alpha * s_BM25(q, d) + (1 - alpha) * s_vec(q, d)
To improve diversity and reduce redundancy, documents are then re‑ranked using Maximal Marginal Relevance (MMR):
MMR(d_i) = lambda * S(q, d_i) - (1 - lambda) * max_j sim(d_i, d_j)
Infrastructure:
- Elasticsearch → BM25 retrieval
- FAISS (flat L2) → dense vector search using E5‑base embeddings
Grounded Generation
Retrieval provides context — but generation must be structured to be auditable.
Enforcement rules:
- Constrain outputs with a JSON schema (claims, citations, risks, scores).
- Require explicit citation IDs like
[C1]. - Use [MISSING] markers when no supporting evidence exists.
Prompt:
SYSTEM: You are a review assistant.
Cite evidence with [C#]. If none exists, write [MISSING].
Only output valid JSON. Validation:
from jsonschema import validate, ValidationError
try:
validate(instance=output, schema=review_schema)
except ValidationError:
# retry generation
passThis approach ensures determinism instead of improvisation.
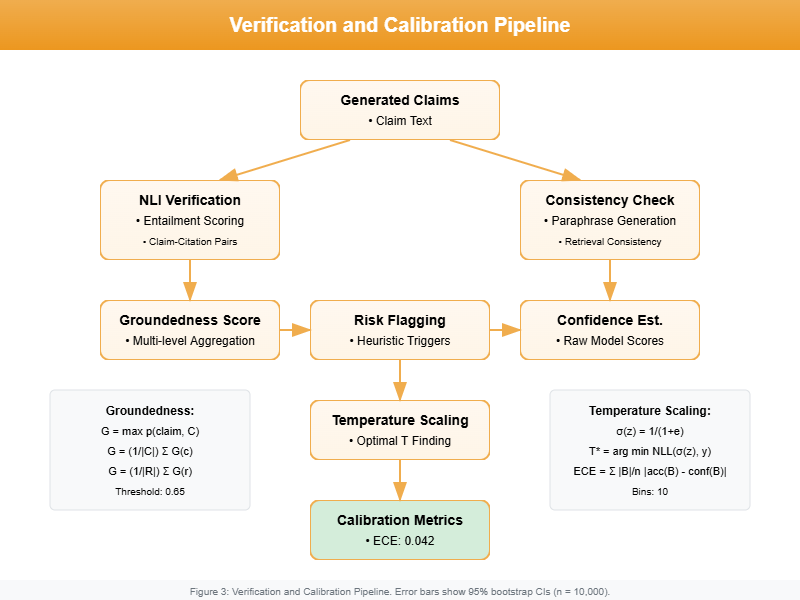
Verification and Calibration
1. Entailment Checking
Even when citations are present, claims may still be misinterpret the evidence. For example:
- Claim: “The candidate has indefinite leave to remain.”
- Evidence: “The candidate holds a temporary Tier‑2 visa.”
Both reference the same file, but the claim is contradicted.
We apply RoBERTa‑MNLI to verify:
G_claim = max_j p_entail(claim, C_j)
Claims under 0.5 → flagged for review.
2. Calibration
Softmax outputs are notoriously overconfident.
We apply temperature scaling:
sigma_T(z) = 1 / (1 + exp(-z / T))
T* is learned by minimizing log‑likelihood on a validation set.
After calibration, ECE drops from 0.079 → 0.042.
Human Oversight Interface
Automation reduces toil; human judgment ensures legitimacy.
- Django + htmx dashboard displays claim ↔ evidence pairs.
- Experts can accept, reject, or edit directly.
- Dual review model → arbitration if disagreement persists.
- All actions are recorded in immutable audit logs (SHA‑256).
Metric: κ = 0.87 inter‑rater reliability.
Results Snapshot
| Metric | Baseline (Atlas) | Hybrid Stack | Δ |
|---|---|---|---|
| Groundedness | 0.71 | 0.91 | +23 % |
| Hallucinations | 1.00 | 0.59 | –41 % |
| Calibration (ECE) | 0.079 | 0.042 | –47 % |
| Expert Acceptance | 0.75 | 0.92 | +17 % |
| Review Time (h) | 5.1 | 2.9 | –43 % |
Impact: At 10,000 visa cases per year, saving 2 hours per case = 20,000 expert hours recovered (roughly 10 FTEs).
Deployment Notes
- Framework: Django 4.2 + DRF
- Queue: Celery + Redis
- Search: Elasticsearch (BM25), FAISS embeddings
- Generation: GPT‑4 or Mixtral‑8x7B
- Verification: RoBERTa‑MNLI
- Scaling: Docker + Kubernetes; ~3GB per 1M chunks
Failure Modes and Mitigations
- Niche policy language → retrieval gaps → curated corpus.
- Long claims (>512 tokens) → NLI failure → chunk claims.
- Corpus bias → biased outputs → mitigate with human arbitration + refresh cycles.
Failures are design signals, not bugs.
Future Work
- Multilingual retrieval using LASER 3 embeddings for 50+ languages
- Template synthesis to auto-generate follow‑ups on
[MISSING]slots - Federated deployment — on‑prem embeddings with shared gradient updates
Conclusion
Developers working in regulated, high‑trust environments must move beyond raw LLMs.
A hybrid architecture — combining retrieval, schema enforcement, entailment verification, calibration, and human oversight — produces systems that are efficient, reliable, and auditable.
This blueprint applies not only to visa assessments, but also healthcare audits, regulatory compliance, and scientific literature validation.
Takeaway: This is not “AI for fun.” This system is design for trust. The stack and prompt set are open‑sourced under MIT license. Fork it, stress‑test it, and adapt it to your domain.
By treating grounding as a core architectural principle, we transform probabilistic LLMs into credible collaborators.
Opinions expressed by DZone contributors are their own.
Comments