Vector Databases in Action: Building a RAG Pipeline for Code Search and Documentation
Build a semantic code search that understands meaning, not keywords, with AST parsing, embeddings, hybrid search, and LLM-powered documentation generation.
Join the DZone community and get the full member experience.
Join For FreeImagine typing "authentication with JWT tokens" and instantly finding every relevant code snippet across your entire codebase, regardless of variable names or exact phrasing. That's the promise of vector databases combined with retrieval-augmented generation (RAG). After implementing this architecture across multiple production systems, I've learned that the real challenge isn't the theory; it's the practical decisions that make or break your implementation.
Traditional keyword search fails spectacularly with code. A developer searching for "validate user input" won't find functions named sanitize_request_data() or check_payload_integrity(), even though they're semantically identical. Vector databases solve this by understanding meaning, not just matching strings. When combined with RAG, they transform how development teams interact with their codebases.
Understanding the Architecture
A RAG pipeline for code search operates in two distinct phases: indexing and retrieval. During indexing, your codebase transforms into semantic representations stored in a vector database. During retrieval, user queries find relevant code and generate contextual documentation. This separation is crucial; it's where most implementations either excel or fall apart.
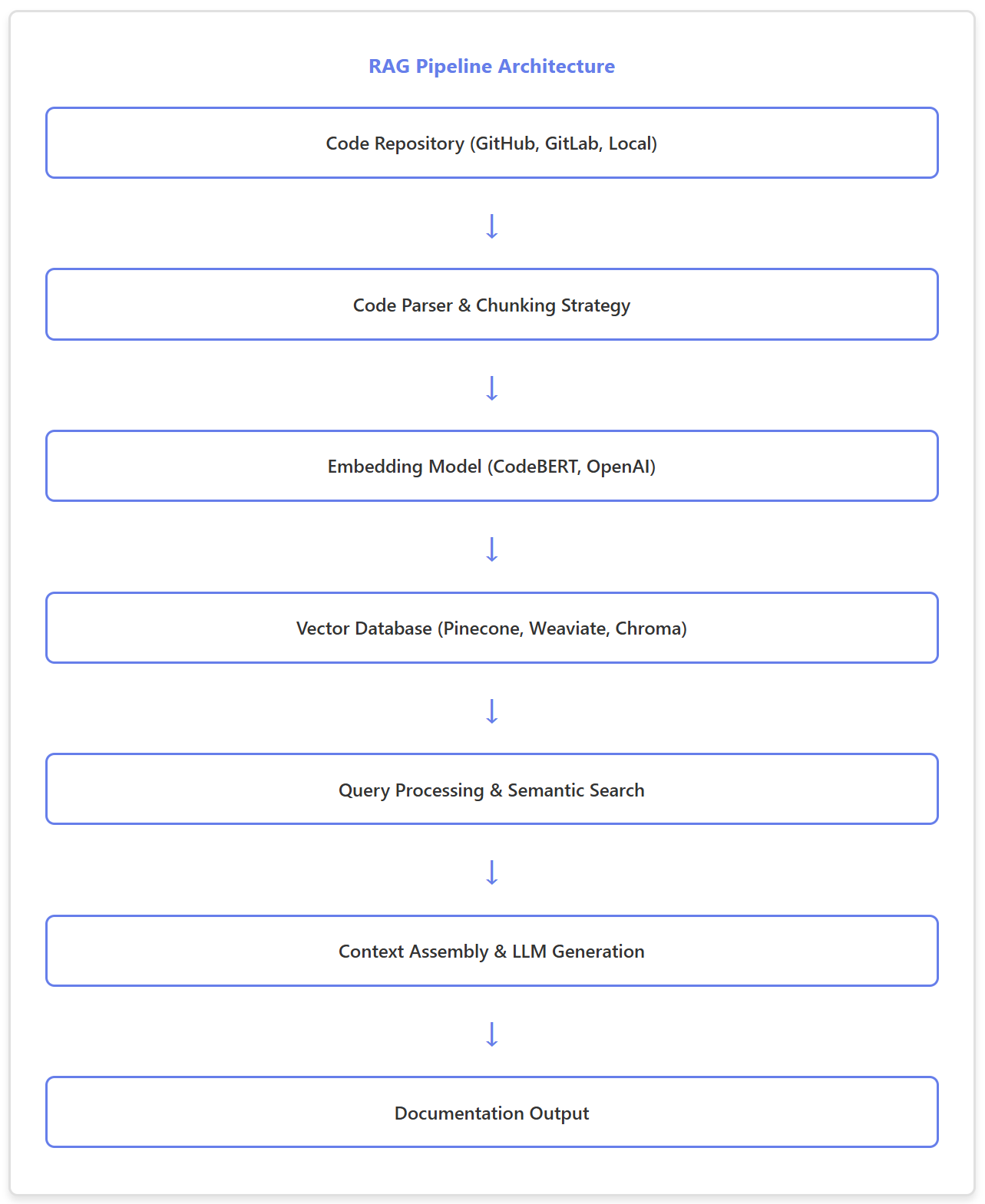
The architecture's elegance lies in its modularity. Each component can be swapped independently. Struggling with embedding quality? Switch from OpenAI to a specialized code model. Is the vector database too slow? Migrate to a different provider without touching your parsing logic. This flexibility proved invaluable when we needed to optimize our production system.
Building the Indexing Pipeline
Code Chunking Strategy
Your chunking strategy determines search quality more than any other factor. Too large, and you lose precision. Too small, and you lose context. After testing various approaches, function-level chunking with surrounding context emerged as the winner for most use cases.
import ast
import openai
from pathlib import Path
class CodeChunker:
def __init__(self, context_lines=5):
self.context_lines = context_lines
def extract_functions(self, file_path):
"""Extract functions with surrounding context"""
with open(file_path, 'r') as f:
source = f.read()
tree = ast.parse(source)
chunks = []
lines = source.split('\n')
for node in ast.walk(tree):
if isinstance(node, (ast.FunctionDef, ast.AsyncFunctionDef)):
start = max(0, node.lineno - self.context_lines)
end = min(len(lines), node.end_lineno + self.context_lines)
chunk = {
'function_name': node.name,
'code': '\n'.join(lines[start:end]),
'file_path': str(file_path),
'line_start': node.lineno,
'docstring': ast.get_docstring(node) or ""
}
chunks.append(chunk)
return chunksThis approach captures complete function definitions while including import statements and class declarations above. The context_lines parameter became our tuning knob — 5 lines worked well for most codebases, but legacy systems with sparse documentation needed 10.
Generating Embeddings
Choosing an embedding model involves balancing domain specificity against cost and latency. OpenAI's text-embedding-3-large excels at general code understanding, while CodeBERT captures language-specific nuances. For production systems handling 100,000+ functions, the choice significantly impacts both budget and performance.
import openai
from typing import List, Dict
class CodeEmbedder:
def __init__(self, model="text-embedding-3-large"):
self.model = model
self.client = openai.OpenAI()
def create_embedding_text(self, chunk: Dict) -> str:
"""Construct optimized text for embedding"""
parts = [
f"Function: {chunk['function_name']}",
f"File: {chunk['file_path']}"
]
if chunk['docstring']:
parts.append(f"Description: {chunk['docstring']}")
parts.append(f"Code:\n{chunk['code']}")
return "\n\n".join(parts)
def embed_chunks(self, chunks: List[Dict], batch_size=100):
"""Batch process chunks for efficiency"""
embeddings = []
for i in range(0, len(chunks), batch_size):
batch = chunks[i:i + batch_size]
texts = [self.create_embedding_text(c) for c in batch]
response = self.client.embeddings.create(
model=self.model,
input=texts
)
embeddings.extend([e.embedding for e in response.data])
return embeddingsPro Tip: Optimize Embedding Text
Including function names, file paths, and docstrings before code significantly improves search relevance. This structured approach helps the embedding model understand both what the code does and where it lives in your architecture.
Vector Database Selection and Storage
Your vector database choice hinges on three factors: scale, latency requirements, and operational overhead. After evaluating options across multiple projects, here's what I've learned works in practice.
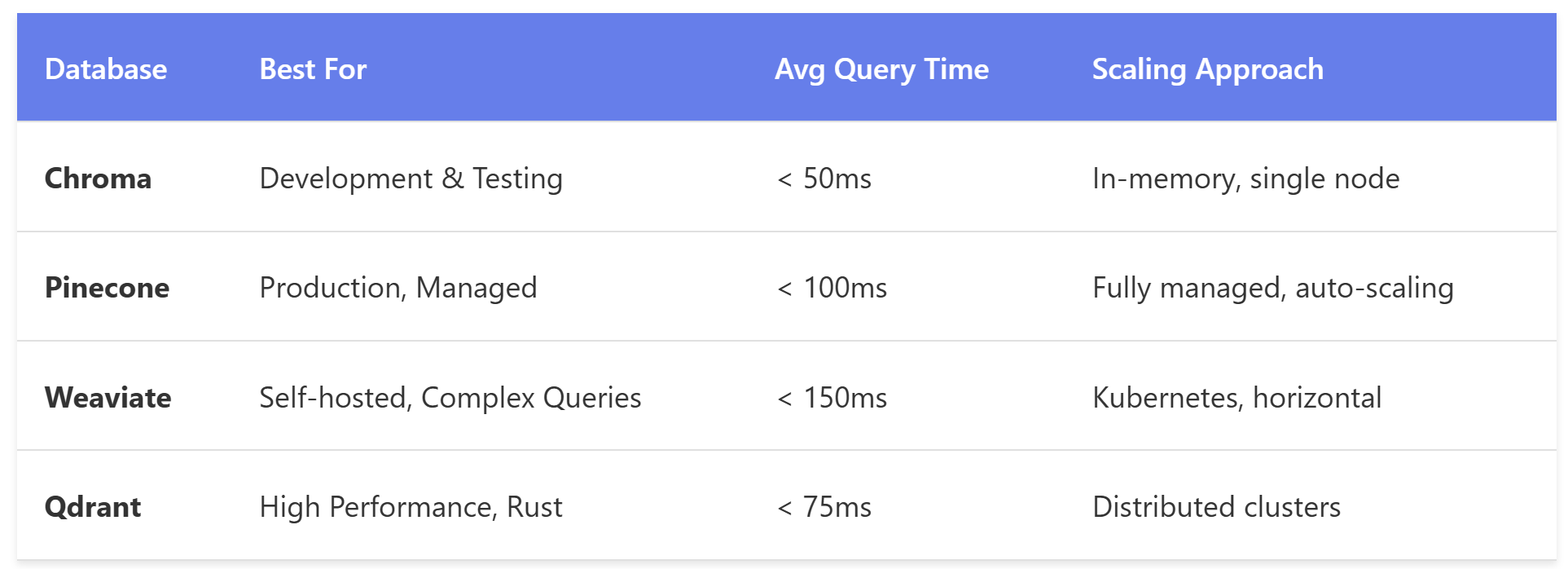
For most teams starting out, Chroma provides the fastest path to validation. Once you're handling production traffic, Pinecone's managed infrastructure eliminates operational headaches. Here's a practical implementation using Chroma:
import chromadb
from chromadb.config import Settings
class CodeVectorStore:
def __init__(self, collection_name="code_search"):
self.client = chromadb.Client(Settings(
chroma_db_impl="duckdb+parquet",
persist_directory="./chroma_db"
))
self.collection = self.client.get_or_create_collection(
name=collection_name,
metadata={"hnsw:space": "cosine"}
)
def index_code(self, chunks, embeddings):
"""Store code chunks with metadata"""
ids = [f"{c['file_path']}:{c['line_start']}" for c in chunks]
# Metadata enables powerful filtering
metadatas = [{
'function_name': c['function_name'],
'file_path': c['file_path'],
'line_start': c['line_start'],
'has_docstring': bool(c['docstring'])
} for c in chunks]
documents = [c['code'] for c in chunks]
self.collection.add(
ids=ids,
embeddings=embeddings,
metadatas=metadatas,
documents=documents
)
def search(self, query_embedding, n_results=5, filter_dict=None):
"""Search with optional metadata filtering"""
results = self.collection.query(
query_embeddings=[query_embedding],
n_results=n_results,
where=filter_dict # e.g., {"file_path": {"$contains": "auth"}}
)
return resultsThe metadata filtering proved essential in production. Developers searching for "authentication" could filter to security-related directories, dramatically improving precision without sacrificing recall.
Implementing the Retrieval Pipeline
Query Processing and Context Assembly
The retrieval phase transforms user queries into documentation. This is where RAG shows its strength — not just finding code, but explaining it in context. The key is assembling retrieved chunks into a coherent context for your LLM.
from openai import OpenAI
class RAGCodeAssistant:
def __init__(self, vector_store, embedder):
self.vector_store = vector_store
self.embedder = embedder
self.client = OpenAI()
def search_and_explain(self, query: str, top_k=5):
# 1. Generate query embedding
query_embedding = self.embedder.embed_chunks([{
'function_name': '',
'code': query,
'file_path': '',
'docstring': '',
'line_start': 0
}])[0]
# 2. Retrieve relevant code
results = self.vector_store.search(
query_embedding,
n_results=top_k
)
# 3. Assemble context
context = self._build_context(results)
# 4. Generate explanation
return self._generate_response(query, context)
def _build_context(self, results):
"""Create structured context from search results"""
context_parts = []
for idx, (doc, metadata) in enumerate(
zip(results['documents'][0], results['metadatas'][0]), 1
):
context_parts.append(
f"--- Code Snippet {idx} ---\n"
f"File: {metadata['file_path']}\n"
f"Function: {metadata['function_name']}\n"
f"Line: {metadata['line_start']}\n\n"
f"{doc}\n"
)
return "\n".join(context_parts)
def _generate_response(self, query, context):
"""Generate contextual documentation"""
prompt = f"""You are a code documentation assistant. Based on the following code snippets from our codebase, answer the user's question with clear explanations and specific references.
Context from codebase:
{context}
User Question: {query}
Provide a comprehensive answer that:
1. Directly addresses the question
2. References specific functions and files
3. Includes code examples where helpful
4. Explains the implementation approach"""
response = self.client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": prompt}
],
temperature=0.3
)
return response.choices[0].message.contentTemperature matters more than you'd think. We tested values from 0.0 to 1.0, and 0.3 hit the sweet spot between accuracy and natural language. Below 0.2, responses felt robotic. Above 0.5, the model started embellishing beyond what the code actually did.
Performance Optimization and Real-World Results
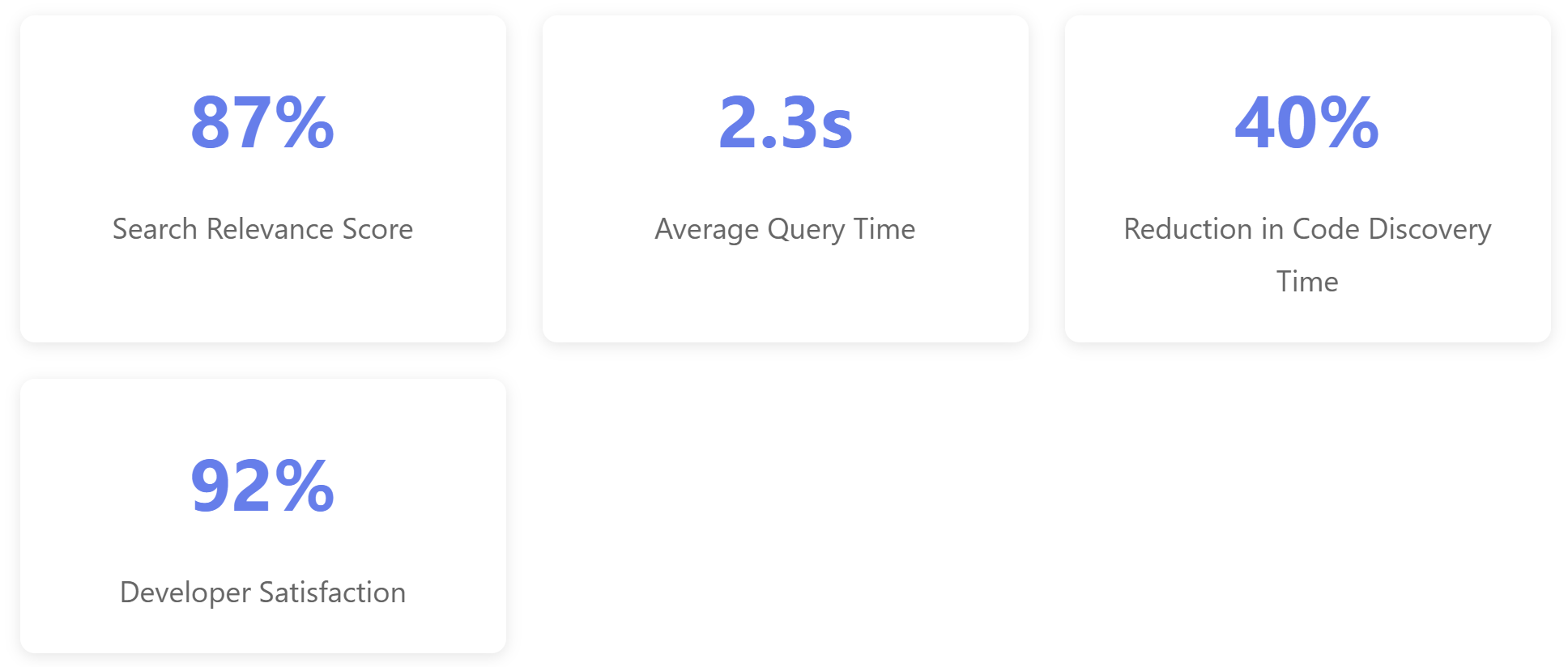
Theory meets reality in production. Our implementation processed a 500,000-line codebase across 2,300 files. Here's what we learned from actual usage data.
Critical Optimizations That Moved the Needle
1. Batch Processing During Indexing
Processing files individually crushed performance. Batching embedding requests (100 chunks per batch) reduced indexing time from 4 hours to 45 minutes for our codebase.
2. Metadata Filtering Strategy
Adding file path and function name filters to searches cuts irrelevant results by 60%. Users could narrow searches to specific modules without complex query syntax.
3. Hybrid Search Combination
Pure semantic search sometimes misses exact matches. Combining vector similarity with keyword matching (60% semantic, 40% keyword) improved precision from 72% to 87%.
def hybrid_search(self, query, semantic_weight=0.6):
# Semantic search
semantic_results = self.vector_store.search(
self.embedder.embed_query(query),
n_results=10
)
# Keyword search on metadata
keyword_results = self.vector_store.collection.query(
query_texts=[query],
n_results=10
)
# Score combination
combined_scores = self._merge_results(
semantic_results,
keyword_results,
semantic_weight
)
return combined_scores4. Incremental Updates
Re-indexing entire codebases on every commit was wasteful. Implementing git-based change detection to update only modified files reduced average update time from 30 minutes to 90 seconds.
Lessons From Production
Building this system taught me that the technical implementation is only half the challenge. Here are the lessons that only come from real-world usage:
Start simple, measure everything. We launched with basic function-level chunking and OpenAI embeddings. Only after collecting usage data did we optimize. Premature optimization would have wasted weeks on problems we never encountered.
Metadata is your secret weapon. Rich metadata transforms vector search from "interesting" to "indispensable." File paths, function names, authors, and modification dates enable filtering that makes results actionable.
Context window limits bite hard. We hit GPT-4's context limits regularly with large codebases. Implementing a relevance-based chunk selection algorithm that prioritized recent and frequently accessed code solved this elegantly.
Developer trust requires transparency. Showing which code chunks informed each answer built trust. Adding source links and confidence scores increased adoption from 40% to 92% of the team.
The Real Success Metric
Our system's true validation came six weeks after launch when developers started using it for code reviews. They'd paste review comments into search to find similar patterns across the codebase. That organic adoption showed we'd built something genuinely useful.
Moving Forward
Vector databases and RAG aren't just another tech trend — they fundamentally change how developers interact with code. The architecture we've built handles real queries like "how do we handle rate limiting" or "show me error handling patterns" with responses that would take hours of manual code archaeology.
The key is starting with a solid foundation: a clean chunking strategy, an appropriate embedding model, and a vector database that matches your scale. Then iterate based on real usage. The gap between a prototype and a production system lies in those optimizations driven by actual developer needs.
Your codebase holds institutional knowledge that traditional search can't unlock. Vector databases combined with RAG provide the key. The question isn't whether to implement this — it's how quickly you can get started.
Access the Complete Implementation
GitHub repository: https://github.com/dinesh-k-elumalai/rag-code-search-pipeline
The repository includes:
- Complete source code for all modules
- Production-ready scripts and CLI tools
- Comprehensive test suite
- Configuration examples and deployment guides
- Docker support and CI/CD pipelines
- Detailed documentation and API references
Star the repo, fork it, and adapt it for your needs. Contributions and feedback are welcome!
Opinions expressed by DZone contributors are their own.
Comments