Beyond Vector Databases: Integrating RAG as a First-Class Data Platform Workload
Architectural framework that integrates RAG deeply into enterprise data platforms through event-driven indexing, multi-layer hybrid retrieval, and governance by design.
Join the DZone community and get the full member experience.
Join For FreeRetrieval-augmented generation (RAG) has become critical for groundbreaking large language models (LLMs) in enterprise knowledge, yet more than half of them failed in production due to retrieval latency or data issues. The root cause isn’t the LLM or embedding model used in RAG; it is due to treating RAG as an add-on instead of an integrated RAG, where retrieval and generation evolve together.
The Production RAG Crisis
The Promise vs. Reality
RAG is supposed to enhance the accuracy and relevance of LLMs by retrieving relevant context, augmenting the prompt, and generating grounded answers. It is designed to mitigate hallucinations, one of the most significant challenges facing large language models.
In reality, over 50% of RAG implementations fail to scale up or meet the performance expectations. Common pitfalls include high retrieval latencies, stale data leading to outdated responses, poor relevance due to naive chunking and retrieval strategies, escalating costs from inefficient queries, and security gaps that expose sensitive information.
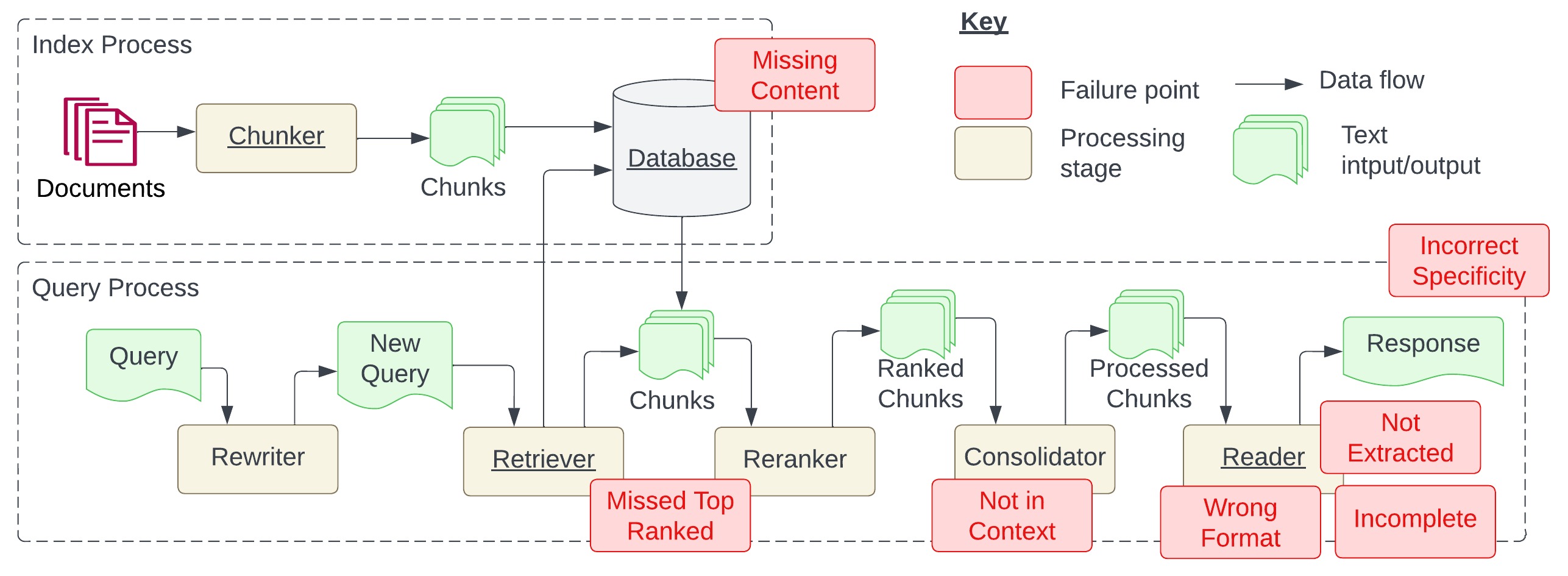
The indexing process is typically done at development time and queries at runtime. Failure points identified in this study are shown in red boxes. All required stages are underlined. This figure expanded from Zhu et al., 2023.
These occur due to fundamental architectural design where enterprises deploy RAG as a standalone and integrate a vector database onto existing data platforms without accounting for the complete lifecycle of data, like ingestion, transformation, retrieval, and governance.
This challenge grows with the exponential accumulation of unstructured petabytes of data. Ignoring data lifecycle management, RAG implementations often fail in production, resulting in lost investments and project abandonment.
The Symptom vs. The Disease
When RAG systems fail, teams typically respond by tuning vector database parameters, experimenting with embedding models, adjusting chunk sizes and overlap, or increasing retrieval depth. These measures may yield marginal improvements, but they address symptoms rather than the underlying disease: a standalone RAG component rather than an integrated data platform capability.
Retrieval Fabric framework architecture addresses these issues by embedding RAG as an integral component of enterprise data architecture, ensuring it operates with the same reliability, observability, and governance as traditional analytics workloads.
Vector Databases Aren't Enough
The predominant design pattern in RAG implementation is chunking documents, generating embeddings, and storing them in a vector database, querying these vector databases to retrieve chunks of data to pass to any LLM model as a datasource.
A major problem in this approach is that vector databases index the data for relevant search but don’t handle data quality , data lineage, or transactional consistency.
Gaps in the Vector Database: First Architecture Design
- Vector databases lacking integration with existing enterprise data do not automatically trigger re-indexing; it needs to be done by batch ETL (can take hours), resulting in returning outdated data.
- Vector search needs to perform hybrid retrieval by performing both exact match and structured querying based on input context, but this approach leads to maintaining parallel search systems, increasing operational complexity.
- Data governance can be a nightmare as row-level security from source doesn’t propagate to chunks, is unable to maintain compliance requirements, and leaks sensitive information in audit trails of vector retrievals.
- Vector searching will exponentially increase cost without caching of redundant queries and intelligent query routing.
- Traditional methods of data platform observability can’t be applied to RAG systems, which can be blind to the operations team about query performance metrics, data lineage, quality metrics, and cost attributions.
The Retrieval Fabric: Core Architecture
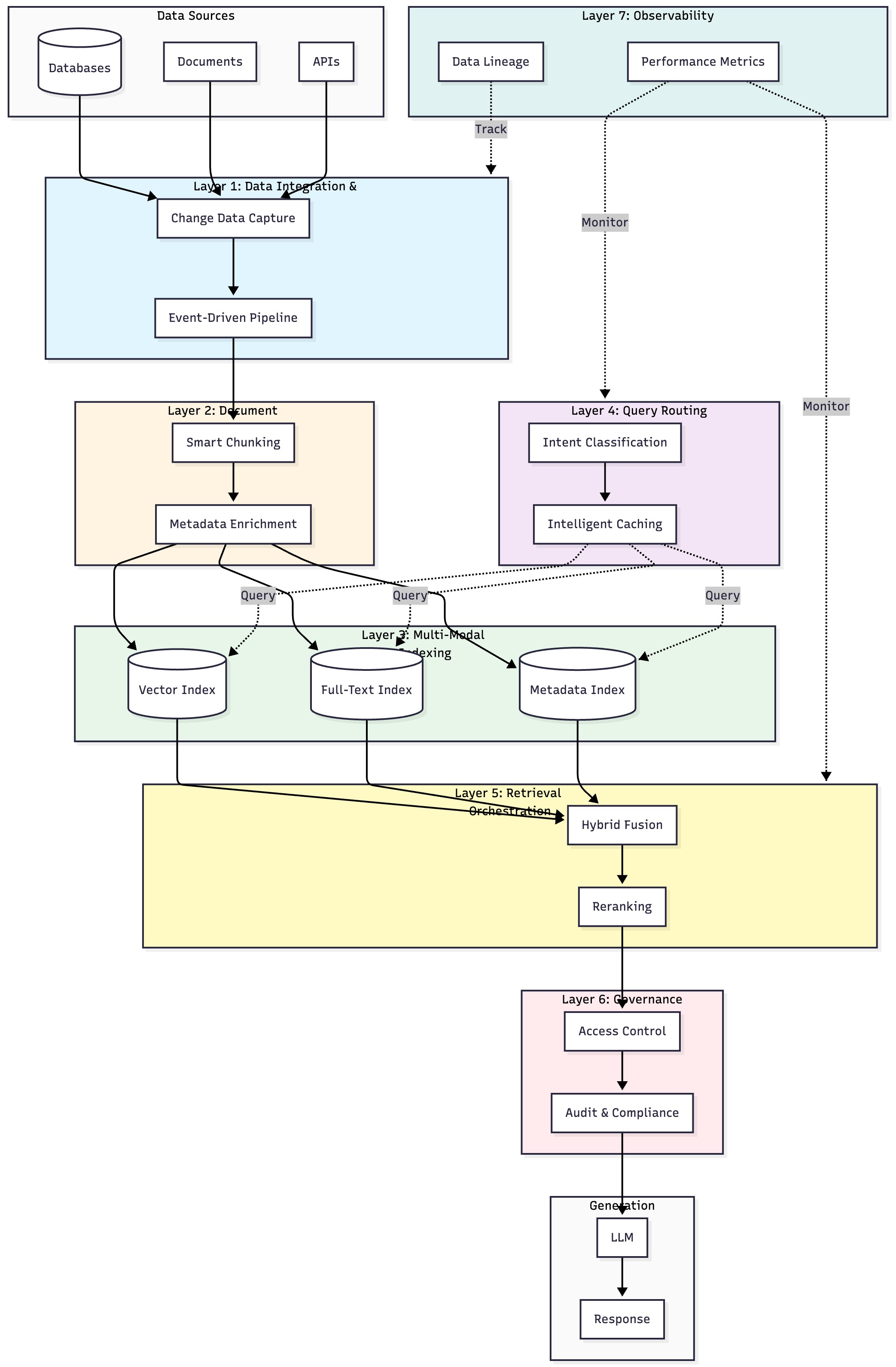
Seven Operational Patterns for RAG
1. Event-Driven Reindexing
Implement Change Data Capture (CDC) based incremental updates by monitoring source systems for insert, update, and delete events. Process these events through any queuing mechanism to rechunks, reembed, and reindex only affected documents and update the index atomically to maintain consistency.
2. Hybrid Retrieval With Reciprocal Rank Fusion
Implement a hybrid retrieval approach that combines exact-match precision and semantic understanding of dense embeddings. Fuse the results using Reciprocal Rank Fusion or learned fusion models and rerank the unified result set using cross-encoders.
3. Caching and Popular Queries With TTL Management
Cache the redundant queries at various levels, like query-level caching for identical searches, semantic caching for similar queries that map to the same document clusters, and document-level caching that persists embeddings across user sessions. Precompute popular queries to reduce the costs and improve latency.
4. Query-Dependent Retrieval Depth
Implement a query classifier to determine its complexity, and based on its complexity, dynamically adjust retrieval parameters .
5. Chunk-Level Access Control Propagation
Implement a governance pipeline that propagates access controls to the chunk level by extracting ACLs (users, groups, roles) from source documents during data ingestion, attaching security labels to each chunk during processing, and storing ACLs in the index alongside embeddings and metadata. During running queries, filter chunks based on the user's permissions before retrieval, and audit log all chunk accesses for compliance reporting.
Retrieval Lineage: Implement end-to-end data lineage tracking by tagging each retrieved chunk with source documentID, timestamp, and version, and send them as part of metadata to the LLM context window along with instructions to cite sources in responses. It helps users to verify the sources for their answers and can log full data lineage from the query to the answers in audit trails.
Feedback Loop: Implement a feedback mechanism for continuous improvement, such as using an LLM to provide a relevance score for retrieved context.
RAG as Data Platform DNA
The Retrieval Fabric framework demonstrates that RAG implementation requires rethinking system architecture from first principles. By treating retrieval as a first-class data platform workload with event-driven ingestion, hybrid indexing, chunk-level governance, and comprehensive observability, enterprises can overcome the limitations that plague vector-database-first approaches.
Without high-quality data, LLMs will mostly be garbage in and garbage out. All in all, the future of enterprise AI depends not on better LLMs alone, but on building robust data platform infrastructure with data as a strategic asset, with the same rigor applied to traditional data warehousing and analytics.
Opinions expressed by DZone contributors are their own.
Comments