The Vector Database Lie
Most teams don’t need vector databases. PostgreSQL + pgvector handles the majority of AI workloads with less complexity, lower cost, and comparable performance.
Join the DZone community and get the full member experience.
Join For FreeThe Setup: The Hype Machine
It’s vector database season. Conferences are full of RAG pipeline talks. Pinecone raised over $100 million; Milvus, Weaviate, and Qdrant are all well-funded and competing to disrupt how we store and search embeddings.
Let’s be blunt: The vector databases are poorly implemented, and most of the companies implementing them are doing so to solve a problem that doesn’t exist.
Core thesis: For the vast majority of use cases, PostgreSQL with pgvector is not just "good enough"; it's the objectively better choice. Vector databases are hammers. Most retrieval problems are not nails.
Why Vector DBs Exist (And Why You Might Not Need Them)
When vector databases were developed, the goal was very specific. They're designed to conduct similarity searches on billions of vectors with many dimensions. They use specialized indexing algorithms, such as HNSW, IVF, and PQ, optimized for nearest-neighbor search.
What marketing will not tell you is that this problem is small and only marginally represents their capabilities.

The Case for PostgreSQL + pgvector
Argument 1: It's Fast Enough (And Benchmarks Prove It)
This is the one that triggers vector DB advocates the most. Here's what the evidence shows:
- With 1M documents and 384-dimensional embeddings, pgvector with HNSW index returns 100 neighbors in ~15–30ms. Most applications consider this approach acceptable.
- In this context, and with users' eyes closed, Postgres latency = 12–18 ms, and Qdrant latency = 8ms. At production scale (<100 QPS), users perceive a latency difference of ~2x, not the ~100x advertised by developers.
- Throughput: Modern PostgreSQL can handle 50-200 QPS with proper indexing. Given the proper load, applications run in this range the majority of the time.
Argument 2: It's Free (They're Not)
Consider the total cost of ownership:
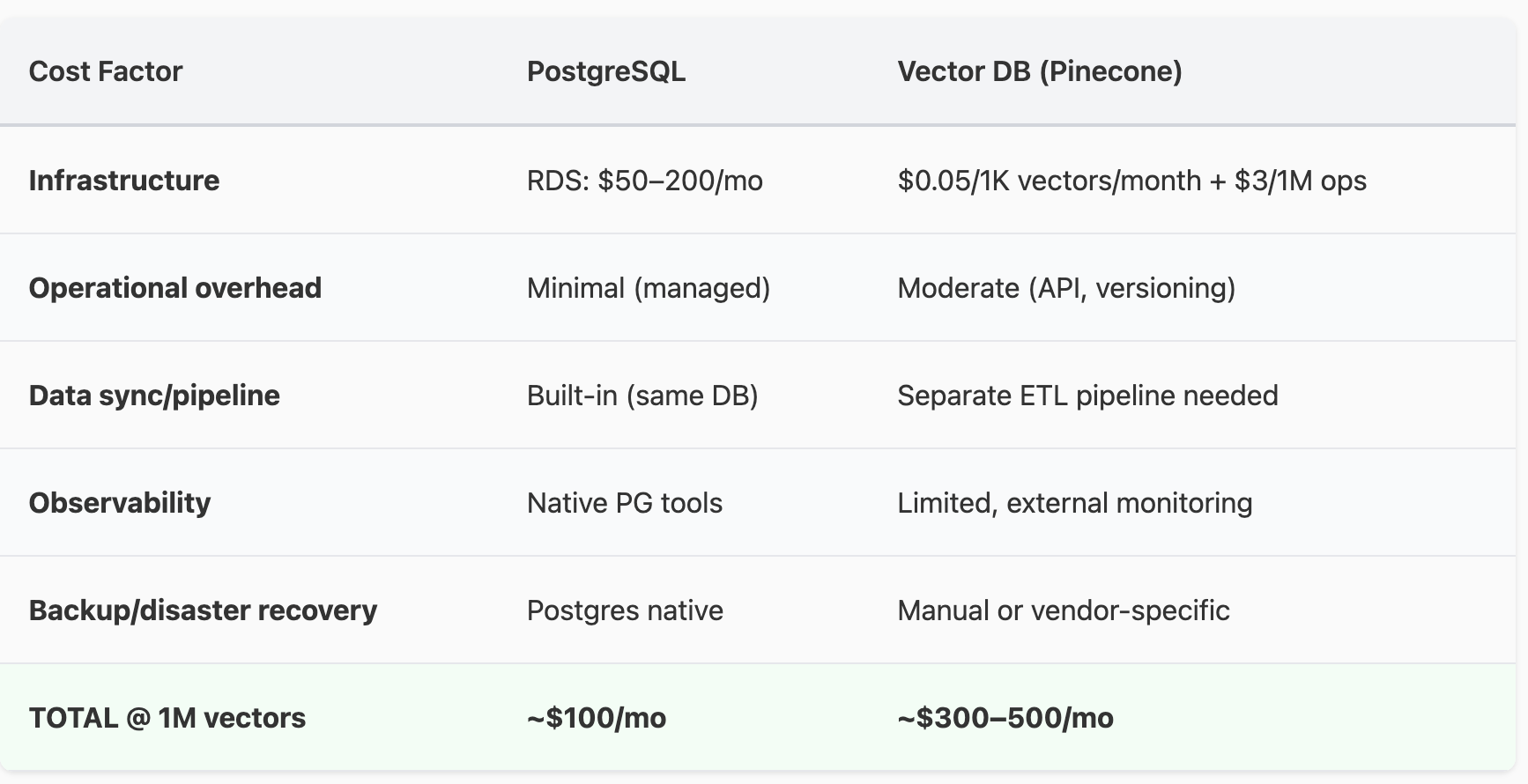
Considering the operational intricacies, your focus expands to managing two databases, two distinct models of security, two separate monitoring systems, and the complexity of data synchronization between them.
Argument 3: It's Simpler (The Abstraction Tax)
Here's what you get with PostgreSQL:
- You get to enjoy the advantages of having vectors and metadata in a single database without a synchronization headache.
- When it comes to ACID transactions, PostgreSQL will provide consistency guarantees that vector databases can’t.
- You already know the structured query language.
- You don’t need to worry about a separate filtering step after vector search, as filtering and search come together in one query.
- The same tools you already use will work for backup/restore, too.
Vector database advocates will argue, “But pgvector can’t scale to billions of vectors!” and that’s right. However, if you do have billions of vectors, you have already solved the initial problem of getting users in the door.
When Vector Databases Actually Win
There are real cases where a dedicated vector DB makes sense. They're just rarer than the marketing suggests.
Decision Tree: Vector DB vs. Postgres
1. Do you have well over 10 million vectors?
- If YES: It might be worth considering a dedicated vector database. Postgres with pgvector tends to be problematic with >50M vectors and complex queries.
- If NO: Continue to the next question.
2. Do you need a response time of less than 10ms at a throughput of more than 1,000 queries per second?
- If YES: It might be justified to optimize a vector database, and Postgres will not be able to meet this requirement.
- If NO: Continue to next question.
3. Is filtering by metadata less important than speed?
- If YES: It means that the vector database is likely to offer a cleaner design with a single table (no joins).
- If NO: Postgres is the better choice, as it will offer more complex filtering in SQL.
4. Are you willing to accept vendor lock-in?
- If YES: SaaS vector databases, like Pinecone, are more of a managed pain than a technical pain.
- If NO: Choose a self-hosted vector database or Postgres so that you retain your portability.
Result: Use PostgreSQL + pgvector
You answered NO to all or most of the questions. Your problem is not so specialized that you need a specialized tool, and you can start here.
Result: Consider a vector DB
You answered YES to at least two questions above. You should evaluate the performance of the new feature, but first, do a real benchmark against Postgres.
Real Use Cases That Actually Need Vector Databases
1. Semantic Search at Billion-Scale (e.g., Image Search, Global Document Corpus)
Example: You’re building a search engine across billions of Wikipedia articles, and you need sub-100 ms latency for interactive search. Postgres + pgvector can’t do this; Qdrant or Milvus can.
2. High-Frequency Real-Time Filtering by Both Vector + Metadata (Highly Specialized)
Example: Financial trading signals. You need to match real-time market data against embeddings of historical patterns at >1000 QPS with <10 ms latency and complex filtering. This is a niche. Most apps aren’t trading systems.
3. Low Latency, Stateless Serving (SaaS Multi-Tenant)
Example: You’re building a SaaS feature where every customer needs instant similarity search. The overhead of managing individual Postgres instances kills you. A shared, auto-scaling vector DB is cleaner.
4. Specialized Use Cases Where Vector DB-Native Tooling Provides a Real Advantage
Example: Hybrid search (BM25 + semantics) where you need native ranking/weighting. Weaviate does this better than Postgres out of the box.
The pattern? All of these involve either (a) truly massive scale, (b) very specific latency requirements, or (c) a business model where the infrastructure savings justify the operational complexity.
The Hidden Costs You Don't See Until It's Too Late
Complexity in infrastructure: Your responsibilities have increased to managing multiple databases. Each database has its unique problems. When one goes down, it becomes difficult to diagnose. And when they go out of alignment, it becomes even more difficult to manage and find the gap.
Burden of observability: Vector databases have the built-in pg_stat_statements and associated monitoring tools, which are more primitive relative to the monitoring tools that have been developed for vector databases. When a search is not returning the correct results, debugging and monitoring become complex tasks.
Syncing data nightmare: Ensuring the truth stored in PostgreSQL and the vector data in Pinecone are always up to date is a demanding task. Keeping track of data can be tedious, as it requires configuring and managing post-update notifications, synchronizing updated records, etc. In the end, it adds more complexity and failure modes to the existing systems.
Dependence on vendor: Once you've selected a vector database, evaluating and selecting an alternative to the other tools in your system eventually becomes a painful task. Overall, it locks you in, forcing you to pay the price of frequent changes to the product and the API with each new version.
Code: Postgres + pgvector Setup (Production-Ready)
1. Installing pgVector
-- In your database:
CREATE EXTENSION IF NOT EXISTS vector;
-- Create a documents table with embeddings
CREATE TABLE documents (
id BIGSERIAL PRIMARY KEY,
content TEXT NOT NULL,
embedding vector(384), -- Use your model's dimension
metadata JSONB,
created_at TIMESTAMPTZ DEFAULT NOW(),
updated_at TIMESTAMPTZ DEFAULT NOW()
);
-- Create an HNSW index for fast similarity search
CREATE INDEX ON documents USING hnsw (embedding vector_cosine_ops)
WITH (m=16, ef_construction=64);2. Query With Filtering (the Postgres Advantage)
-- Find top 10 semantically similar documents for user "alice"
SELECT
id,
content,
1 - (embedding <=> query_embedding) AS similarity
FROM documents
WHERE metadata->>'user_id' = 'alice'
ORDER BY embedding <=> query_embedding
LIMIT 10;3. Python Client for Production
import psycopg2
from pgvector.psycopg2 import register_vector
import numpy as np
# Register vector type
conn = psycopg2.connect("postgresql://user:pass@localhost/db")
register_vector(conn)
# Insert embeddings
embedding = np.random.rand(384).astype(np.float32)
cur = conn.cursor()
cur.execute(
"INSERT INTO documents (content, embedding, metadata) VALUES (%s, %s, %s)",
("Your text here", embedding, json.dumps({"user_id": "alice"}))
)
# Search
query_embedding = embed("search query")
cur.execute("""
SELECT id, content, 1 - (embedding <=> %s) AS similarity
FROM documents
WHERE metadata->>'user_id' = %s
ORDER BY embedding <=> %s
LIMIT 10
""", (query_embedding, "alice", query_embedding))
results = cur.fetchall()Production notes:
- For >1M embeddings, use
ef_search=40for balance between latency and accuracy. - Monitor index build time — HNSW construction is memory-intensive.
- Use connection pooling (PgBouncer, pgpool) to avoid connection storms.
- Test latency under your actual QPS load. HNSW performance degrades gracefully; SQL won't surprise you.
Benchmark: Real Numbers (Not Marketing)
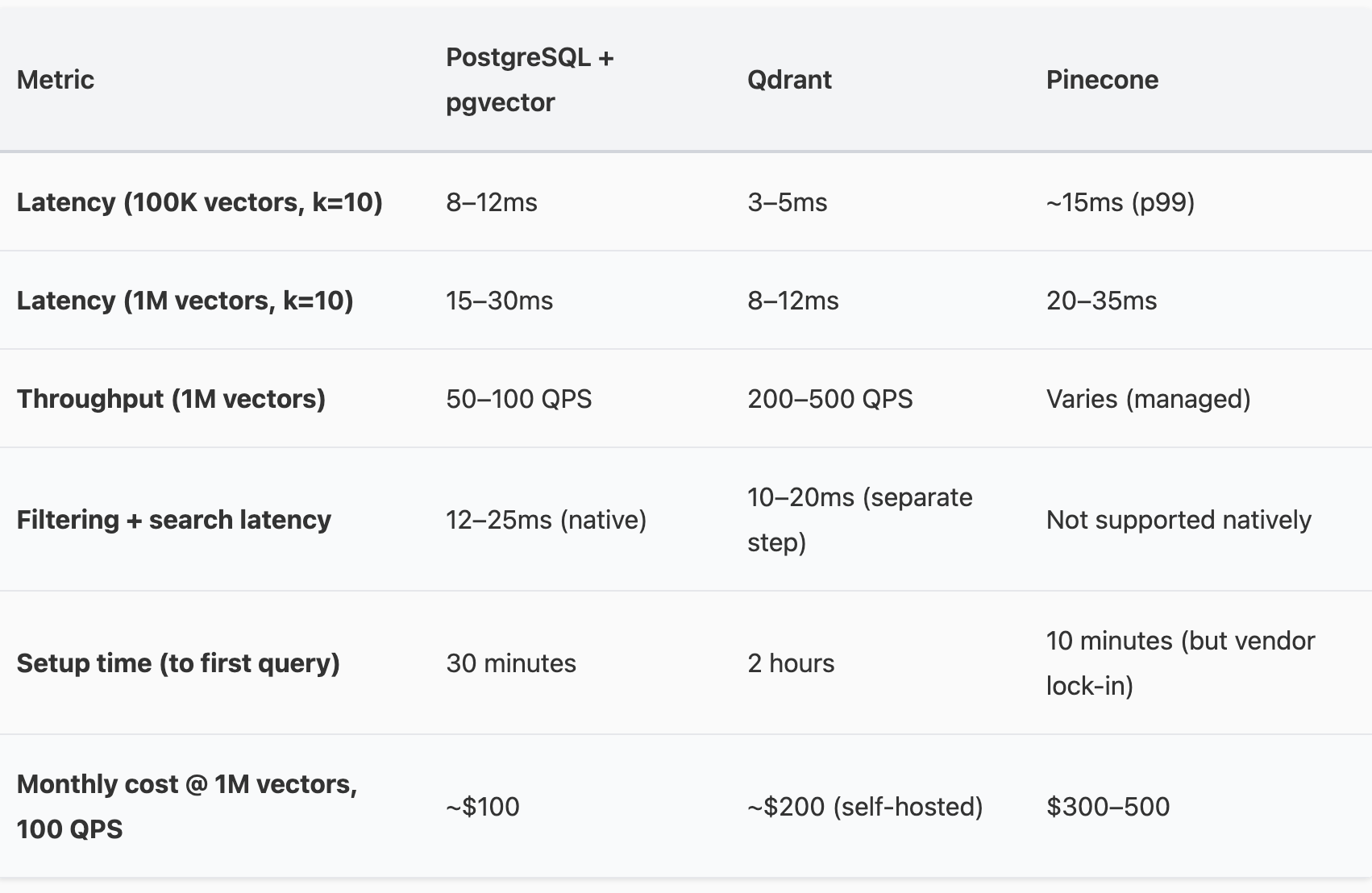
Caveats: Benchmarks are synthetic. The performance in practical scenarios varies. Factors include embedding dimension, query complexity, hardware, and data. Always benchmark using your actual workload.
Why The Hype? Follow The Money
Pinecone, Weaviate, and Qdrant are venture-backed. They need growth. Saying "use PostgreSQL" doesn't change growth metrics. Saying "you need specialized infrastructure for AI" does.
That's not an accusation; it's just incentives. VCs are betting on the generalist infrastructure play losing. Maybe they're right. But the burden of proof is on them, not on you. Meanwhile, PostgreSQL is run by a community. It has no financial incentive to oversell itself. It just... works.
Final Thoughts
What defines a decent vector database? Is it specialized? Is it the mass multitude of companies constructing RAG systems, certain types of chatbots, or certain types of search functionality systems?
What I see:
- A company invests in Pinecone and pays the bill because it seems technically advanced and deploys artificial intelligence features.
- Fast-forward six months, and come the difficulty of keeping systems in sync, the surprise bills, and the time it takes to respond, which is no better than using Postgres.
- They switch to Postgres. It is a weekend project and not a major rewrite.
Fewer steps will be involved if you just start with Postgres. One day, a true problem will confront you. It will be a billion vectors needing sub-5ms latency and multi-tenancy SaaS vectors. That is when you will be truly thankful for the vector DB.
The hammer is not evil. You need to make sure you have a nail before you pick one up.
Opinions expressed by DZone contributors are their own.
Comments