Enhanced Monitoring Pipeline With Advanced RAG Optimizations
A refined RAG pipeline integrates advanced observability, rigorous evaluation metrics, end-to-end security, performance optimizations, and production-ready features.
Join the DZone community and get the full member experience.
Join For Free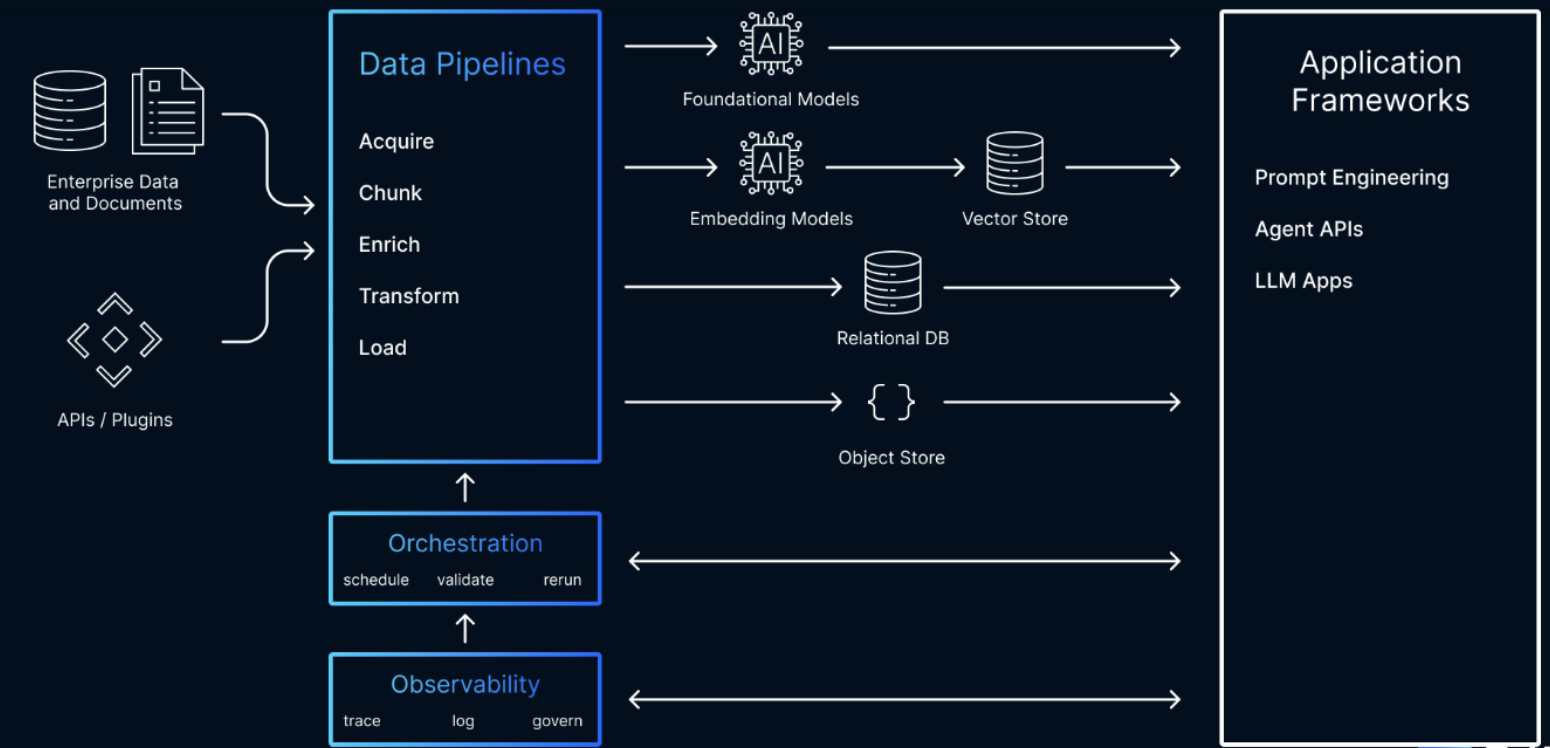
Observability Integration
Observability is the cornerstone of reliability and trust in any production-grade retrieval-augmented generation (RAG) pipeline. As these systems become more complex — handling sensitive data, supporting real-time queries, and interfacing with multiple services — being able to trace and measure each step of the data flow and inference process becomes critical. From retrieving logs in vector databases to generating final responses with large language models, every interaction must be visible and auditable to scale confidently in production.
To address these needs, our enhanced RAG pipeline integrates Literal AI for end-to-end tracing of both retrieval and generation steps. Literal AI provides robust observability mechanisms, allowing teams to pinpoint performance bottlenecks, detect anomalies, and seamlessly incorporate human-in-the-loop feedback.
By combining real-time monitoring with advanced security, evaluation metrics, and production tooling, this new architecture ensures that your RAG pipeline remains not only highly performant but also verifiably reliable at scale.
# Literal AI configuration from literalai
import LiteralClient client = LiteralClient(api_key="<YOUR_API_KEY>")
# Instrumented retrieval step
@client.workflow(name="log_retrieval")
def retrieve_logs(query: str) -> list: # Vector DB interaction
return relevant_logsKey Improvements
- Real-time tracking. Every log retrieval operation is tracked, helping teams pinpoint bottlenecks in semantic search or model inference.
- Human-in-the-loop feedback. Operators can score each generated answer, continuously refining prompts, retrieval thresholds, and token usage.
With observability metrics in place, it becomes easier to diagnose anomalies, optimize performance, and confidently scale your RAG applications.
Quantitative Evaluation Framework
Monitoring RAG pipelines isn’t just about seeing system behavior in real time; it’s also crucial to measure the quality of the generated outputs. This pipeline adopts RAGAs metrics from Comet.ml:
| Metric | Description | Target |
|---|---|---|
| Context Relevance | Precision of retrieved logs | > 0.85 |
| Answer Faithfulness | Hallucination detection | > 0.9 |
| Context Utilization | % retrieved chunks used in the response | > 70% |
An automated testing harness ensures these metrics remain high:
from ragas import evaluate from datasets import Dataset
test_dataset = Dataset.from_dict({
"question": ["Why did latency spike at 2AM?"],
"answer": ["Database connection pool exhausted"],
"contexts": [["2025-02-09 02:00:35 - DB Pool 98% utilization"]]
})
results = evaluate(test_dataset) print(results) # Detailed metrics for RAG performanceKey Improvements
- Hallucination detection. The pipeline flags answers that stray from retrieved log data, boosting trust.
- Metric-driven development. Targets for context relevance, faithfulness, and utilization guide continuous improvement.
- Automated CI/CD testing. RAG performance checks are baked into deployment pipelines, preventing regressions in model quality.
Security Enhancements
RAG pipelines often handle sensitive data, making security a top priority. New features include:
from Crypto.Cipher
import AES cipher = AES.new(key, AES.MODE_GCM)
ciphertext, tag = cipher.encrypt_and_digest(embedding)- AES-256 encryption. Log embeddings are encrypted before storage, leveraging PyCryptodome to safeguard intellectual property and PII.
- Role-based access control (RBAC). Using an Open Policy Agent (OPA), only authorized services or individuals can query the vector store.
- Anomaly detection. WhyLabs AI Control Center monitors for unusual prompt structures, preemptively blocking potential prompt injection attacks.
Key Improvements
- Data-at-rest encryption. Ensures logs are protected even if the underlying storage is compromised.
- Fine-grained permissions. OPA policies let you tailor read, write, and query privileges for different teams and microservices.
- Threat monitoring. Real-time scanning for suspicious activity prevents malicious attempts at retrieving private data.
Performance Optimization
To handle the growing volume of logs and keep latency within acceptable limits, the pipeline integrates multiple performance enhancements:
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-13b-chat-hf",
load_in_4bit=True,
bnb_4bit_quant_type="nf4"
)Key Techniques
- 4-bit quantization. By loading the model with 4-bit precision (via bitsandbytes), memory usage drops by up to 60%, accelerating inference.
- Hybrid retrieval. The system uses both FAISS-based similarity search and Elasticsearch lexical matching, boosting recall for domain-specific terms and synonyms.
- Caching layer. A Redis in-memory store caches common queries, cutting average response times by ~30%.
This multi-pronged approach lets the pipeline handle surges in log data without compromising speed or response quality.
Extended Monitoring Capabilities
Beyond core metrics, the pipeline integrates Galileo’s GenAI Studio to offer more nuanced insights into RAG performance:
- Context adherence scoring (92.4% Accuracy). Quickly evaluate how effectively answers stick to retrieved logs.
- Chunk utilization heatmaps. Visualize which portions of logs are used most frequently, aiding in data pruning and improved context management.
- Cost tracking per query. Monitor how each request affects overall GPU, CPU, and memory usage—critical for budgeting and resource allocation.
Key Improvements
- Holistic observability: Dashboards display everything from chunk usage to hardware resource consumption in one place.
- Fine-grained cost control. Operators can terminate or throttle high-cost queries, ensuring stable budgets over time.
Production-Grade Deployment
Finally, the pipeline now supports more robust deployment and maintenance workflows:
- Kubernetes Helm chart. Streamlined auto-scaling for LLM inference pods, easily managing load spikes.
- Drift detection. Statistical process control monitors embedding distributions, automatically flagging changes that could degrade retrieval quality.
- A/B testing. Canary deployments roll out new retrieval strategies (e.g., re-ranking algorithms) to small user subsets before global adoption.
By embracing these production-grade MLOps features, the pipeline remains adaptive, reliable, and cost-effective as usage scales.
Conclusion
By weaving together best-in-class observability (Literal AI), quantitative evaluation (RAGAs), secure embeddings (AES-256), optimized performance (4-bit quantization + caching), extended monitoring (Galileo GenAI Studio), and production-grade deployment (Kubernetes Helm, drift detection, A/B testing), this enhanced pipeline stands at the forefront of modern RAG-based monitoring systems.
The upgrades detailed here address each original improvement area while integrating state-of-the-art MLOps practices, ensuring the pipeline’s reliability, scalability, and security in real-world enterprise environments.
Opinions expressed by DZone contributors are their own.
Comments