Beyond Code Coverage: A Risk-Driven Revolution in Software Testing With Machine Learning
Machine learning-driven, risk-based testing targets critical risks, automates test selection, and improves software reliability.
Join the DZone community and get the full member experience.
Join For FreeModern systems require more than high code coverage because they are complex and interconnected. Through machine learning development, companies can create advanced tools that link risk-based planning methods to enhance their software testing outcomes.
With the focus on the possibility of failure and its effects, risk-based testing provides both improved efficiency and better effectiveness. RBT selects its execution focus on core features and often modified code and components known for producing defects.
Risk-based testing requires intelligent priority selections to function effectively, as 75-90% of crucial errors can be found through 10-15% of tested cases (Reichert, 2025b).
This approach enables testing resources to reach their best utilization point simultaneously with early flaw discovery throughout the development life cycle.
In this article, we’ll explore 3 core points:
-
how risk-based prioritization delivers results,
-
he inadequacies of code coverage, and
-
how ML functions as the hidden ingredient in fault detection before production.
Why Is Code Coverage Alone Not Enough?
Traditional coverage-based testing prioritizes the execution of code under test across different areas. While excellent code coverage demonstrates thorough testing, it sometimes produces misinformed security feelings because code execution verification exists only to detect code bugs and execute expected program pathways.
The absence of risk knowledge in code coverage measurements results in the treatment of all codebase sections identically, regardless of their impact on business failure.
The testing intensity of payment processing components must exceed the testing level for seldom-used user interface parameters, although coverage-based approaches provide no distinction between these features.
Testing resources get wasted because they are applied excessively to components that show low risk and stability, leading to longer testing times and decreased computing power usage.
The failure demonstrates that a risk-based testing strategy for prioritization is necessary because coverage metrics become ineffective when measuring test effectiveness.
Why Risk-Based Testing Is a Smarter Approach
Risk-based testing measures the importance of criteria instead of conducting equal checks for every factor. It evaluates potential flaws based on failure impact, likelihood of failure, and business criticality. This approach ensures efficient resource management and improves software reliability by:
-
Focusing on Critical Areas: Instead of testing everything equally, RBT ensures that high-risk components receive the most attention.
-
Evaluating Failure Impact: Identifies and tests areas where defects could cause significant damage.
-
Assessing Likelihood of Failure: Targets unstable parts of the software by analyzing complexity, frequent changes, and past defects.
-
Prioritizing Business-Critical Functions: Ensures essential systems like payment processing remain stable and reliable.
-
Optimizing Resources and Time: Reduces unnecessary testing efforts, allowing teams to focus on what matters most.
-
Improving Software Dependability: Detects major issues early, leading to more stable and reliable software.
Essential Components of Risk-Based Testing
Risk-based testing includes various components:
-
Risk Identification: RBT starts with identifying potential risks inside the software. Analyzing requirements, design documentation, and past data helps identify areas that, if improperly tested, can cause major problems.
-
Risk Assessment: Once risks are found, they have to be evaluated depending on their possibility of occurrence and possible influence. Often, this assessment uses risk matrices or heat maps to display and classify hazards.
-
Risk Prioritization: Risks are ranked according to their degree of seriousness and probability. First addressed are high-priority risks with excellent possibility of occurrence and major possible impact.
-
Test Planning and Execution: Testing plans and execution are created with an eye toward high-risk areas. This entails creating thorough test cases across various possibilities, including possible failure situations and edge cases.
What is a Risk Matrix?
A risk matrix is a useful tool for graphically showing the probability and influence of potential risks. Usually, a grid with one axis indicates the likelihood of an event, and the other axis shows the possible influence the event could have on the project.
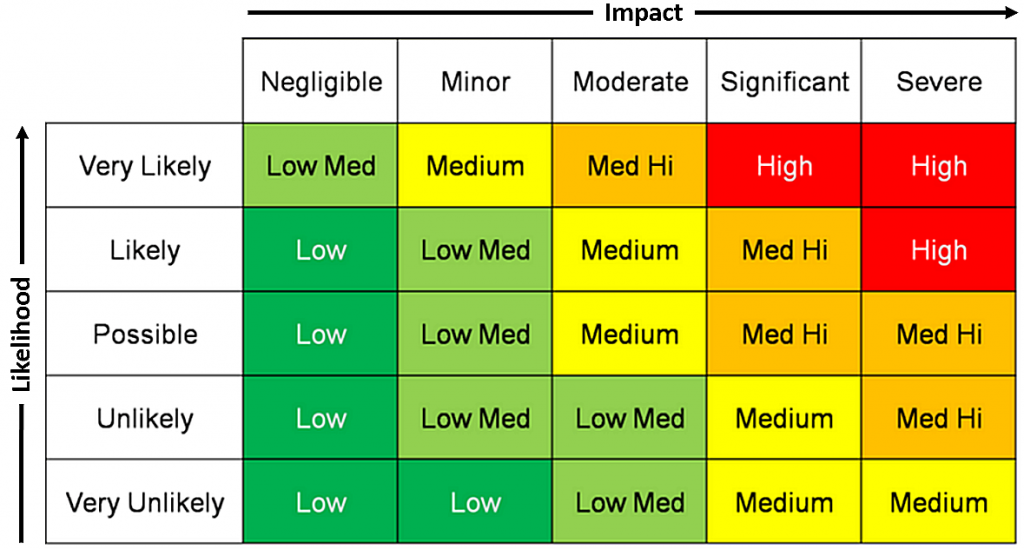
It shows different zones or risk levels that split the matrix.
The Role of Machine Learning in Identifying High-Risk Areas
Machine learning improves software testing by examining prior data (code changes, bug reports, and test results) to identify high-risk locations. It gives key tests top priority; it finds anomalies before failures start; it keeps getting better with fresh data.
Automating risk assessment helps ML speed tests, improve accuracy, maximize resources, and make software testing smarter and more effective.
Integrating Machine Learning into Risk-Based Testing
Through automating and optimizing numerous aspects of the testing process, machine learning can greatly improve the accuracy of RBT:
-
ML models can evaluate real-time inputs and past data to more precisely estimate hazards' probability and possible influence. More educated risk prioritizing is made possible by this predictive capacity.
-
ML techniques can create test cases depending on the found hazards, guaranteeing complete testing of high-risk locations. Automation lessens the time and effort needed for hand test case development.
-
ML models can dynamically modify test priorities to guarantee that the most important regions are handled first as new code changes occur. In agile development settings where needs often evolve, this adaptability is vital.
-
High-risk locations and automated test case development allow ML-powered RBT to help maximize testing resources. This guarantees that initiatives for testing focus where they are most required, enhancing the general testing effectiveness.
ML Models and Techniques for Test Prioritization
Modern ML-driven test prioritizing depends on many modeling techniques, each appropriate for different aspects of the problem.
With hybrid approaches also under investigation, these methods can be generally separated into supervised, reinforcement, and unsupervised learning.
Supervised Learning to Predict Failure
Supervised learning models forecast which tests or code modifications will likely fail based on historical data, including test executions, issue reports, and code changes.
Based on their probability of defect detection, algorithms ranging from decision trees to random forests to gradient-boosting machines and neural networks help score tests.
For example, a model built on past data may forecast that some tests are more failure-prone and thus run first.
Running just 0.2% of the test suite allows ML models to detect 50% of test failures (Busjaeger & Xie, 2016), significantly improving efficiency over conventional coverage-based testing.
Reinforcement Learning for Adaptive Test Scheduling
Test scheduling is seen by reinforcement learning as a dynamic decision-making process. Learning from past test results, an RL agent adapts to give tests that routinely find defects top priority while skipping those that hardly fail priority.
It evolves an ideal testing plan by optimizing defect detection rates and reducing execution time. Successful deployment of RL-based models in continuous integration systems has resulted in better problem detection rates and fewer needless test runs.
Unsupervised Learning with Anomaly Detection
Without labeled failure data, unsupervised learning finds latent risk patterns. By grouping related test cases, clustering techniques serve to lower duplicate testing while preserving general coverage.
Anomaly detection models use production telemetry, such as error rates and system performance indicators, to identify abnormal behavior that could signal untested failure situations. This guarantees the early catching of developing hazards, even in cases of limited historical defect data.
Implementing ML-Powered RBT in Practice
RBT driven by ML demands careful integration with current systems. Teams must first gather past data on flaws, test outcomes, and software for teaching ML models. Create and improve models, then prioritize test cases and projected risks.
These models ought then to be combined with seamless automation testing techniques. Last but not least, constant observation and feedback help increase accuracy, guaranteeing that the system adjusts to changing software risks.
While machine learning can greatly enhance testing, it’s important to consider ethical and practical limitations. Blindly relying on an ML model for quality assurance can be risky if not checked.
Conclusion
Machine learning-driven risk-based testing improves software quality by focusing on high-risk areas and automating test case choosing. Adopting ML-powered RBT guarantees early defect identification, optimal testing resources, and better efficiency as software complexity increases.
Therefore, it is important for modern development settings.
References
Reichert, A. E. (2025b, April 9). A Data-Driven Approach to Test Case Prioritization: The role of Analytics. LambdaTest. https://www.lambdatest.com/blog/the-role-of-analytics-in-test-case-prioritization/
ARMS Reliability: Beyond the risk matrix. (n.d.). https://www.armsreliability.com/page/resources/blog/beyond-the-risk-matrix
Busjaeger, B., & Xie, T. (2016). Learning for test prioritization: an industrial case study. In FSE 2016: Proceedings of the 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering. https://doi.org/10.1145/2950290.2983954
Opinions expressed by DZone contributors are their own.
Comments