Enhancing Avro With Semantic Metadata Using Logical Types
Avro logical types add semantic meaning to primitive data types, making schemas more expressive. This blog explores their benefits and common use cases.
Join the DZone community and get the full member experience.
Join For FreeApache Avro is a widely used data format that keeps things compact and efficient while making it easy to evolve schemas over time. By default, it comes with basic data types like int, long, string, and bytes. But what if you need to store something more specific, like a date or a decimal number? That’s where logical types come in.
Logical types let you add semantic meaning to your data. They ensure that values like timestamps or IP addresses are interpreted correctly while still benefiting from Avro’s optimized encoding. We’ll also take a deep dive into a specific use case and how logical types can enhance data security by enforcing structured storage and interpretation of sensitive information.
Example Use Case
Let’s consider a customer record that contains Personally Identifiable Information (PII), such as an email address and a customer account number. Since this data is sensitive, our approach is to mask the username portion of the email address before storing it and encode the customer account number for added security.
When retrieving the data, the system will decode the account number to restore its original value. There are various reasons for encoding customer account numbers. Here are a few of those:
- Most of the time, IDs are generated using an auto-increment key, so it is easy to know the growth of the system.
- Also, knowing the IDs of two users makes it easy to determine which user was created in the system first.
- Simply, when data is persisted in a third-party system, it makes sense to hide the actual internal IDs.
![Data Representation at Rest]()
The Algorithm for Obfuscating Account Id

To obfuscate or lightly encode an account number (or any numeric field), we’ll use a neat little trick called the modular multiplicative inverse.
The Idea
We want to take a number, transform it in a reversible way, and get it back later — kind of like scrambling and unscrambling.
Let’s say the field we want to encode can have values from 0 to 255.
Step-by-Step
- Pick a modulus M, which should be one more than the maximum value the field can hold.
In this case, since the max is 255, we choose M = 256. - Pick a number P that’s coprime with M (i.e., they share no common factors except 1).
Let’s go with P = 9. - Now, find the modular inverse of P - a number Q such that P × Q ≡ 1 (mod M).
In simpler terms, we want some number that, when multiplied by 9 and taken modulo 256, gives 1.
Using an online calculator or doing a bit of math, we find Q = 57.
The modulo operation guarantees that the output will always stay within the range 0 to M - 1, ensuring it never goes out of bounds.
Now, we’re ready to encode and decode.
To encode:
encoded_value = (original_value * P) % MThe encoded value for the original value 195 would be 219.
To decode:
original_value = (encoded_value * Q) % MThe original value can be restored now using the above logic.
This method is simple, fast, and easily reversible — perfect for lightweight obfuscation where you don’t need full-blown encryption.
Actual Implementation Using Avro Logical Types
Step 1
Define the Avro Record for UserProfile and annotate the record with annotation @logicalType.
@namespace("com.example.avro.customer")
protocol Customer {
record UserProfile {
long id;
@logicalType("accountId") long accountId;
@logicalType("email") string userEmail;
}
}Step 2
Define the logical type for the account ID.
package org.example.customtypes;
import org.apache.avro.LogicalType;
import org.apache.avro.LogicalTypes;
import org.apache.avro.Schema;
public class AccountIdLogicalType extends LogicalType {
public static final String ACCOUNT_ID_LOGICAL_TYPE_NAME = "accountId";
public static class TypeFactory implements LogicalTypes.LogicalTypeFactory {
private final LogicalType accountIdLogicalType = new AccountIdLogicalType();
@Override
public LogicalType fromSchema(Schema schema) {
return accountIdLogicalType;
}
@Override
public String getTypeName() {
return accountIdLogicalType.getName();
}
}
public AccountIdLogicalType() {
super(ACCOUNT_ID_LOGICAL_TYPE_NAME);
}
public void validate(Schema schema) {
super.validate(schema);
if (schema.getType() != Schema.Type.LONG) {
throw new IllegalArgumentException("Logical type 'accountId' must be long");
}
}
}Step 3
Write the custom conversion logic for encoding/decoding the account ID.
Here, M is 9223372036854775808, which is Long.MAX_VALUE + 1, and the chosen value of P is 64185959, and Q is computed using an online calculator, which comes to be 1703179806106473815.
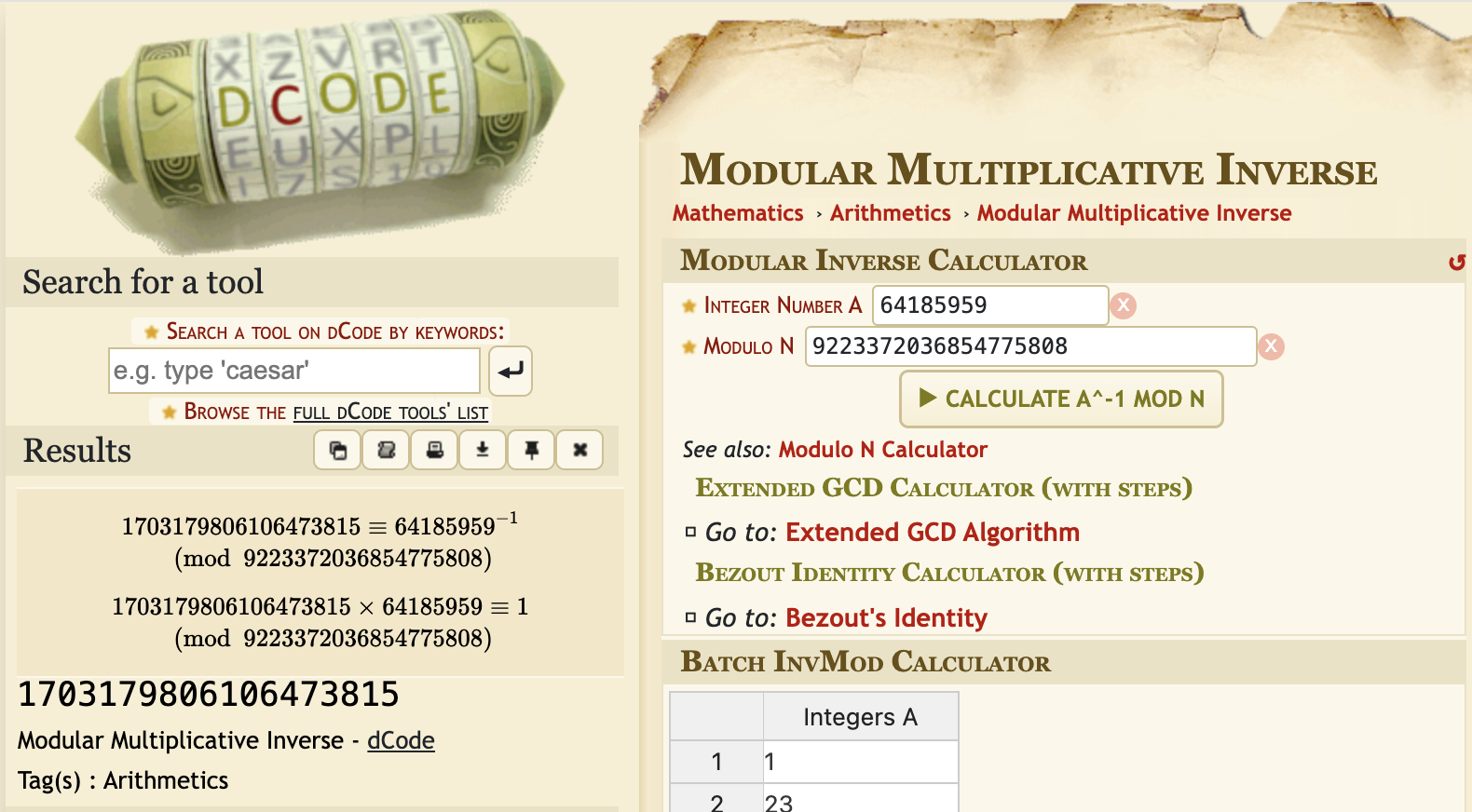
package org.example.customtypes;
import org.apache.avro.Conversion;
import org.apache.avro.LogicalType;
import org.apache.avro.Schema;
public class AccountIdConversion extends Conversion<Long> {
private static final long PRIME_NUMBER = 64185959L;
private static final long PRIME_NUMBER_INVERSE = 1703179806106473815L;
private static final AccountIdConversion INSTANCE = new AccountIdConversion();
private static AccountIdConversion get() { return INSTANCE; }
public AccountIdConversion() { super(); }
@Override
public Class<Long> getConvertedType() {
return Long.class;
}
@Override
public String getLogicalTypeName() {
return AccountIdLogicalType.ACCOUNT_ID_LOGICAL_TYPE_NAME;
}
@Override
public Long fromLong(Long value, Schema schema, LogicalType type) {
return (value * PRIME_NUMBER_INVERSE) & Long.MAX_VALUE;
}
@Override
public Long toLong(Long value, Schema schema, LogicalType type) {
return (value * PRIME_NUMBER) & Long.MAX_VALUE;
}
}Note: In this implementation, we’re using bitwise arithmetic to compute the modulus. When M is a power of 2, the operation x % 2^n can be efficiently calculated as x & (2^n - 1). In our case, M = Long.MAX_VALUE + 1, which equals 2^63, so this optimization applies.
Step 4
This is the final code for testing. It simply creates an Avro record for UserProfile, writes it to a local file, reads the file again, and prints the record.
package org.example;
import com.example.avro.customer.UserProfile;
import org.apache.avro.LogicalTypes;
import org.apache.avro.file.DataFileReader;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.io.DatumReader;
import org.apache.avro.io.DatumWriter;
import org.apache.avro.specific.SpecificDatumReader;
import org.apache.avro.specific.SpecificDatumWriter;
import org.example.customtypes.AccountIdLogicalType;
import org.example.customtypes.EmailLogicalType;
import java.io.File;
import java.io.IOException;
public class LogicalTypeExample {
public static void main(String[] args) {
LogicalTypes.register(EmailLogicalType.EMAIL_LOGICAL_TYPE_NAME, new EmailLogicalType.TypeFactory());
LogicalTypes.register(AccountIdLogicalType.ACCOUNT_ID_LOGICAL_TYPE_NAME, new AccountIdLogicalType.TypeFactory());
UserProfile testUserProfile = UserProfile.newBuilder()
.setId(100)
.setUserEmail("[email protected]")
.setAccountId(23L)
.build();
final DatumWriter<UserProfile> userProfileDatumWriter = new SpecificDatumWriter<>(UserProfile.class);
File f = new File("query.avro");
try (DataFileWriter<UserProfile> dataFileWriter = new DataFileWriter<>(userProfileDatumWriter)) {
dataFileWriter.create(testUserProfile.getSchema(), f);
dataFileWriter.append(testUserProfile);
} catch (IOException e) {
throw new RuntimeException(e);
}
System.out.println("Written to " + f.getAbsolutePath());
final DatumReader<UserProfile> userProfileDatumReader = new SpecificDatumReader<>(UserProfile.class);
try (DataFileReader<UserProfile> userProfileDataFileReader = new DataFileReader<>(f, userProfileDatumReader)) {
while (userProfileDataFileReader.hasNext()) {
UserProfile record = userProfileDataFileReader.next();
System.out.println("Id : " + record.getId());
System.out.println("Email : " + record.getUserEmail());
System.out.println("AccountId : " + record.getAccountId());
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}System Output
Please note that the output is similar to the original Avro Record. The email is masked, and the AccountId is the same as the original.
Written to /Users/gurmeetsaran/Documents/repo/avro_types/query.avro
Id : 100
Email : ******@gmail.com
AccountId : 23
Process finished with exit code 0Step 5
Inspect the data using avro-tools.
Here, the persisted data stores encoded value of the accountId and userEmail is also masked.
$ avro-tools tojson query.avro
25/04/07 13:26:27 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
{"id":100,"accountId":1476277057,"userEmail":"******@gmail.com"}
To check the complete implementation, please check my Github page.
Final Thoughts
Avro logical types are a great way to add semantic meaning to your data, making it easier to interpret and work with across different parts of your system. Instead of just dealing with raw primitives like strings or longs, logical types let you define what the data actually represents, whether it's a timestamp, a decimal, a UUID, or something custom.
One of the biggest advantages is consistency. By using logical types, you can ensure that fields of the same kind — like email addresses or account IDs — are treated the same way throughout your system. This means less boilerplate code, fewer one-off transformations, and a more maintainable schema.
In our example, we can standardize how we handle email fields and obfuscated account IDs simply by tagging them with the right logical type annotations. Once that’s in place, all the serialization, deserialization, and even validation logic can follow a common, reusable pattern - which is especially helpful when working at scale or across teams.
Opinions expressed by DZone contributors are their own.
Comments