Event Sourcing/Event Logging — An Essential Microservice Pattern
Learn how to add visibility to your microservices with event sourcing/event logging and see how it works in this post.
Join the DZone community and get the full member experience.
Join For FreeAs I mentioned in my previous post about how to fail with microservices, debugging a distributed system is a challenging task. Many things can wrong, and some of them are out of our control, such as network instability, temporary unavailability, or even external bugs.
Monitoring the network can be quickly addressed with plenty of tools out there, like a Service Mesh for instance, and you can additionally use tools like OpenTracing for distributed logging. However, when we talk about understanding the state of our entities, there is no quick plug-and-play framework.
Your data will potentially outlive your code, and yet we overlook how our data evolves over time. In most of the systems, even simple questions like "how did this entity reach this state?" or "how was my state a month ago?" are impossible to answer as no history of changes has been saved. Keeping track of those changes is crucial for a healthy system, not just for security or debugging purposes, but because of its vast business value (your Product Owner will be glad).
The Solution
An excellent way to add visibility to what is happening to your service is through Event Sourcing | Event Logging. The fundamental concept behind this 10-year-old pattern is that every change to the state of an application should be encapsulated in an event object and stored sequentially. If this sounds familiar to you, it might be because any version of control systems or database transaction logs is a heavy user of this pattern.
But let's dive deeper to understand how it works. Assuming we are building an Order Service for an e-commerce, let's see how our application state and events would look like:
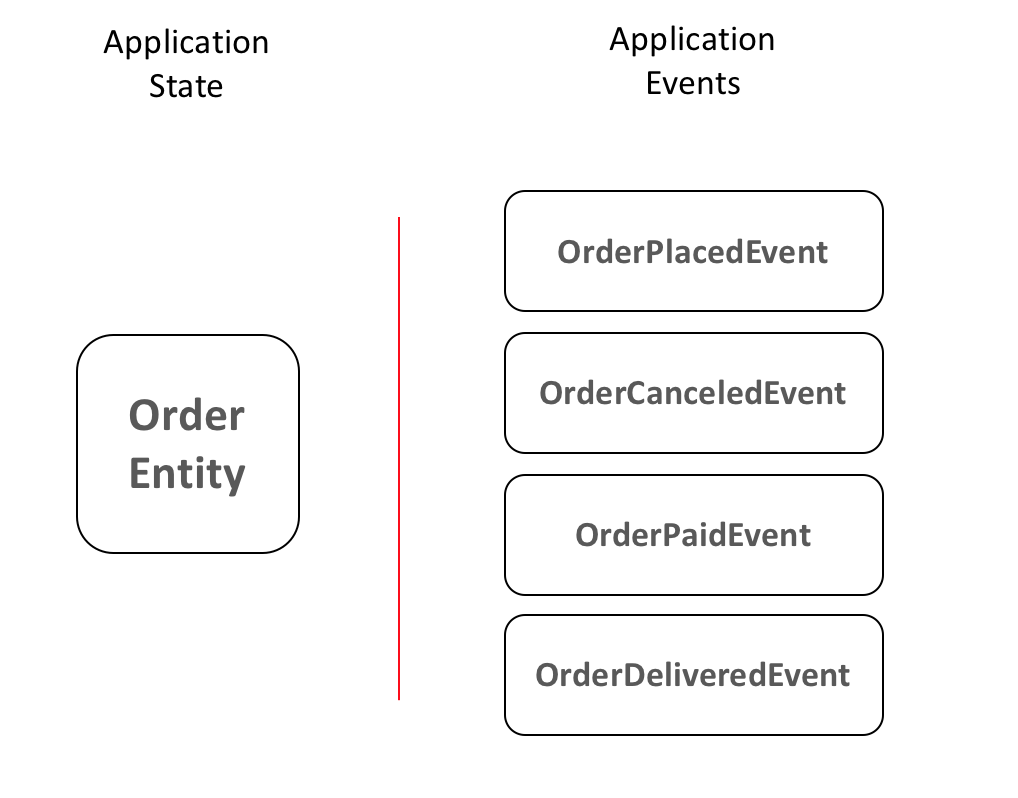
Many authors define three main rules for event sourcing/logging system:
- Events are always Immutable;
- Events are always something that has happened in the past. Some developers mistake commands (ex: PlaceOrder) with events (ex: OrderPlaced)
- Theoretically, at any point in time, you can drop your current state and rebuild the whole system by just reprocessing all the messages received.
Another nice thing about this pattern it that it pushes you to think about the events of your system before thinking about how the actual structure will look like. It might be counter-intuitive at first, as we have learned how to design a system by drawing entities and properties, but it is well aligned with another common DDD recommendation: thinking about how your services will communicate with each other first to easily identify domains.
Event Sourcing | Event Logging Flow
The most common flow for event sourcing is similar to the following:
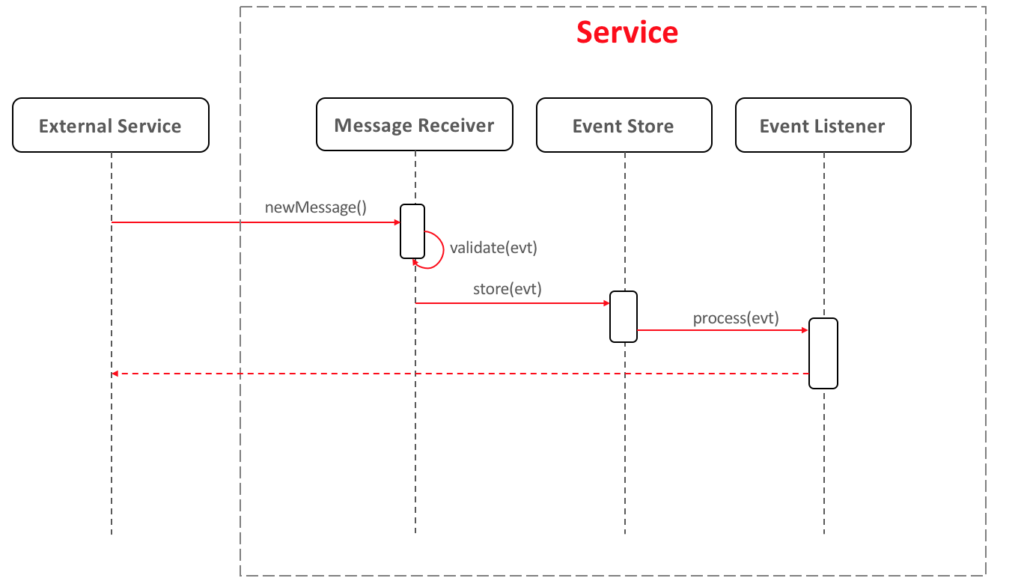
- Message Receiver is responsible for converting the incoming request into an event and validating it.
- Event Store is responsible for storing the events sequentially and notifying the listeners.
- Event Listener: As you might guess, this is the code in-charge of executing the respective business logic according to each event type.
There are many possible implementations of this pattern, one of which is by using the Eventing Service, introduced in Couchbase 5.5. In summary, it allows you to write functions that are triggered whenever a document is inserted/updated/deleted. The eventing mechanism also lets you make requests, so whenever a given document is stored in the database, you can trigger an endpoint in your application to process it. Let's see how it would look like using eventing:
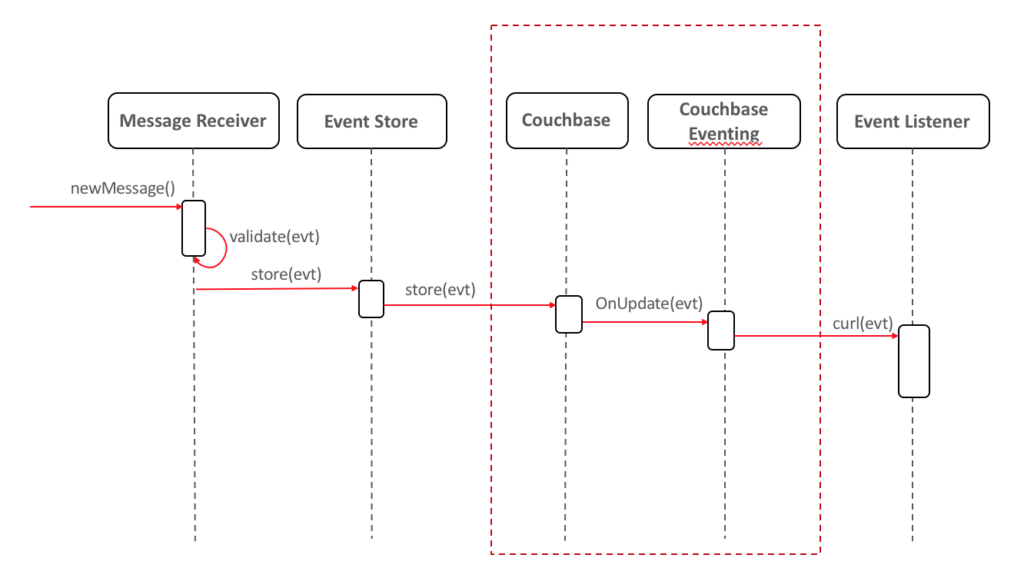
If you want to read more about it, check out the Couchbase eventing official documentation.
Couchbase Eventing is asynchronous, so the implementation above suits you only if your application receives just asynchronous calls. It can also act as an extra layer of security to trigger a notification, for instance, if someone tries to update an event manually.
In some systems, the event's fields and structure might differ quite significantly from each other, and the fixed structure of RDBM's makes the event store difficult to model. For that reason, developers usually store their events as a JSON String into a varchar field. This approach has a major issue: It makes your events difficult to find as most of your queries will be slow, complicated and full of ' likes'. One of the possible solutions for that is to use document databases as most of them store documents as JSON and have proper SQL-like language for querying it, like N1QL.
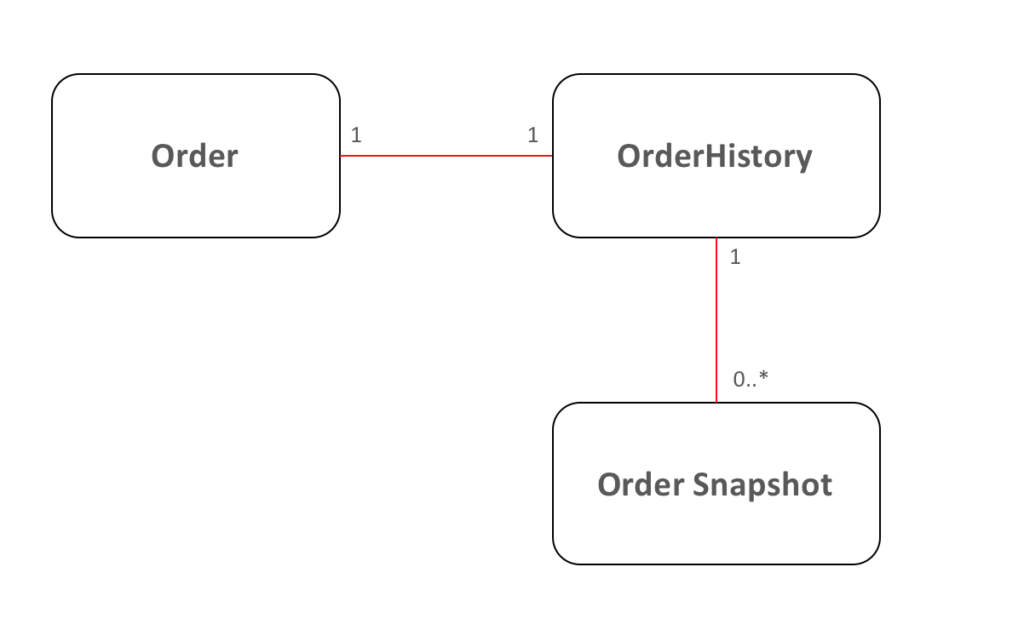
Snapshotting — Versioning to Your State
Adding versioning/history to your state is sometimes referred as "snapshotting" in the event-sourcing world. It is essential to avoid reprocessing all events whenever you need to know what your state was N days ago. It also helps with debugging as you can quickly recognize the point in time at which the state of the application is different from what is expected after processing an event.
Snapshotting is useful, inexpensive, easy to implement, and excellent for temporal reports. If you have decided to implement Event Sourcing, put a little extra effort to also implement snapshotting.
Fixing Inconsistencies
Here is usually where all your efforts pay off. Once you have event sourcing/logging and Snapshotting in place, you can use a slightly modified version of the Retroactive Event pattern to fix inconsistencies.
I summary, if you have fixed a bug and now also need to adjust the state of the affected entities, instead of updating it manually, you can set the state of your entity to what it was before the bug and replay all events related since then. This will automatically correct your state without a manual intervention.
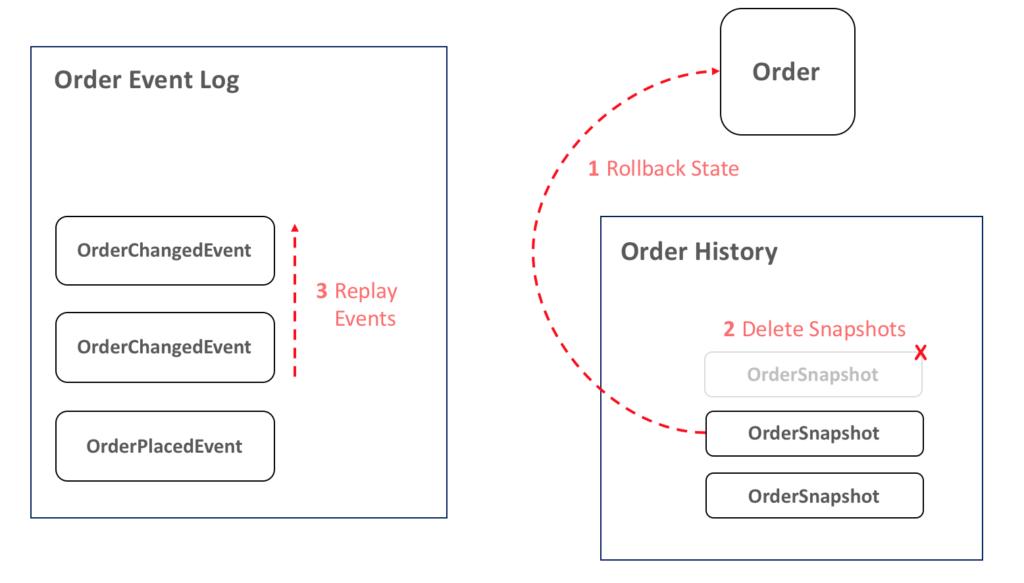
- Rollback State: rollback the state of an entity to what it was before the bug. You can avoid Steps 1 and 2 by just replaying all events. In this case, however, we are restoring a previous state because we would like to avoid reprocessing the whole thing.
- Ignore Snapshots: all snapshots after the restored one should be marked as to avoid restoring an inconsistent snapshot in the future.
- Rebuild Events: rebuild all events from the target onwards.
But, what if the event has wrong data in it or should never have been triggered in the first place? Can we update or delete the event and reprocess the whole thing?
If you remember, the first rule of event sourcing is that "Events are always immutable" and that is for a very good reason; you need to trust the log that you are seeing. But it doesn't answer our question; just slightly modify it: how can we change the event log without changing the event?
Well, an easy way to address this issue is to mark events as ignorable so that we can ignore them during the rebuilding process:
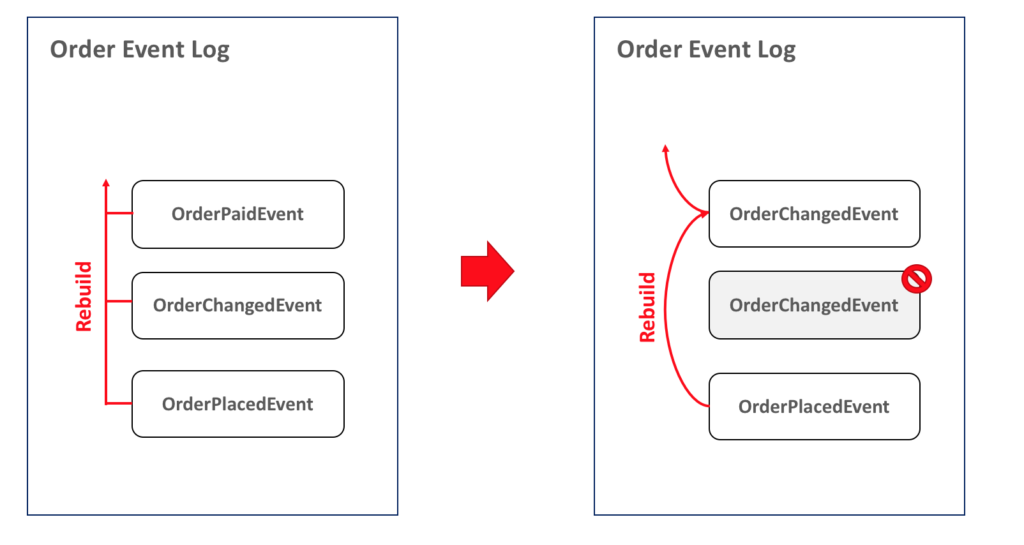
What if an event was triggered by the wrong data or in the wrong order? Using this approach, all we have to do is mark the event as ignorable and add a new one with the correct values or in the right position, as follows:
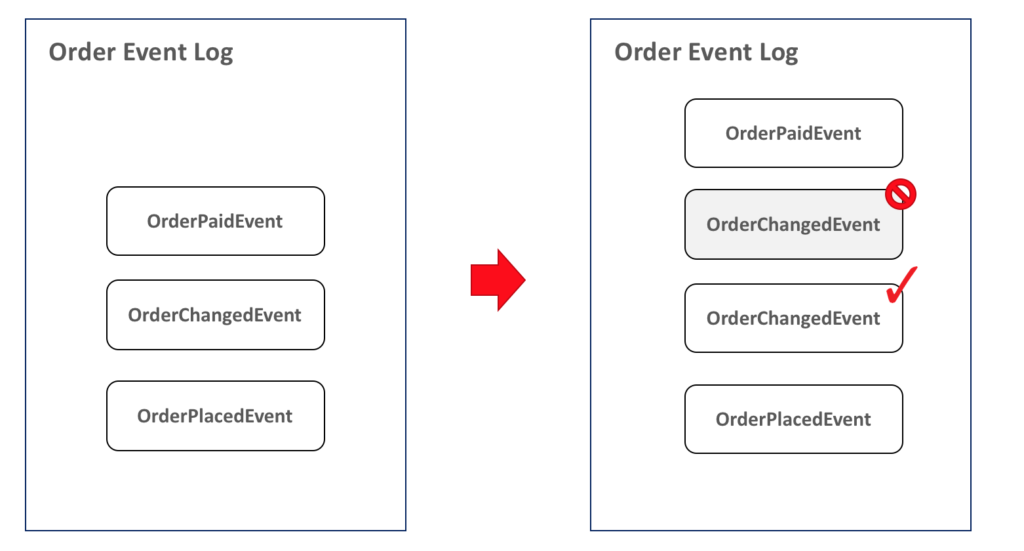
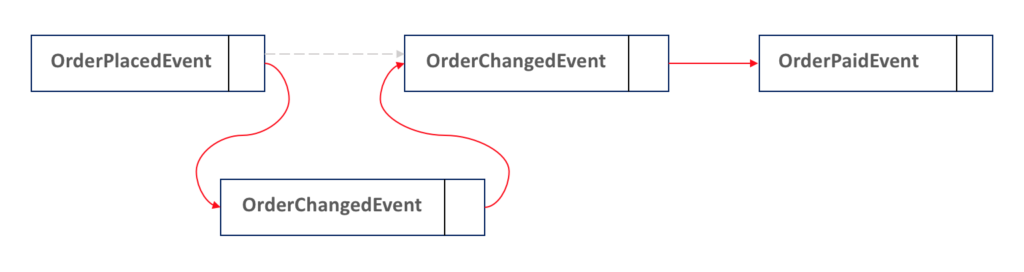
Cool, isn't? But there is an extra tricky task here: how can we build a sequence of events which allows you to add events in the middle?
A naive solution is to add a float counter for each entity. It will let you add items in the middle infinitely according to the theory of supertasks (in practice, you are limited by the float/double max size), which is normally more than enough room to add all the necessary events to fix your state:
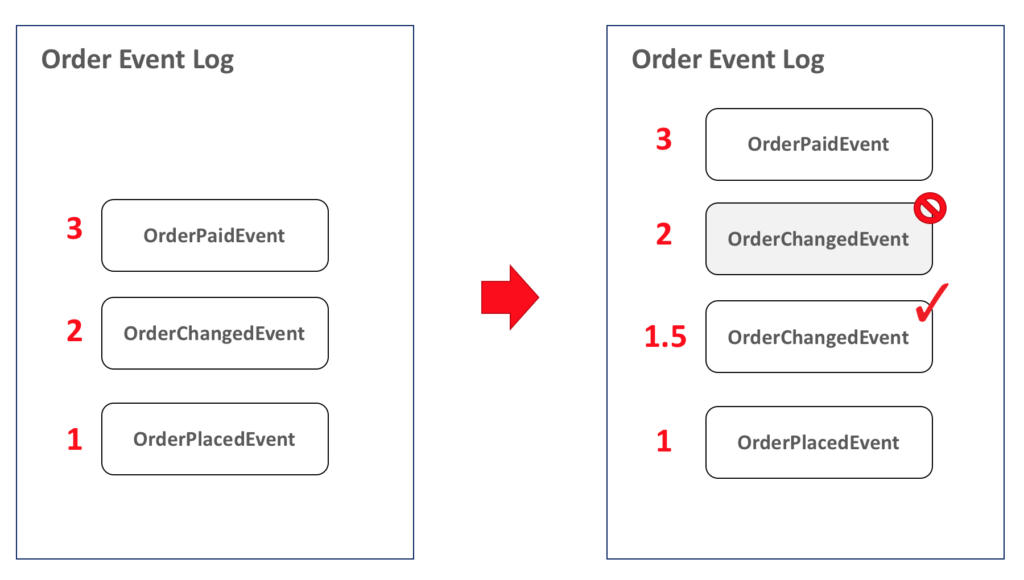
Of course, the approach above has a lot of flaws, but it is ridiculously simple to implement, easy to query, and works pretty well for most of the cases. If you need to build a more robust structure, consider storing your events in a Linked List structure:
What About External Systems | Other Microservices?
A microservices is not an island, so it is reasonable to think that one of the side effects of replaying events is that your service might send messages to external ones. Those messages might trigger inconsistencies or propagate errors in other systems, which can potentially make the situation worse than it was before.
Unfortunately, due to the variety of possibilities, there is no silver bullet to solve this problem, and each case has to be handled individually. Some of the conventional solutions are:
- Changing the configuration temporarily to not send any external messages or add an interceptor that allows you to configure which messages need to be sent;
- Reroute specific requests to a fake service (a typical scenario if you are using the Service Mesh pattern)
- Enable other services to recognize that a given operation has already been executed in the past with the same parameters, and then, instead of throwing an error, just return the same success message as before.
Naturally, there are a considerable number of cases where you won't be able to fix external inconsistencies automatically, in this scenario is expected from other systems to print a human-readable error and/or trigger a notification for someone to intervene.
Advantages of Event Sourcing
Even though it is a straightforward pattern, there are many advantages of using it:
- The event log has a high business value;
- It works pretty well with DDD and event-driven architectures.
- Audition of the origin of all changes in your application state;
- It allows you to replay failed events;
- Easy debugging, as you can copy all the events of a target entity to your machine and debug each event to understand how the application reached a specific state (ignore the security implications of copying data from production);
- Allows you to use the Retroactive Event pattern to rebuild/fix your state.
Many authors also include as an advantage the ability to make temporal queries, but I consider querying multiple subsequent events not a trivial task. Therefore, I usually perceive the temporal queries as an advantage of the Snapshotting Pattern.
Drawbacks of Event Sourcing
- It is slightly less intuitive to work within synchronous calls as you will need to transform the request into an event first.
- Whenever you deploy a breaking change, you will be forced to also migrate your history of events if you want to be backward-compatible (also referred as Event Upgrading).
- Some implementations might need an extra job to check the state of the latest events to ensure that all of them have been processed.
- Events might contain private data, so don't forget to ensure that your event log is appropriately secured.
Conclusion
I have shown a slightly modified version of the Event Sourcing / Event Logging pattern which has been working well for me in the last few years. The first time I heard about it was nearly 10 years ago in the famous Martin Fowler blog post (a must read). Since then, it has helped me a lot to make the state of my microservices nearly unbreakable, not to mention all the reporting capabilities.
It is, however, not something that should be used indiscriminately in all your services. I personally think that only the core ones are actually worth it. You probably don't need to keep the history of all the times the user has changed his own name in the system, for instance.
If you have any questions, feel free to tweet me at @deniswsrosa.
Published at DZone with permission of Denis W S Rosa. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments