Everything I Know About Distributed Locks
Learn about distributed locks such as the efficiency and correctness and the two different types: optimistic and pessimistic.
Join the DZone community and get the full member experience.
Join For Free
Locking often isn’t a good idea, and trying to lock something in a distributed environment may be more dangerous. But sometimes we need to keep this risk and try to use a distributed lock for two main reasons:
- Efficiency: a lock can save our software from performing unuseful work more times than it is really needed, like triggering a timer twice.
- Correctness: a lock can prevent the concurrent processes of the same data, avoiding data corruption, data loss, inconsistency and so on.
You might also like: Distributed Locks Are Dead, Long Live Distributed Locks
We have two kinds of locks:
- Optimistic: instead of blocking something potentially dangerous happens, we continue anyway, in the hope that everything will be ok.
- Pessimistic: block access to the resource before operating on it, and we release the lock at the end.
To use optimistic lock, we usually use a version field on the database record we have to handle, and when we update it, we check if the data we read has the same version of the data we are writing.
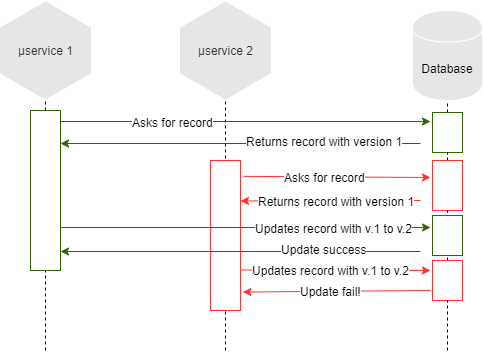
Database access libraries like Hibernate usually provide facilities to use an optimistic lock.
The pessimistic lock, instead, will rely on an external system that will hold the lock for our microservices.

As for optimistic lock, database access libraries like Hibernate usually provide facilities, but in a distributed scenario, we would use more specific solutions that are used to implement more complex algorithms like:
- Redis uses libraries that implement a lock algorithm like ShedLock, and Redisson. The first one provides lock implementation using also other systems like MongoDB, DynamoDB, and more.
- Zookeeper provides some recipes about locking.
- Hazelcast offers a lock system based on his CP subsystem.
Implementing a pessimistic lock, we have a big issue; what happens if the lock owner doesn’t release it? The lock will be held forever and we could be in a deadlock. To prevent this issue, we will set an expiration time on the lock, so the lock will be auto-released.
But if the time expires before the task is finished by the first lock holder, another microservice can acquire the lock, and both lock holders can now release the lock, causing inconsistency. Remember, no timer assumption can be reliable in asynchronous networks.
We need to use a fencing token, which is incremented each time a microservice acquires a lock. This token must be passed to the lock manager when we release the lock, so if the first owner releases the lock before the second owner, the system will refuse the second lock release. Depending on the implementation, we can also decide to let win the second lock owner.
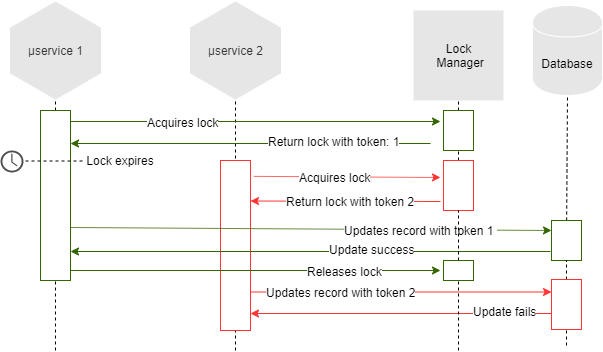
As you can see in the image above, the database has an active role in this scenario.
In the end, I have another question in my mind: is it better to have one node with a replica in case of disaster, or is it better to have a cluster of nodes? The answer is: it depends :)
If we are looking to Redis, we should be careful of what shines, and it may be better to avoid running 5 Redis servers and check for a majority to acquire your lock when a Redis server with a replica may be enough, and, above all, may be better because the lock will be faster and cleaner where the lock is. To learn more about this, I suggest you read this Martin Kleppmann blog.
But in general, when we are talking about locks, it is better to have only one node in charge of a particular lock in order to prevent the split-brain issue. If we would like to split the load, we can elect a leader for a specific set of lock identifiers and contact always the same node.
Some systems like Hazelcast and Zookeeper work using a leader election, but their protocol cannot work in some network scenarios or the configuration may be hard (i.g. AWS BeanStalk), so a simple Redis server with its cluster and data sharding configuration could be easier to set up and manage.
Further Reading
Published at DZone with permission of Davide Cerbo. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments