Raft in Tarantool: How It Works and How to Use It
Learn how synchronous replication works in Tarantool, how to configure leader election, and about some new Raft-based algorithms in this one-stop tutorial.
Join the DZone community and get the full member experience.
Join For Free
Last year, we introduced synchronous replication in Tarantool. We followed the Raft algorithm in the process. The task consisted of two major phases: so-called quorum writing (i.e., synchronous replication) and automated leader election.
Synchronous replication was first introduced in release 2.5.1, while release 2.6.1 brought the support of Raft-based automated leader election.
My name is Sergey Petrenko, and I participated in the development of these big features. Today, I'll tell you how they work. I'll address configuring leader election as well as some new stuff the Raft-based algorithm allows Tarantool users to do.
1. Replication in a Nutshell
Before delving into our leader election algorithm, let's answer this question: why are those algorithms needed at all?
The need to choose a leader arises in a cluster of several nodes with replication — data synchronization between nodes. If you are already familiar with replication, you can move on to the next section.
There are two types of replication: asynchronous and synchronous.
Asynchronous Replication
This type of replication is a transaction that is confirmed right as it is logged on the master, and then it's sent to replicas. It is very fast.
Besides, a cluster with asynchronous replication doesn't lose accessibility, no matter how many replicas fail. As long as the master is functioning, the ability to commit transactions remains.
But the price for speed and accessibility is reliability. If the master fails, some transactions committed on it may not make it to any replicas and therefore will be lost.
Asynchronous replication looks like this:
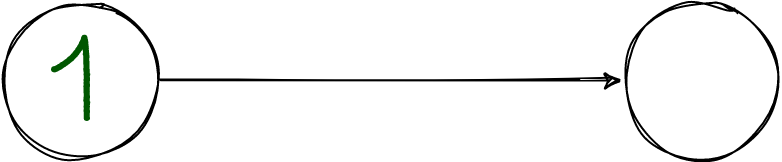 The master is on the left. It responds to the client with "ok" as soon as it logs the transaction.
The master is on the left. It responds to the client with "ok" as soon as it logs the transaction.
Or like this:
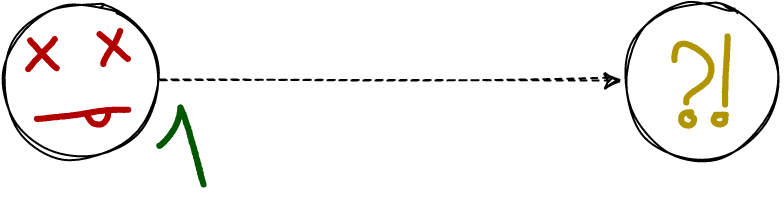 The master is on the left. It responded to the client that everything is fine, but then it crashed, and the transaction doesn't exist on any other node.
The master is on the left. It responded to the client that everything is fine, but then it crashed, and the transaction doesn't exist on any other node.
Synchronous Replication
In the case of synchronous replication, a transaction is first sent to replicas, then confirmations are gathered from a number of replicas, and only then the master commits the transaction. Such replication is quite reliable. In case the master fails, it is guaranteed that all transactions it confirmed exist on at least one replica.
Unfortunately, it also entails some disadvantages. Firstly, the cluster's write availability is affected: if enough replicas fail, the master loses the ability to apply transactions because it can't gather a quorum anymore. Also, the lag between the transaction being logged and it being confirmed is much more than in asynchronous replication. After logging, the master must also send the transaction to replicas and wait for their response.
Synchronous replication looks like this:
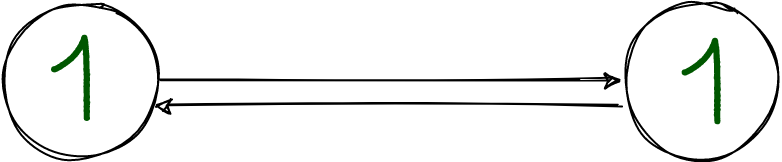
The master is on the left. Before sending a response to the client, it sends the data to the replica and waits for its response.
No matter what happens, with synchronous replication you won't lose the confirmed data:
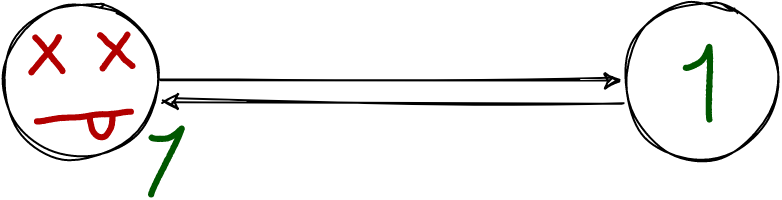
Even if the master fails, the replica still has the transaction
The key concept of synchronous replication is a quorum. Before confirming the transaction, the master makes sure it was sent to a quorum of nodes and can be applied to them. The size of the quorum can be configured. For example, if the quorum equals two, the transaction must be on at least one replica beside the master before it can be committed.
2. Leader and Leader Election
In this article, leader and master mean the same thing. It's a node that can apply transactions and replicate them to other nodes in the cluster.
What are we going to do when the current leader fails? We need to assign a new leader somehow. Several leaders can't be elected; we want only one node to be the source of information. Otherwise, additional efforts would be required to avoid conflicts between transactions applied on different nodes.
So, how do we elect a single leader? There are two ways to do that. The first way is that all replicas can wait until something external assigns a single leader to them after the leader fails. It could be an administrator who switches one node from read-only mode to read-write or an external tool that manages replication. In this case, it is possible to assign a single leader, but some extra steps are needed, and the cluster downtime will be significant.
Let me explain what I mean: if the leader fails, the newly elected leader must contain all transactions applied to the old one. Since the leader is the source of truth, the absence of transactions would mean that data was confirmed and then just vanished. This is especially important for synchronous replication. Not any node can become a leader. It must be the one that falls behind the old master the least. The next step must be applying all synchronous transactions which the old leader didn't confirm. We must wait until they are replicated to a quorum of nodes and then send confirmations of these transactions.
In other words, there is a lot of work, and we don't want to do it manually.
The other option is to teach the cluster nodes to agree on which one of them becomes a new leader. That's where we get the idea of an election algorithm. The nodes must elect the new leader by communicating with each other. Then, the newly elected leader must confirm all synchronous transactions remaining from the old leader. That is, do all the work described above, but automatically. The advantage of such a solution is the minimization of downtime after a leader node fails. And the disadvantage is the need to choose and implement the leader election algorithm. Although the latter may only be significant for our team.
Fortunately, we didn't have to reinvent the wheel. We decided to implement Raft — a well-known and reliable algorithm.
3. The Raft Algorithm
Raft includes synchronous log replication and leader elections, with the assurance that a single leader can be chosen, at any part of the cluster lifetime.
Usually, a cluster looks like this: one node is in the leader state and can write to the log, apply transactions, etc. All other nodes are in the follower state and apply everything they receive from the leader. If a follower receives a transaction from a non-leader via the communication channel, it ignores it.
The part of the protocol responsible for log replication is fairly clear. The current leader sends the AppendEntries requests with new entries to all cluster nodes. When more than half of cluster members successfully apply the entries sent by the leader, these entries are considered confirmed.
The other part of the protocol that we'll look at in this article concerns leader election.
The following is a brief description of the Raft algorithm, necessary for further narration. You can read the original article for more details.
The entire lifetime of the cluster is divided into logic blocks called terms. They are numbered with integers starting at one, and each term begins with the election of a new leader. Once the leader is selected, it accepts requests and logs new entries that it's further sending to the rest of the cluster members.
For a node to be elected, more than half of the nodes in the cluster must vote for it. It guarantees that in each term either a single leader is elected or none at all. In some terms, an election may never result in choosing a leader. This may happen if all nodes have voted, but none of the candidates received a majority of votes. In this case, a new term will begin, and new elections will be held. All nodes will vote again. Thus, sooner or later one of the nodes will become the leader.
In Raft, each node can be in one of three states: follower, candidate, or leader.
A follower is a state in which a node can only respond to AppendEntries from the leader and RequestVote requests from candidates. If a follower has not received anything from the leader for a long time (during the so-called election timeout), then it enters the candidate state and starts a new term and new election.
A candidate is the state of the node that initiated the new election. In this case, the node votes for itself and then sends RequestVote requests to all members of the cluster. The response to this request is the VoteGranted field, which is set to true if the node voted for the candidate. The candidate itself never responds to RequestVote requests from other candidates. It has already voted for itself and doesn't vote for anyone else. The candidate counts the votes cast for it. As soon as there are more votes in its favor than half of all nodes in the cluster, the candidate becomes the leader. It reports this to every other node by sending an empty request AppendEntries — a kind of heartbeat signal that only the leader can send.
If the election timeout has passed since the beginning of the election, and the required number of votes has not been gathered, this may mean that no one received enough votes. In this case, the candidate initiates a new election by increasing its term and resending the RequestVote request to other nodes. To avoid an endless loop of re-elections, the election timeout is slightly randomized on each of the nodes. This way, sooner or later, one of the candidates will be the first to initiate new elections and gather the required number of votes.
A leader is the only state in which a node can write to the log. The leader replicates this log with an AppendEntries request. Also, when no new requests are arriving, the leader periodically sends heartbeats — empty AppendEntries requests — to avoid timeouts and new nominations.
If the leader or a candidate suddenly learns from one of the nodes that a new term has started (greater than the one they are in), it immediately becomes a follower. After that, the election timeout starts counting from the beginning.
The log contains only the number of the current term and the voice cast in this term. This is necessary to prevent nodes from re-voting after a restart.
The node state is not logged. After restarting, the node is always in the follower state.
4. Our Implementation of Synchronous Replication
The part of the Raft protocol responsible for log replication was implemented as a separate task three months before the work on leader election began.
Synchronicity can be enabled separately for spaces with valuable data. Then only transactions related to this space will be synchronous.
A synchronous transaction waits for confirmation from a quorum of replicas before it can be applied. That is, first it must be logged, and then it will be sent to the quorum of replicas which must confirm receiving the transaction. Only then the transaction will be completed and applied.
If the transaction does not meet the quorum within the specified time interval (which can be configured, see below), then it will be rolled back by timeout.
The specific of the Tarantool log is that it only stores redo entries, not undo entries. This means that after a restart, the log can only be replayed from its beginning to the end, repeating all applied transactions. However, the log cannot be unseen — that is, an applied transaction, written to the log, cannot be undone. The log simply does not have the necessary functionality to do this. It makes the log more compact. The structures that are needed to roll back the transaction are stored in memory, and in the case of asynchronous replication, they are released immediately after a successful write to the log. And in the case of synchronous replication, they are released either after the transaction is confirmed by a quorum of nodes, or after it is rolled back by timeout.
Our log is append-only. When rolling back a transaction, you can't just remove extra entries from it. Also, since the transaction has already been sent to the replicas, we now need to tell them that it has been rolled back. Due to the specifics of the log, all transactions are logged into it, both synchronous and asynchronous. It means, for some time, the log contains synchronous transactions, about which we don't know whether they are confirmed or not.
Because of this, a new type of log entry was needed — ROLLBACK. As soon as the master times out waiting for confirmations from replicas, it logs a ROLLBACK entry with the LSN (log sequence number) of the rolled-back transaction. This entry, like all the others in the log, is forwarded to replicas. Upon receiving such entry, the replica rolls back the failed synchronous transaction and all transactions with a larger LSN. The replica can do this due to the undo log stored in its memory. The master does the same.
If the quorum of replicas that received the transaction is gathered, then the replicas need to be told that the transaction has been confirmed. Firstly, it will let them clear the undo log. Secondly, when restoring from the log, they will need information about which transactions are applied and which are not. For this purpose, another service entry was added to the log — CONFIRM.
Replication in Tarantool is implemented as a line-by-line transfer of entries from the master log to replicas. So, CONFIRM and ROLLBACK entries helped us a lot: messages about confirmation or rollback of synchronous transactions are passed to replicas through the regular replication channel. There was no need to figure out how the master would send system messages to them. It simply reads them from the log and sends them as normal data. In addition, replicas can write the received service messages unchanged to their own logs, which allows them to recover correctly, ignoring the canceled synchronous transactions.
During development, we could have taken an alternative path: first, send the transaction to the replicas, and then write it to the master's log only if it was applied to the quorum of replicas. But we would still encounter some difficulties. The replicas still need to be told if a transaction has been canceled. Besides, in some cases, a transaction might be applied on replicas, and then the master might fail and forget about it after a restart. In the case of logging ahead, the master may not be able to apply the unconfirmed transaction automatically, but at least it will not lose it.
So, all transactions, both synchronous and asynchronous, are logged in the write-ahead log (WAL). After a successful write, asynchronous transactions are immediately committed, while synchronous transactions go to a special queue — limbo, where they wait to be replicated to a quorum of nodes. When a quorum of confirmations is reached, the transaction is committed, and a CONFIRM entry is written to the log. If waiting for confirmations timed out, a ROLLBACK entry is written to the log, and the transaction is rolled back along with all transactions following it in the queue.
It should be noted that if the queue of synchronous transactions is not empty, then asynchronous transactions also go into it before being committed. They do not wait for confirmations but must wait in the queue so that they can be rolled back in case a synchronous transaction does not collect a quorum. This is necessary because a synchronous transaction can change data in both synchronous and regular space. As a result, an asynchronous transaction accessing the same space will depend on this synchronous transaction.
By default, while transactions are in the queue, their changes will be visible to other transactions. This problem is called dirty reads, and in order to avoid it, you need to enable the transaction manager. In vinyl (the Tarantool disk engine), the transaction manager was always enabled, and in memtx (the engine for storing data in memory), it arrived in release 2.6 through the efforts of Alexander Lyapunov, which he will tell about in his article.
5. Adapting Raft to Our Replication Protocol
In Tarantool, all communication between the nodes of a replica set occurs through two entities: relay, which is sending data, and applier, responsible for receiving data. Before Raft, relay's only job was sending log entries. After synchronous replication was implemented, it became possible to send the system message to all replicas by simply writing it to the log. We didn't even need to add any additional features to relay. It continues to forward log entries to replicas, as it did before. At the same time, the applier had to be taught how to handle the system messages it received from the master's relay.
In the case of the Raft algorithm implementation, this little stunt did not work so well. The problem is that, firstly, not all Raft system messages should be written to the log, so the relay will have nowhere to read these omitted messages from. Secondly, even messages that get into the log, namely the number of the current term and node's vote, should not be automatically applied by a replica. It must receive information about the change of the term and the vote cast, but it doesn't have to vote the same way as other nodes. Therefore, it was necessary to teach relay to send arbitrary messages to replicas on request. It does this between sending portions of the log.
At the leader election stage of Raft, a lot of additional information is sent: a request for a vote from a candidate and votes from followers. This information should not be stored in the log; according to the protocol, only the current term and the candidate this node voted for in the current term are stored there. The Raft module itself runs in the tx thread, which is the thread that is handling transactions. Each change of state (i.e., the persistent part of the state, the term, and the node's vote) should, according to Raft, go into the log. Once the new state is logged, it can be passed to other replicas. To do this, tx sends a relay message to all threads, which includes non-persistent information — the role of the node in the Raft cluster and, optionally, the vclock of this node. Then each relay sends this information to the replica connected to it, and the replica sends it to its Raft module.
In Raft, the state of a node's log (that is, the data present on the node) can be represented by a single number — the number of log entries which is called the log index. In Tarantool, its analog is the log sequence number (LSN), which is the sequence number assigned to each transaction.
The difference is that, in Tarantool, the state of the log is not a single number, but an LSN array called vclock. This is a legacy from asynchronous master-to-master replication, where all nodes can write at the same time. Transactions from each node are signed not only by the LSN, but also by the ID of the node.
All nodes of the cluster have their own component in the vclock. After recording a transaction that came from another node, the replica assigns the sequence number of the transaction to its vclock component. In a cluster of three nodes, the vclock of one of the replicas could look like this: {1: 11, 2:13, 3:5}. It means this node contains all transactions with a sequence number up to 11 from node 1, all transactions with a sequence number up to 13 from node 2, and (assuming we are looking at the vclock of node 3), this node itself recorded only 5 transactions.
Because of the vclock, we had to make some adjustments to our Raft implementation. Firstly, by default, the algorithm can always determine which node has the most recent data by comparing log indexes. In our implementation, however, we need to compare vclocks, which might be incomparable, for example, {1:3, 2:5} and {1:4, 2:1}. This isn't a serious problem, but, as a result, nodes only vote for the candidates whose vclock is strictly greater than or equal to their own.
As already mentioned, in Tarantool the log is not an undo log, but a redo one, append only log. This itself increases the complexity. Even though the majority of the nodes voted for the candidate, a minority may have more recent data from the previous leader. Since the state of the cluster is now controlled by a new leader, this minority can no longer work. You need to delete these nodes' data and reconnect them to the cluster. This is called a rejoin. This problem didn't arise in the Raft algorithm, since the minority simply cut off the ends of their logs to match the leader's log.
6. Configuring Raft
6.1. Node Operation Mode
For a node to participate in leader election, the election_mode option must be set in its configuration.
box.cfg{
election_mode = "off", -- default value
}election_mode can be set to one of the following values:
"off"— Raft is not working. In this case, the node will receive and remember the number of the current term. This is necessary for the node to immediately join the normal operation of the cluster the moment Raft is turned on."voter"— the node will vote for other candidates, but will never start an election and nominate itself. Such nodes are useful for restricting the number of nodes a leader can be elected from. Let's say you make a cluster of three nodes: two candidates and one voter. Then, if the leader fails, the second of the candidates will win the election immediately by gaining a majority of votes (two out of three — its own and the vote of the voter node).- This setting is also useful if you need to force the leader to resign without turning off Raft on it. If the current leader is reconfigured to
"voter", then it will immediately become read-only and stop sending heartbeats to followers. After the election timeout has passed, the followers will start a new election, and another node will be chosen as the leader.
- This setting is also useful if you need to force the leader to resign without turning off Raft on it. If the current leader is reconfigured to
"candidate"— the node can start an election as soon as it detects that there is no leader. Also, this node can vote for other candidates, but only if it has not yet voted for itself in the current term.
As mentioned above, the lifetime of a cluster is divided into intervals called terms. Terms are numbered with integers starting from one. A new term begins with a new election. Thus, in each term, either one leader is chosen, or no one is able to win the vote. Terms also prevent the same node from voting twice in the same election. After casting a vote in the current election, the node not only remembers that the vote was cast but also writes this vote to the log. With the beginning of a new election (and the beginning of a new term), the vote is reset to zero, which allows the node to vote again.
Raft has a leader election requirement: a quorum of N/2 + 1 votes, along with a ban on voting more than once per election. This ensures that no more than one node can win the election.
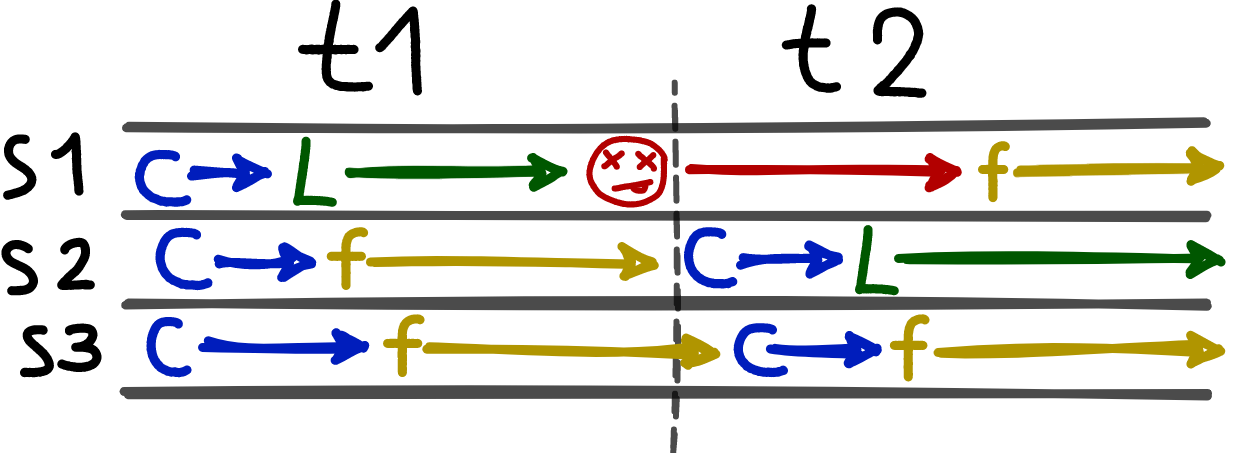 States of three cluster nodes in two terms. In term t1, s1 became the leader, since it was the first to send out a request for a vote. When s1 failed, s2 was the first to notice it. It was also the first to send a request for a vote and became the leader in term t2. When s1 returned, it became a simple follower
States of three cluster nodes in two terms. In term t1, s1 became the leader, since it was the first to send out a request for a vote. When s1 failed, s2 was the first to notice it. It was also the first to send a request for a vote and became the leader in term t2. When s1 returned, it became a simple follower
The node votes for the candidate that was the first to send a request for a vote if its log is newer or equal to the node's log. To find out which of the nodes is newer, their vclocks are compared. A vote will only be cast if each vclock component of the candidate is greater than or equal to the corresponding vclock component of the voter. That is, all transactions that are in the voter's log must also be in the candidate's log.
vclock — vector clock; a structure showing what data is on the node and what isn't. It is an array of serial numbers of transactions that were logged on this node. All nodes of the cluster have their own component in the vclock. After recording a transaction that came from another node, the replica assigns the sequence number of the transaction to its vclock component. In a cluster of three nodes, the vclock of one of the nodes might look like this:
{1: 11, 2:13, 3:5}. It means this node contains all transactions with a sequence number up to 11 from node 1, all transactions with a sequence number up to 13 from node 2, and (assuming we are looking at the vclock of node 3), this node itself recorded only 5 transactions.
In the case of synchronous replication, if the commit quorum for synchronous transactions is set to at least N/2+1, voters will elect a leader which log definitely contains all committed synchronous transactions. Indeed, since a transaction must reach at least N/2+1 nodes to be confirmed, and for a new leader to be elected it needs to receive the votes of at least N/2 + 1 nodes, then this transaction will be in the log of at least one of the nodes which voted. So it will be in the log of the new leader.
6.2. Re-Election Timeout
Re-election is an important element of Raft. It allows you to deal with the situation when none of the candidates win a quorum of votes. It works like this: a candidate collects votes for itself during the election timeout. If a sufficient number of votes has not yet been gathered, and the leader has not been declared, a candidate starts a new election, increasing the term number. Election timeout depends on the configuration and is randomized within 10% of its value.
The election timeout can be configured like this:
box.cfg{
election_timeout = 5, -- default value, seconds
}6.3. Quorum of Votes for a Candidate
The number of votes a node must receive before becoming a leader can only be configured in conjunction with a synchronous replication quorum.
box.cfg{
replication_synchro_quorum = 1, -- default value
}In the case of synchronous replication, any value other than 1 makes sense. The quorum of nodes that applied the transaction is calculated as follows: 1 for the successful logging of the transaction on the master + 1 for each replica that applied the transaction.
A value of 1 means that synchronous replication is disabled, as a quorum will be reached immediately after the transaction is logged on the master.
For leader election, the quorum value cannot be set to less than N/2 + 1, where N is the number of voting nodes in the cluster — not all nodes, but the voting ones, configured as election_mode = 'candidate' or election_mode = 'voter'. Otherwise, during the first elections, several leaders may be chosen.
In order to add new voting nodes to the cluster correctly, you need to do the following:
- Connect a replica to the cluster with replica's
election_mode = 'off'. - Wait until the replica is initialized and starts working normally.
- If necessary, increase
replication_synchro_quorumso that it is no less than N/2 + 1 (N is the number of voting nodes + the new replica). - Enable Raft on the replica by setting
election_mode='voter'or'candidate'.
If a non-voting replica is added, there is no need to update the quorum.
If you need to remove the voting replica from the cluster, then you need to disable it first and only then reduce the quorum, but not below the value of N/2 + 1.
6.4. Coming Soon
We understand that the process described above is quite inconvenient and subject to human error. Very soon, in versions 2.6.2 and 2.7.1, it will be possible to specify a formula for calculating the quorum in the configuration. In this case, the quorum will be updated automatically each time a node is added to the cluster or removed from it. It will look like this:
box.cfg{
replication_synchro_quorum = "N / 2 + 1", -- default value
}The quorum will be updated in accordance with the formula each time a node is inserted or removed from the _cluster space, which stores information about all nodes registered in the cluster. The formula will be substituted with the N parameter, which equals the number of records in the _cluster space. Both the synchronous replication quorum and the voting quorum will use this formula.
Note that the failure of one of the nodes will not lead to a change in the quorum. To lower the quorum, you will need to remove the node from the _cluster space. Tarantool never removes nodes from _cluster on its own, only an administrator can do this.
7. Raft Cluster Monitoring
To monitor Raft's status, you can use the table box.info.election. It looks like this:
box.info.election
---
- state: leader
vote: 1
leader: 1
term: 2
...Where:
state= the state of the current node; possible options arefollower,leader,candidate, ornone.term= the number of the current term.leader=replica_idof the node that is the leader in this term.vote=replica_idof the node this node voted for.
Vote and leader do not have to match. It may turn out that this node was also a candidate and voted for itself. But then some other candidate got ahead of it and became the leader first.
The table shows the node's current role, the term number, the ID of the term's leader, and the ID of the node that the vote was given to in the last election.
In addition, Raft logs all its actions in detail:
2020-11-27 14:41:35.711 [7658] main I> Raft: begin new election round
2020-11-27 14:41:35.711 [7658] main I> Raft: bump term to 2, follow
2020-11-27 14:41:35.711 [7658] main I> Raft: vote for 1, follow
2020-11-27 14:41:35.712 [7658] main/116/Raft_worker I> Raft: persisted state {term: 2, vote: 1}
2020-11-27 14:41:35.712 [7658] main/116/Raft_worker I> Raft: enter leader state with quorum 1The logs can show who the node voted for, who its leader was, and at what moments it took the lead itself.
It also logs the term in which the node is located and the reasons why it didn't vote for other nodes if it received a request to vote. Among these reasons can be the incomparable vclocks of the voter and the candidate, or the fact that the leader is already selected in the current term.
8. Conclusion
Tarantool 2.6 has built-in functionality for automated leader election based on the Raft algorithm. Now you can change the master without using external tools. This allows you to keep all settings in one place — the Tarantool configuration file. Quorum updates will soon be automated, further improving usability. Also, the advantages of a built-in implementation are greater reliability and the fastest possible response to upcoming events. Now, the built-in functionality of Tarantool allows you to write an automated failover with minimal effort.
A detailed sample project in Lua can be found in our examples repository. Take a look at it. Aside from leader election, it contains many useful code samples.
Opinions expressed by DZone contributors are their own.
Comments