The Role of Data Governance in Data Strategy: Part II
This article explains how data is cataloged and classified and how classified data is used to group and correlate the data to an individual.
Join the DZone community and get the full member experience.
Join For FreeIn the previous article, we discussed the importance and role of Data Governance in an organization. In this article, let's see how BigID plays a vital role in implementing those concepts w.r.t Data Privacy, Security, and Classification.
What Is BigID? How Does This Tool Help Organizations Protect and Secure Personal Data?
BigID is a data discovery and intelligence platform that helps organizations identify, classify and protect sensitive and personal data across various data sources. It uses advanced machine learning and artificial intelligence techniques to scan and analyze large data sets and automatically identify sensitive data such as PII, PHI, and credit card numbers, allowing organizations to comply with data privacy regulations such as GDPR, CCPA, and HIPAA.
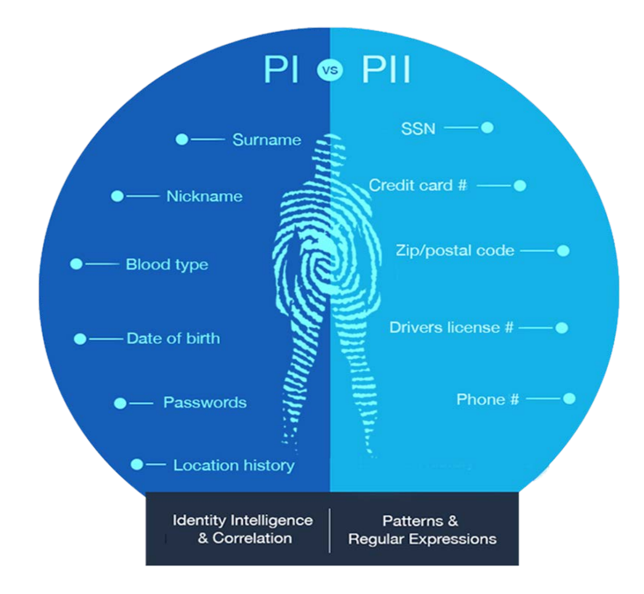
The definition of sensitive data is evolving in many ways. Let's look at some of the key categories that BigID distinguishes between PI and PII and how that data is classified and defined.
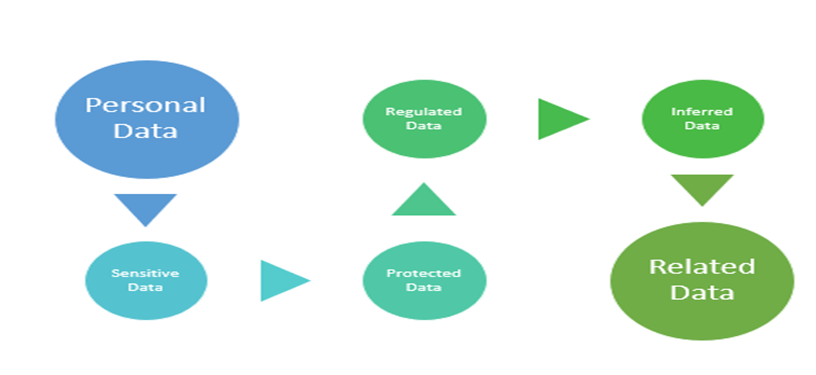
HowBigID identifies and, classifies, correlates the PI vs. PII.
What Does BigID Do With the Data Sets, and How Does It Work at the Enterprise Level?
Below are the core concepts of the 4 C's in BigID:
- Catalog
- Classification
- Cluster Analysis
- Correlate
Before we catalog and classify, one should know your Data (not just your metadata). Critical data is everywhere in the Organization. In this modern era, the data is no longer confined to your relational databases.
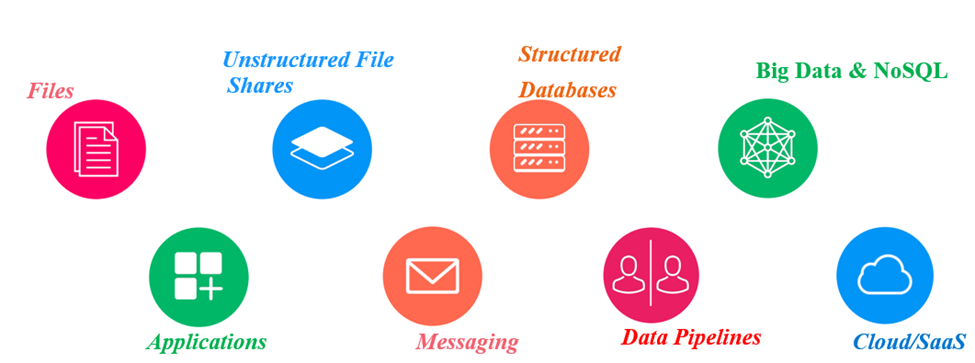
The data grows from all aspects and is a day-day challenge. More data in more places. Hard to identify where the critical data is located and where all the data is present in the echo system.
As the data grows in parallel, there will be a rise in data redundant and duplicate data which leads to a lack of Orchestration. The more it grows, we see the more siloed data.
Catalog
For all the data in your ecosystem, the BigID catalog serves as a machine-learning-driven metadata store. Using the catalog, you may collect and manage technical, operational, and business metadata from all enterprise systems and applications that BigID analyzes. Furthermore, with the incorporation of active metadata and classification, it assists you in automatically cataloging and mapping sensitive and private data with deep data insight.
The catalog is built on data objects, which are the distinct table and file components that make up your corporate data. These items are displayed in this catalog list, and you can click on any item to view more information.
Classification
To automatically categorize data components, information, and documents across any data source or data pipeline, BigID classification uses both pattern- and ML-based classification algorithms. The platform can find sensitive data, analyze activities, satisfy compliance, and protect personal data by using advanced ML (machine learning), NLP (natural language processing), and deep learning.

BigID comes with a comprehensive set of field classifiers that are ready to use, including pattern-based classifiers like Email, National ID Number, and Gender, document classifiers like Health Forms, Income Tax Returns, and Rental Agreements; and NLP classifiers like names and addresses. Using a specific administration interface, all of those classifiers are maintained.
Cluster Analysis
For simple labeling, governance, and data consolidation across huge file repositories and databases, BigID's cluster analysis uses proprietary ML-based approaches to detect duplicate and related data. The automatic, unsupervised clustering algorithms classify files fuzzily based on their contents, quickly group files with similar contents, and identify duplicate data no matter where it resides—on-premises, in the cloud, or both.

BigID's cluster analysis helps data minimization by pointing out which data can be minimized, where there is a duplicate or redundant data, and which high-risk data should be prioritized. Cluster analysis also helps accelerate cloud migrations through intelligent cloud data rationalization, improve data hygiene, identify what should and should not be migrated, and reduce costs.
Correlation
BigID's correlation connects personal data back to a person or entity for privacy data rights automation. Leveraging correlation and the deeper discovery capabilities based on it, you can automatically identify data relationships, identities, entities, dark data, inferred data, and associated sensitive data, discover variations of highly sensitive, highly restricted, and uniquely identifiable data, and leverage an automated process to fulfill access requests and other data rights required by the law.

Correlation gives classification additional context. To create identification and entity profiles, link data to its owner, and show how data is connected across data sources, correlation focuses on "whose data," whereas classification focuses on "what data." In order to improve performance, accuracy, and scale across all sorts of data everywhere, correlation leverages cutting-edge ML graph technology.
In summary, we saw how data is cataloged and classified and how classified data is used to group and correlate the data to an individual. Let's discuss how and where data discovery comes into play in the next article.
Opinions expressed by DZone contributors are their own.
Comments