Finding and Fixing Spring Data JPA Performance Issues with FusionReactor
With the right tools in place, you can identify performance problems easily and often even before they cause trouble in production.
Join the DZone community and get the full member experience.
Join For FreeFor several years, Spring Data JPA has established itself as one of the most commonly used persistence frameworks in the Java world. It gets most of its features from the very popular Hibernate object-relational mapping (ORM) implementation. The ORM features provide great developer productivity, and the basic functionality is very easy to learn.
But as so often, you need to know a lot more than just the basic parts if you want to build enterprise applications. Without a good understanding of its internals and some advanced features, you will struggle with severe performance issues. Spring Data’s and Hibernate’s ease of use sometimes makes it way too easy to build a slow application.
But that doesn’t have to be the case. With the right tools in place, you can identify performance problems easily and often even before they cause trouble in production. In this article, I will show you 3 of Hibernate’s and Spring Data’s most common performance pitfalls, how you can find them using FusionReactor’s Java Monitoring or Hibernate’s statistics, and how you can fix them.
Pitfall 1: Lazy Loading Causes Lots of Unexpected Queries
When you learn about Spring Data JPA and Hibernate performance optimizations, you always get told to use FetchType.LAZY for all of your applications. This tells Hibernate to only load the associated entities when you access the association. That’s, of course, a much better approach than using FetchType.EAGER, which always fetches all associated entities, even if you don’t use them.
Unfortunately, FetchType.LAZY introduces its own performance issue if you use a lazily fetched association. Hibernate then needs to execute an SQL query to get the associated entities from the database. This becomes an issue if you work with a list of entities, as I do in the following code snippet.
xxxxxxxxxx
[Code]
(path = "/concert")
public class ConcertController {
Logger logger = Logger.getLogger(ConcertController.class.getSimpleName());
private ConcertRepository concertRepo;
public List<Concert> getConcerts() {
List<Concert> concerts = this.concertRepo.findAll();
for (Concert c : concerts) {
logger.info("Concert "+c.getName()+" gets played by "+c.getBand().getName());
}
return concerts;
}
}
[/Code]
The findAll method of Spring Data’s JpaRepository executes a simple JPQL query that gets all Concert entities from the database and returns them as a List. Each of these concerts is played by band. If you set the FetchType of that association to FetchType.LAZY, Hibernate executes a SQL query to fetch the Band when you call the getter method on the Concert entity. If you do that for each Concert entity in the List, Hibernate will execute an SQL query for each Band who plays a concert. Depending on the size of that List, this will cause performance problems.
Find Unexpected Queries
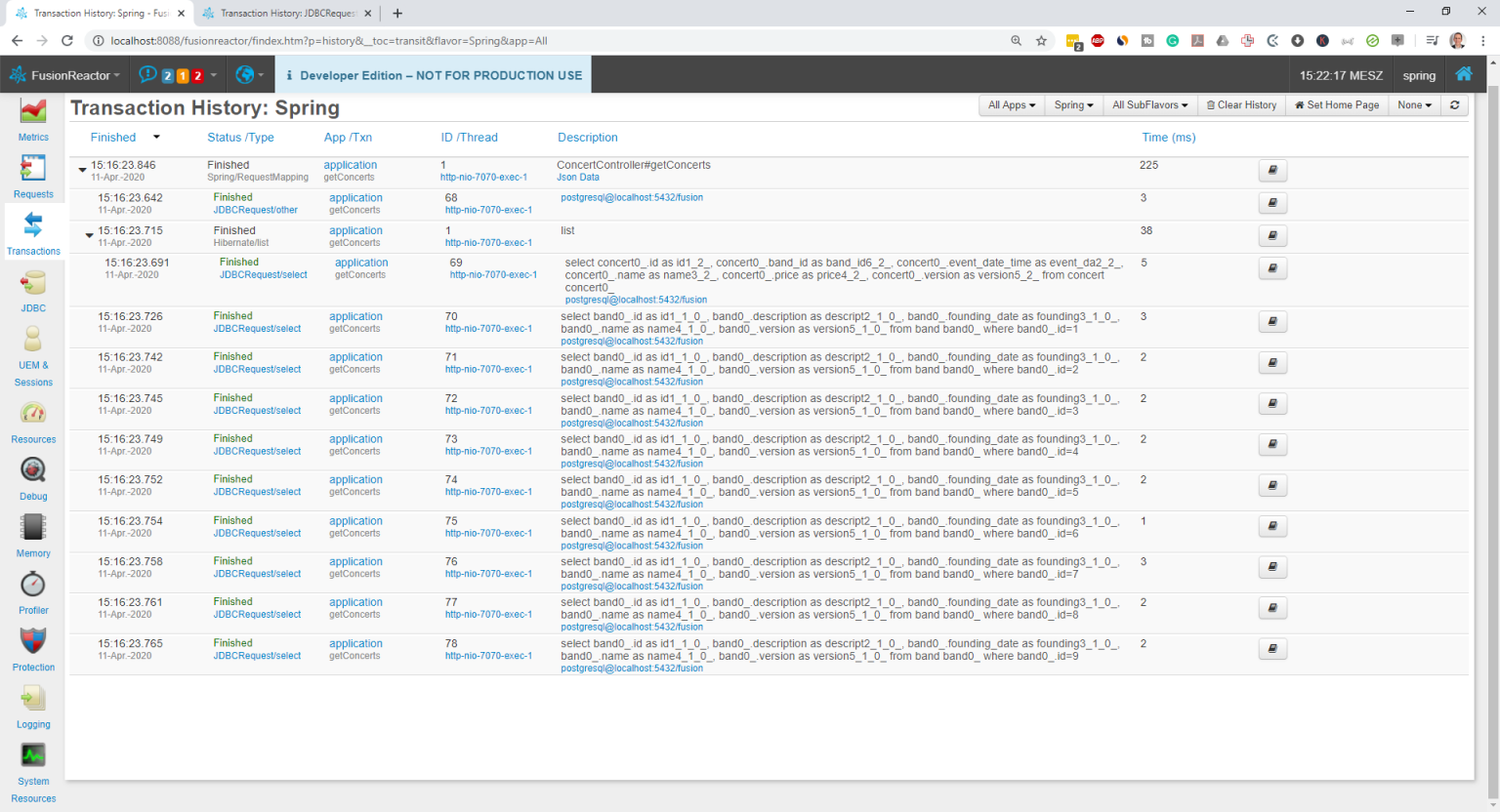
This issue is relatively hard to find in your code. But it gets pretty easy if you monitor the queries executed by your application.
Using FusionReactor, you can easily see all the SQL statements, which were performed by the getConcerts method. Based on the code, you would probably expect that Hibernate only performs 1 SELECT statement. But as you can see in the screenshot, Hibernate executed 10 SELECT statements because it had to get the associated Band entity for each Concert.
{kind=link}
Or you can activate Hibernate’s statistics component and the logging of SQL statements. Hibernate then writes a log message at the end of each session, which includes the number of executed JDBC statements and the overall time spent on these operations.
xxxxxxxxxx
[Code]
2020-04-11 15:28:04.293 DEBUG 23692 --- [nio-7070-exec-1] org.hibernate.SQL : select concert0_.id as id1_2_, concert0_.band_id as band_id6_2_, concert0_.event_date_time as event_da2_2_, concert0_.name as name3_2_, concert0_.price as price4_2_, concert0_.version as version5_2_ from concert concert0_
2020-04-11 15:28:04.338 DEBUG 23692 --- [nio-7070-exec-1] org.hibernate.SQL : select band0_.id as id1_1_0_, band0_.description as descript2_1_0_, band0_.founding_date as founding3_1_0_, band0_.name as name4_1_0_, band0_.version as version5_1_0_ from band band0_ where band0_.id=?
2020-04-11 15:28:04.354 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 1 gets played by band 1
2020-04-11 15:28:04.355 DEBUG 23692 --- [nio-7070-exec-1] org.hibernate.SQL : select band0_.id as id1_1_0_, band0_.description as descript2_1_0_, band0_.founding_date as founding3_1_0_, band0_.name as name4_1_0_, band0_.version as version5_1_0_ from band band0_ where band0_.id=?
2020-04-11 15:28:04.358 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 2 gets played by band 2
2020-04-11 15:28:04.358 DEBUG 23692 --- [nio-7070-exec-1] org.hibernate.SQL : select band0_.id as id1_1_0_, band0_.description as descript2_1_0_, band0_.founding_date as founding3_1_0_, band0_.name as name4_1_0_, band0_.version as version5_1_0_ from band band0_ where band0_.id=?
2020-04-11 15:28:04.361 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 3 gets played by band 3
2020-04-11 15:28:04.362 DEBUG 23692 --- [nio-7070-exec-1] org.hibernate.SQL : select band0_.id as id1_1_0_, band0_.description as descript2_1_0_, band0_.founding_date as founding3_1_0_, band0_.name as name4_1_0_, band0_.version as version5_1_0_ from band band0_ where band0_.id=?
2020-04-11 15:28:04.364 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 4 gets played by band 4
2020-04-11 15:28:04.364 DEBUG 23692 --- [nio-7070-exec-1] org.hibernate.SQL : select band0_.id as id1_1_0_, band0_.description as descript2_1_0_, band0_.founding_date as founding3_1_0_, band0_.name as name4_1_0_, band0_.version as version5_1_0_ from band band0_ where band0_.id=?
2020-04-11 15:28:04.367 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 5 gets played by band 5
2020-04-11 15:28:04.367 DEBUG 23692 --- [nio-7070-exec-1] org.hibernate.SQL : select band0_.id as id1_1_0_, band0_.description as descript2_1_0_, band0_.founding_date as founding3_1_0_, band0_.name as name4_1_0_, band0_.version as version5_1_0_ from band band0_ where band0_.id=?
2020-04-11 15:28:04.369 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 6 gets played by band 6
2020-04-11 15:28:04.370 DEBUG 23692 --- [nio-7070-exec-1] org.hibernate.SQL : select band0_.id as id1_1_0_, band0_.description as descript2_1_0_, band0_.founding_date as founding3_1_0_, band0_.name as name4_1_0_, band0_.version as version5_1_0_ from band band0_ where band0_.id=?
2020-04-11 15:28:04.372 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 7 gets played by band 7
2020-04-11 15:28:04.372 DEBUG 23692 --- [nio-7070-exec-1] org.hibernate.SQL : select band0_.id as id1_1_0_, band0_.description as descript2_1_0_, band0_.founding_date as founding3_1_0_, band0_.name as name4_1_0_, band0_.version as version5_1_0_ from band band0_ where band0_.id=?
2020-04-11 15:28:04.375 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 8 gets played by band 8
2020-04-11 15:28:04.376 DEBUG 23692 --- [nio-7070-exec-1] org.hibernate.SQL : select band0_.id as id1_1_0_, band0_.description as descript2_1_0_, band0_.founding_date as founding3_1_0_, band0_.name as name4_1_0_, band0_.version as version5_1_0_ from band band0_ where band0_.id=?
2020-04-11 15:28:04.378 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 9 gets played by band 9
2020-04-11 15:28:04.379 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 10 gets played by band 1
2020-04-11 15:28:04.379 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 11 gets played by band 2
2020-04-11 15:28:04.379 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 12 gets played by band 3
2020-04-11 15:28:04.379 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 13 gets played by band 4
2020-04-11 15:28:04.379 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 14 gets played by band 5
2020-04-11 15:28:04.379 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 15 gets played by band 6
2020-04-11 15:28:04.379 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 16 gets played by band 7
2020-04-11 15:28:04.379 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 17 gets played by band 8
2020-04-11 15:28:04.379 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 18 gets played by band 9
2020-04-11 15:28:04.379 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 19 gets played by band 1
2020-04-11 15:28:04.379 INFO 23692 --- [nio-7070-exec-1] ConcertController : Concert concert 20 gets played by band 2
2020-04-11 15:28:04.463 INFO 23692 --- [nio-7070-exec-1] i.StatisticalLoggingSessionEventListener : Session Metrics {
4769200 nanoseconds spent acquiring 1 JDBC connections;
0 nanoseconds spent releasing 0 JDBC connections;
2552200 nanoseconds spent preparing 10 JDBC statements;
24755400 nanoseconds spent executing 10 JDBC statements;
0 nanoseconds spent executing 0 JDBC batches;
0 nanoseconds spent performing 0 L2C puts;
0 nanoseconds spent performing 0 L2C hits;
0 nanoseconds spent performing 0 L2C misses;
0 nanoseconds spent executing 0 flushes (flushing a total of 0 entities and 0 collections);
495900 nanoseconds spent executing 1 partial-flushes (flushing a total of 0 entities and 0 collections)
}
[/Code]
Avoid Additional Queries
You can avoid this issue by using a JOIN FETCH clause that tells Hibernate to fetch the Concert and associated Band entities within the same query. You can do that by adding a method to your repository interface and defining a custom query using the @Query annotation.
xxxxxxxxxx
[Code]
public interface ConcertRepository extends JpaRepository<Concert, Long> {
("SELECT c FROM Concert c LEFT JOIN FETCH c.band")
List<Concert> getConcertsWithBand();
}
(path = "/concert")
public class ConcertController {
Logger logger = Logger.getLogger(ConcertController.class.getSimpleName());
private ConcertRepository concertRepo;
public List<Concert> getConcerts() {
List<Concert> concerts = this.concertRepo.getConcertsWithBand();
for (Concert c : concerts) {
logger.info("Concert "+c.getName()+" gets played by "+c.getBand().getName());
}
return concerts;
}
}
[/Code]
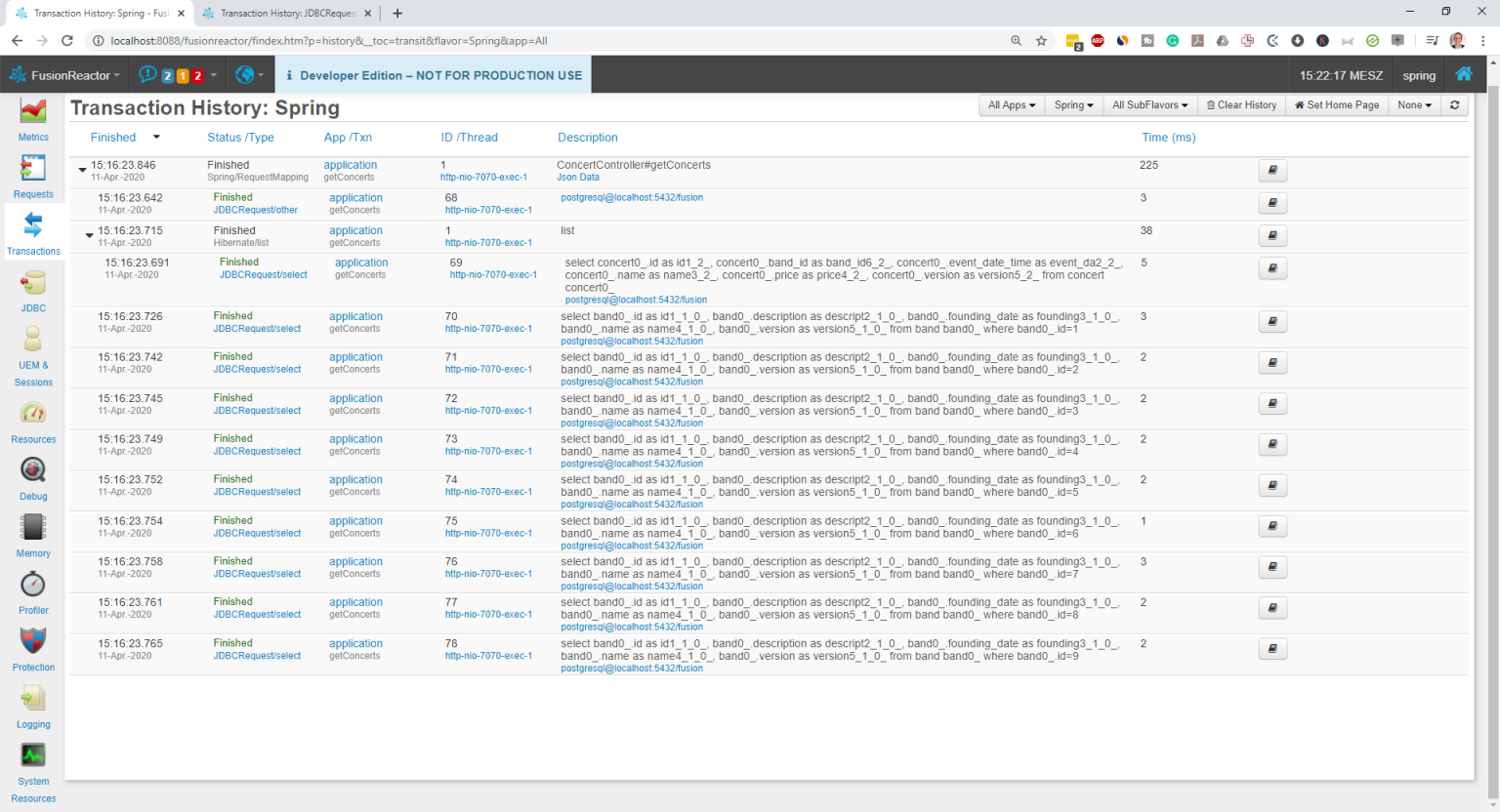
Instead of 10 queries, Hibernate now gets all information with only 1 query.
{kind=link}
Pitfall 2: Slow Database Queries
Slow queries are a common issue in all applications that store their data in a relational database. That’s why all databases provide an extensive set of tools to analyze and improve these queries.
Even though we can’t blame Spring Data JPA or Hibernate for these issues, we still need to find and fix these queries in our application. And that’s often not as easy as it might seem. Hibernate generates the executed SQL statements based on our JPQL queries. In general, the executed queries are efficient. But sometimes, the additional abstraction of JPQL hides performance problems that would be obvious, if we would write the SQL query ourselves.
The following JPQL query, for example, looks totally fine. We’re loading Concert entities and use multiple JOIN FETCH clauses.
xxxxxxxxxx
[Code]
public interface ConcertRepository extends JpaRepository<Concert, Long> {
("SELECT c FROM Concert c LEFT JOIN FETCH c.band b LEFT JOIN FETCH b.artists WHERE b.name = :band")
Concert getConcertOfBand(("band") String band);
}
[/Code]
Find Inefficient Queries
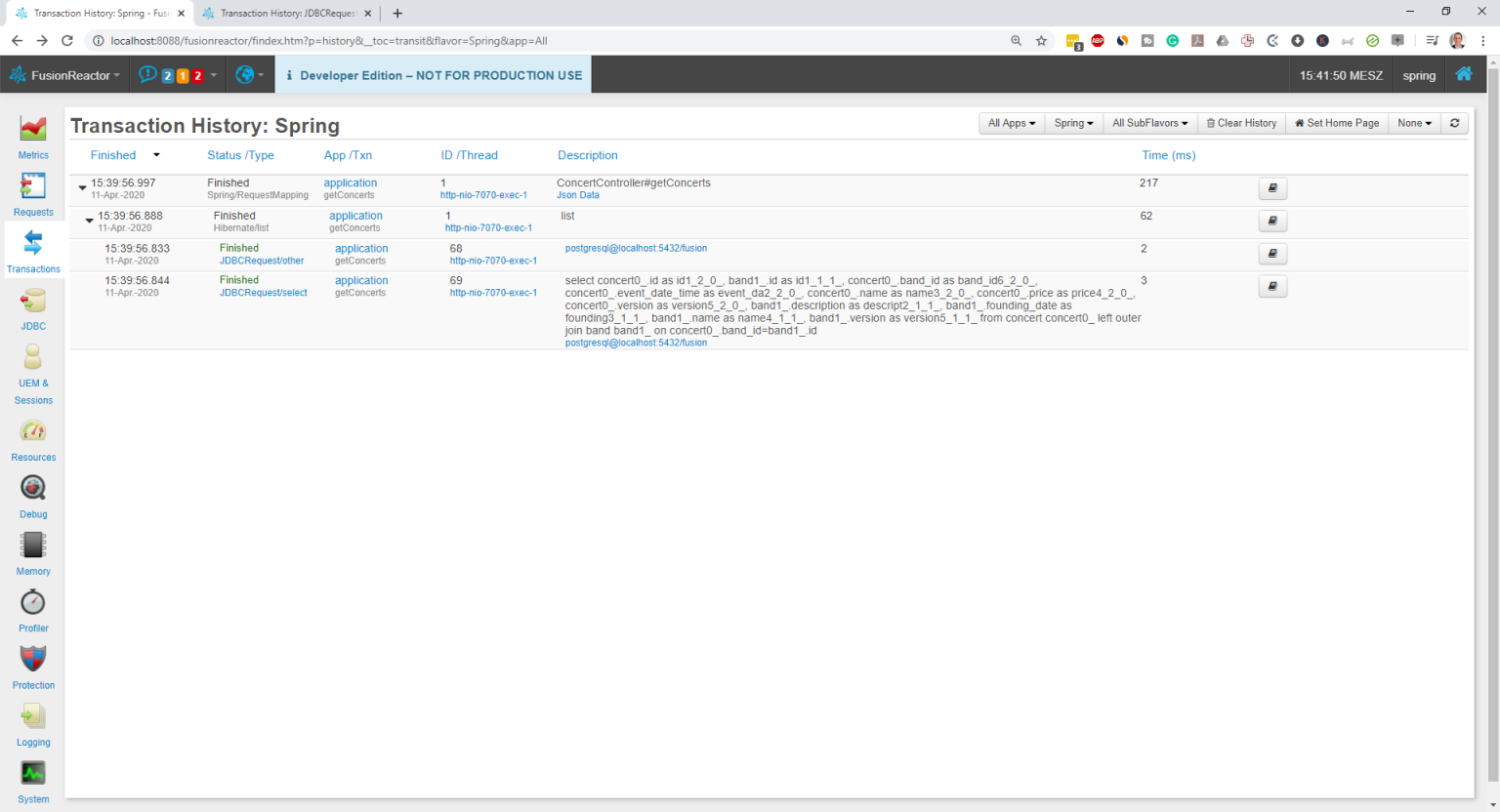
The problem becomes obvious if you activate the logging of SQL statements in Hibernate or take a look at the executed JDBC statements in FusionReactor.
{kind=link}
Hibernate has to select all columns mapped by an entity if you reference it in your SELECT clause or if you tell Hibernate to JOIN FETCH an association. In this case, the JPQL query that referenced 3 entities caused an SQL statement that selects 22 columns. These are a lot more columns than you might expect when you look at the JPQL query, and it gets worse if your entities map more columns or you JOIN FETCH more associations.
The JOIN FETCH clause creates another issue: The result set contains the product of all joined records. Due to that, such result sets often contain thousands of records.
Improve Inefficient Queries
The only way to fix this performance problem is to avoid these kinds of queries. You could try to use a smaller, use case-specific projection. Or you could split your query into multiple ones, e.g., one that fetches the Band entity with a JOIN FETCH clause for the artist attribute and another query for the Concert entity.
xxxxxxxxxx
[Code]
(path = "/concert")
public class ConcertController {
Logger logger = Logger.getLogger(ConcertController.class.getSimpleName());
private ConcertRepository concertRepo;
private BandRepository bandRepo;
public ConcertController(ConcertRepository orderRepo, BandRepository bandRepo) {
this.concertRepo = orderRepo;
this.bandRepo = bandRepo;
}
(path = "/name/{name}")
public List<Concert> getConcertOfBand(("name") String name) {
Band b = this.bandRepo.getBandWithArtists(name);
List<Concert> concerts = this.concertRepo.getConcertsOfBand(name);
if (concerts.isEmpty()) {
throw new NoResultException();
}
return concerts;
}
}
[/Code]
Pitfall 3: Too many write operations
Another common performance pitfall is the inefficient handling of write operations for multiple entities.
Let’s say you need to reschedule all concerts that were planned for the month of April. Using Java and Hibernate as your ORM framework, it feels natural to get a Concert entity object for each of these concerts and to change the eventDateTime attribute.
xxxxxxxxxx
[Code]
List<Concert> concerts = this.concertRepo.getConcertsScheduledFor(LocalDateTime.of(2020, 04, 01, 00, 00), LocalDateTime.of(2020, 04, 30, 23, 59));
for (Concert c : concerts) {
c.setEventDateTime(c.getEventDateTime().plusMonths(1));
}
[/Code]
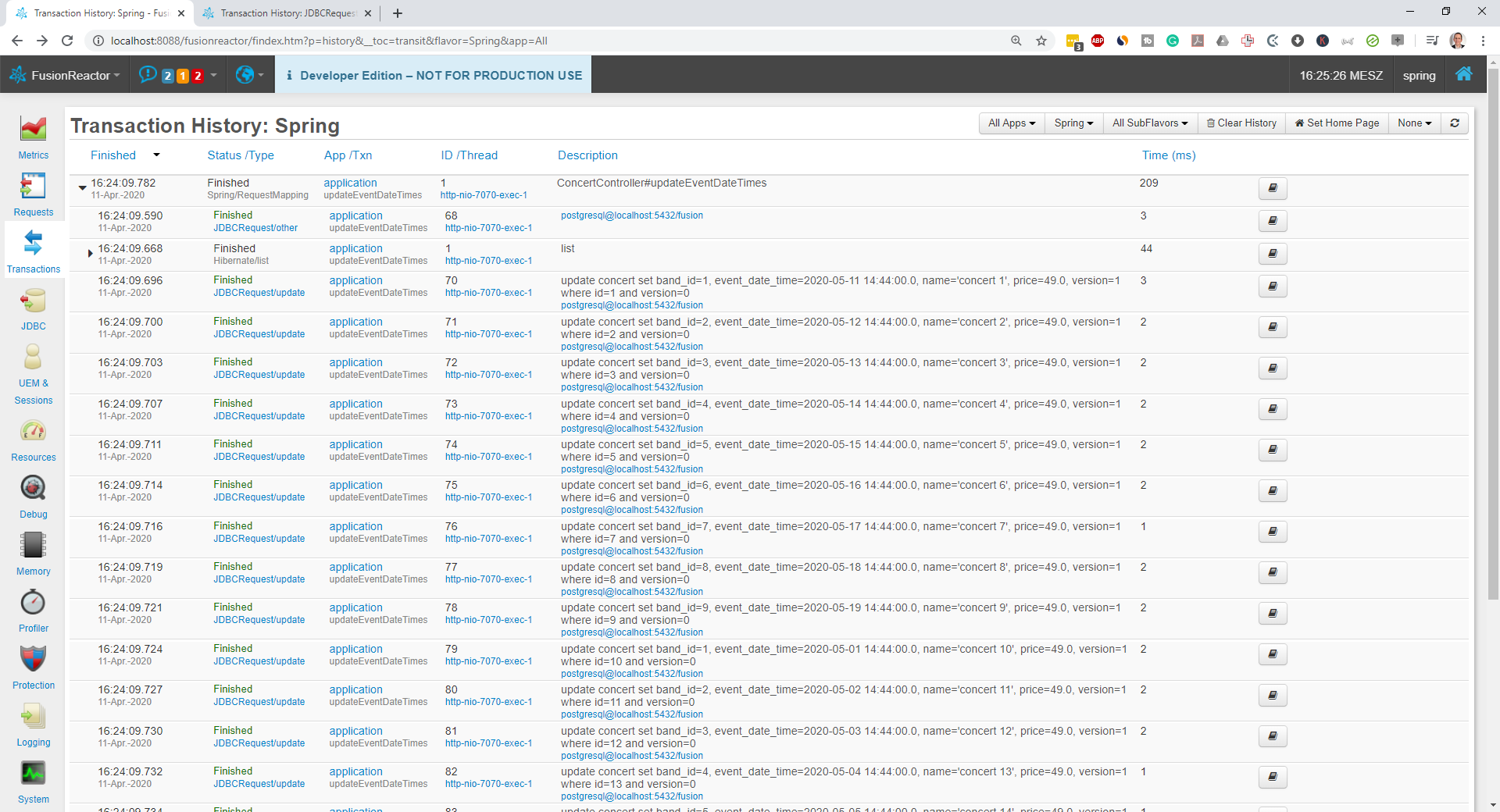
Find Inefficient Write Operations
But that would force Hibernate to execute an SQL UPDATE statement for each concert. Similar to the previous performance issues, this inefficiency is only visible, if you monitor the executed SQL statements.
{kind=link}
Reduce the Number of Write Operations
In SQL, you would write one SQL UPDATE statement that changes the value in the event_date_time column of all concerts that are scheduled for the month of April. That’s obviously the more efficient approach.
You can do the same with a native query in Hibernate. But before you do that, you should always call the flush() and clear() methods on your EntityManager. That ensures that your 1st level cache doesn’t contain any local copy of the data that your query will change.
[Code]
em.flush();
em.clear();
em.createNativeQuery("UPDATE concert SET event_date_time = event_date_time + INTERVAL '1 month'").executeUpdate();
[/Code]
Conclusion
As you have seen, Hibernate is easy to use, but it can also cause some unexpected performance problems. These are often hard to find in your code but very easy to see as soon as you monitor the executed SQL statements. If you use the right logging configuration, you can find these statements in your application log file. Or you can use FusionReactor’s Database Monitoring features and integrate these checks in your application monitoring strategy.
Published at DZone with permission of Thorben Janssen. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments