A 5-Minute Fix to Our CI/CD Pipeline That Saved Us 5 Hours a Day
A reminder that even the most obvious optimizations can hide in plain sight when you’re heads down building the next big thing.
Join the DZone community and get the full member experience.
Join For FreeIf you’ve ever worked at a startup, you know the rhythm: you’re in constant motion, juggling priorities, shipping fast, putting out small fires, and trying not to light new ones. It’s a bit like running a restaurant during dinner rush: the orders keep coming, and you’re too busy cooking to notice that the stove needs cleaning.
After months of sprinting to ship new features, first full-stack session recordings, then our MCP server, then support for annotated recording screens, and most recently, a browser extension and VS Code extension… We finally took a breath and looked at something we hadn’t touched in a while: our CI/CD pipelines.
Because we were so focused on shipping, small inefficiencies in our build pipeline survived longer than they should have. When we finally reviewed them, what started as a casual Friday chat about build times turned into a Monday-morning tweak that cut half an hour of wait time off every run.
The result? About 5 hours of developer wait time saved per day and some $$$ off our GitHub Actions bill.
It’s not a breakthrough, but it’s a reminder: even the most obvious optimizations can hide in plain sight when you’re heads down building the next big thing.
A Bloated CI/CD Pipeline
Our GitHub Actions pipeline had grown organically around our needs, but over time, it became bloated. Every push triggered a full build across frontend and multiple backend services, followed by release jobs that rarely mattered outside of main.
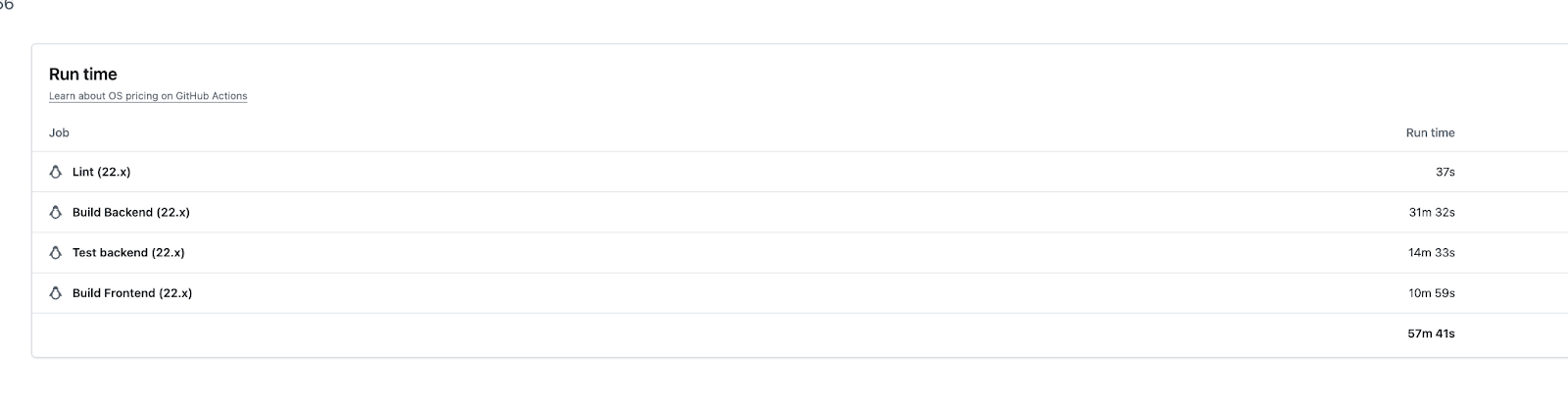
The end result was workflows that routinely took over an hour and a half to complete, consuming ~57 billed minutes per run, and ~30 minutes of developer wait time.
For developers waiting on feedback, this meant losing time just to see if a PR passed checks.
A Quick Primer on GitHub Actions
GitHub Actions are GitHub’s built-in CI/CD service, and it’s a fairly popular solution. But for those who are unfamiliar or using a different solution, here’s a very quick primer and some context.
With GH Actions, you define a workflow as a YAML file in your repository, and every time certain events happen (like a push, pull request, or tag), GitHub spins up virtual machines called runners to execute the jobs you specify.
Each job runs in its own environment (for example, Ubuntu or macOS) and can run in sequence or in parallel.
Pricing is based on the number of minutes runners are active, with different rates depending on the OS. For private repos, you get an included minute quota by plan; beyond that, you pay by OS: Linux baseline ≈ $0.008/min, Windows ≈ 2×, macOS ≈ 10×. Storage for artifacts is billed separately.
This makes it easy to get started, but it also means that long or redundant workflows can quietly rack up both developer wait time and monthly bills if left unchecked.
In our case, the pre-optimization pipeline consumed:
- Total run time: ~1 hour 45 minutes per push (~57mins billed time + ~31min waiting for ready to go builds)
- Billed minutes: ~57 minutes
- Cost per run: ~$0.46 (57 min × $0.008/min)
Of course, our daily jobs vary, and the monthly bills average out. But during “peak” release months, we could have up to 10 jobs/day, which would come out to ~$141/mo.
The real cost of unoptimized CI/CD pipelines
I’ve written before how time wasted on avoidable inefficiencies (e.g., tech debt, poor documentation, and brittle tooling) causes friction that can add up to even 8 hours/day lost.
Or if you’re counting it in dev salaries, that’s $13,445 per developer, per year (nb. I used the global average for a backend developer).
That's one of the main reasons why my focus is on dev tools that reduce context switching and ensure devs have every piece of data they need, when they need it.
CI/CD pipelines are no different: they’re supposed to accelerate delivery, but if left unchecked, they can quietly become a source of drag.
In our case, while shaving dollars off our bill is always welcome, that’s not the real value of this optimization: the real value in this small workflow change is time.
Cutting more than half an hour off every run means developers get feedback faster, ship features with less waiting, and stay in flow.
The Solution
The fix wasn’t complicated: we simply rethought when and how jobs should run.
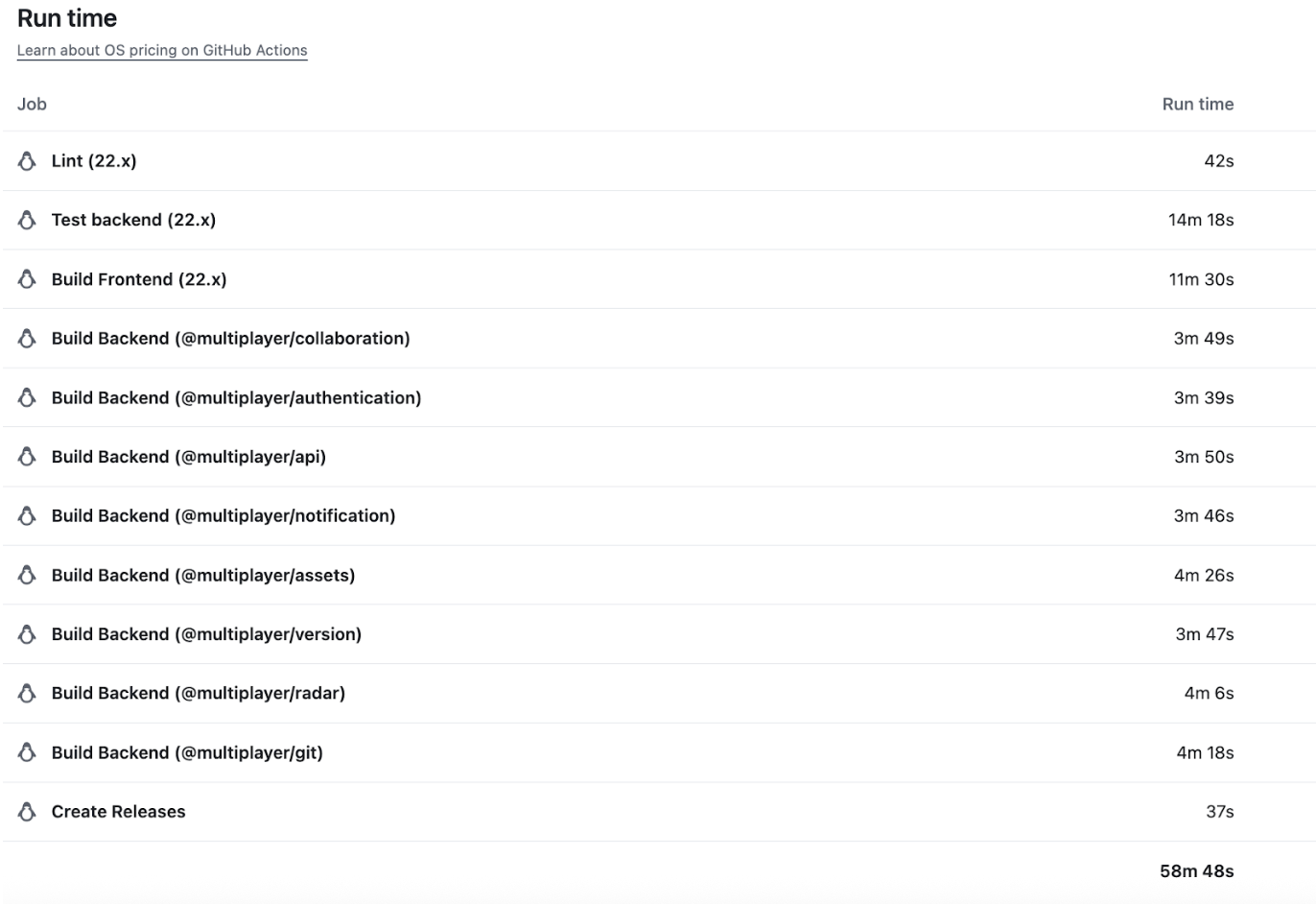
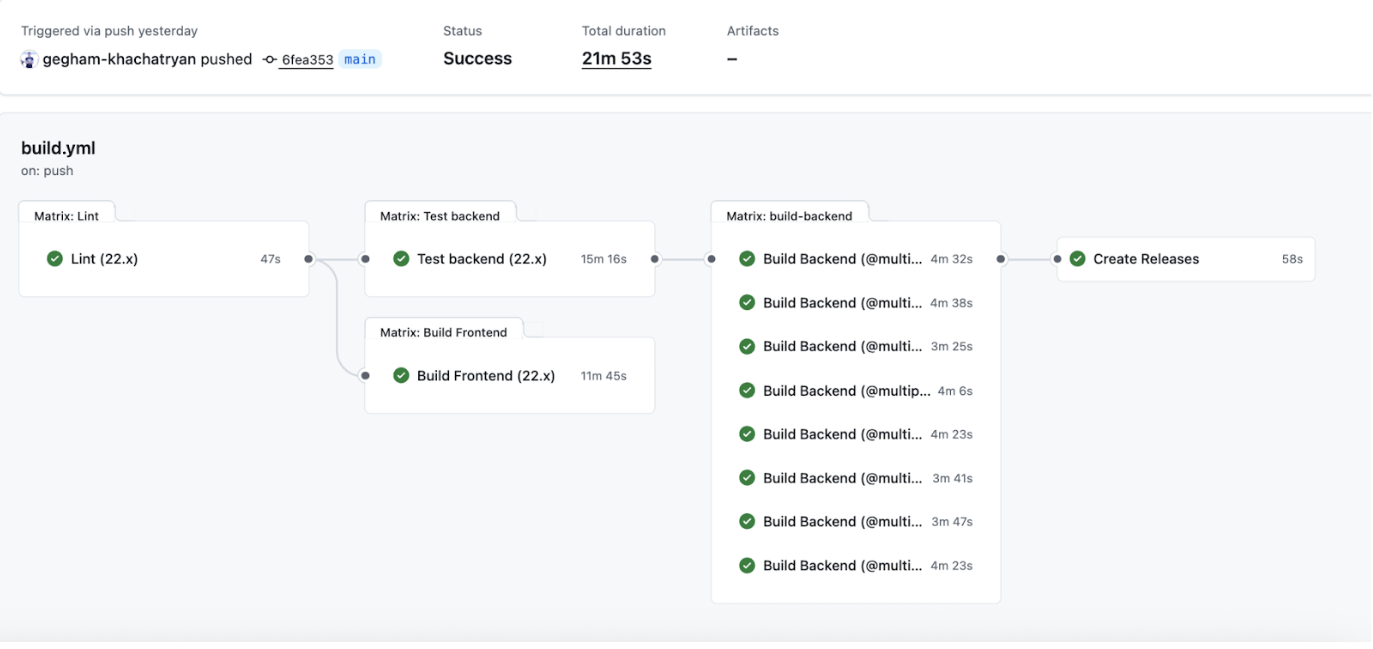
We split backend builds into parallel jobs to reduce memory pressure and cut wall-clock time, and changed our triggers so that lint and test jobs run automatically on PRs, while build and release jobs only run on main or when manually triggered.
With this setup, feature branches still get fast feedback, but we avoid wasting resources on builds that never ship.
While the resulting pipeline takes the same time to complete (~58 billed minutes), we saved our developers the extra, unnecessary wait time.
And for our feature branches, we can even omit some steps, which allowed us to reduce from 57 minutes to 15 minutes for some of the runs.
Conclusion
The pipeline isn’t perfect, and that’s okay. We’re not done yet.
Startups are built one small fix at a time. Every minute saved, every bottleneck reduced, compounds over time. Sometimes progress isn’t about a grand overhaul; it’s just about making tomorrow’s work a little smoother than today’s.
Reviewing internal processes (whether it’s building pipelines, debugging workflows, or team tooling) is one of the highest-leverage activities a team can invest in.
Optimizations don’t have to be flashy or complex.
Sometimes it’s the obvious changes that slip through the cracks. Taking the time to ask “Is there a more efficient way to do this?” can mean the difference between wasted hours and sustained velocity.
Opinions expressed by DZone contributors are their own.
Comments