Fork/Join Framework vs. Parallel Streams vs. ExecutorService: The Ultimate Fork/Join Benchmark
By
 ·
·
Interview
·
·
Interview
Likes
(0)
Likes
There are no likes...yet! 👀
Be the first to like this post!
It looks like you're not logged in.
Sign in to see who liked this post!
Comment
Save
16.8K Views
Join the DZone community and get the full member experience.
Join For Free
How does the Fork/Join framework act under different configurations?
Just like the upcoming episode of Star Wars, there has been a lot of excitement mixed with criticism around Java 8 parallelism. The syntactic sugar of parallel streams brought some hype almost like the new lightsaber we’ve seen in the trailer. With many ways now to do parallelism in Java, we wanted to get a sense of the performance benefits and the dangers of parallel processing. After over 260 test runs, some new insights rose from the data and we wanted to share these with you in this post.
{kind=link}
Fork/Join Framework vs. Parallel Streams vs. ExecutorService: The Ultimate Fork/Join Benchmark http://t.co/CMNfYZe58Z pic.twitter.com/6WExlmbyo6
— Takipi (@takipid) January 20, 2015
ExecutorService vs. Fork/Join Framework vs. Parallel Streams
A long time ago, in a galaxy far, far away.... I mean, some 10 years ago concurrency was available in Java only through 3rd party libraries. Then came Java 5 and introduced the java.util.concurrent library as part of the language, strongly influenced by Doug Lea. The ExecutorService became available and provided us a straightforward way to handle thread pools. Of course java.util.concurrent keeps evolving and in Java 7 the Fork/Join framework was introduced, building on top of the ExecutorService thread pools. With Java 8 streams, we’ve been provided an easy way to use Fork/Join that remains a bit enigmatic for many developers. Let’s find out how they compare to one another. We’ve taken 2 tasks, one CPU-intensive and the other IO-intensive, and tested 4 different scenarios with the same basic functionality. Another important factor is the number of threads we use for each implementation, so we tested that as well. The machine we used had 8 cores available so we had variations of 4, 8, 16 and 32 threads to get a sense of the general direction the results are going. For each of the tasks, we’ve also tried a single threaded solution, which you’ll not see in the graphs since, well, it took much much longer to execute. To learn more about exactly how the tests ran you can check out the groundwork section below. Now, let’s get to it.Indexing a 6GB file with 5.8M lines of text
In this test, we’ve generated a huge text file, and created similar implementations for the indexing procedure. Here’s what the results looked like: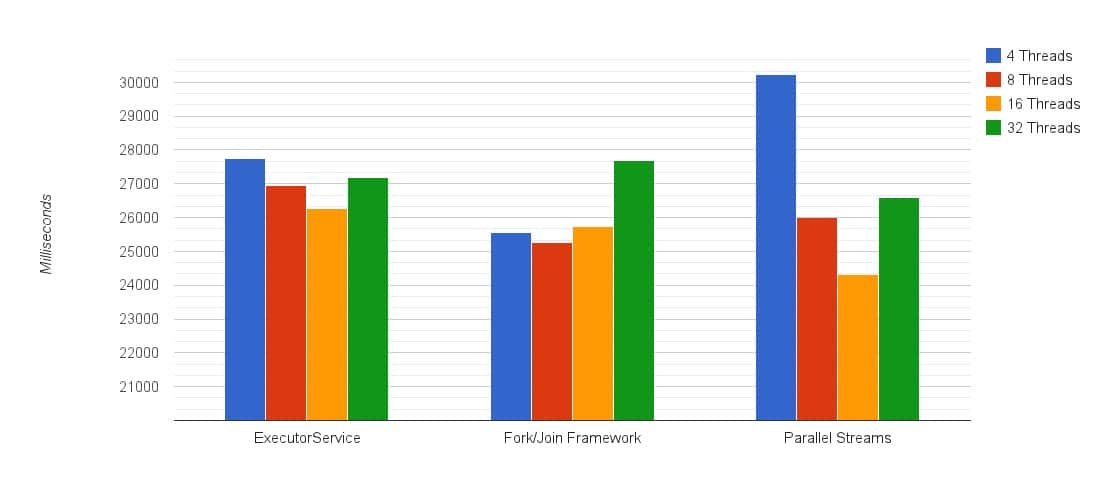 ** Single threaded execution: 176,267msec, or almost 3 minutes.
** Notice the graph starts at 20000 milliseconds.
** Single threaded execution: 176,267msec, or almost 3 minutes.
** Notice the graph starts at 20000 milliseconds.1. Fewer threads will leave CPUs unutilized, too many will add overhead
The first thing you notice in the graph is the shape the results are starting to take - you can get an impression of how each implementation behaves from only these 4 data points. The tipping point here is between 8 and 16 threads, since some threads are blocking in file IO, and adding more threads than cores helped utilize them better. When 32 threads are in, performance got worse because of the additional overhead.2. Parallel Streams are the best! Almost 1 second better than the runner up: using Fork/Join directly
Syntactic sugar aside (lambdas! we didn’t mention lambdas), we’ve seen parallel streams perform better than the Fork/Join and the ExecutorService implementations. 6GB of text indexed in 24.33 seconds. You can trust Java here to deliver the best result.3. But… Parallel Streams also performed the worst: The only variation that went over 30 seconds
This is another reminder of how parallel streams can slow you down. Let’s say this happens on machines that already run multithreaded applications. With a smaller number of threads available, using Fork/Join directly could actually be better than going through parallel streams - a 5 second difference, which makes for about an 18% penalty when comparing these 2 together.4. Don’t go for the default pool size with IO in the picture
When using the default pool size for Parallel Streams, the same number of cores on the machine (which is 8 here), performed almost 2 seconds worse than the 16 threads version. That’s a 7% penalty for going with the default pool size. The reason this happens is related with blocking IO threads. There’s more waiting going on, so introducing more threads lets us get more out of the CPU cores involved while other threads wait to be scheduled instead of being idle. How do you change the default Fork/Join pool size for parallel streams? You can either change the common Fork/Join pool size using a JVM argument: [java] -Djava.util.concurrent.ForkJoinPool.common.parallelism=16 [/java] (All Fork/Join tasks are using a common static pool the size of the number of your cores by default. The benefit here is reducing resource usage by reclaiming the threads for other tasks during periods of no use.) Or... You can use this trick and run Parallel Streams within a custom Fork/Join pool. This overrides the default use of the common Fork/Join pool and lets you use a pool you’ve set up yourself. Pretty sneaky. In the tests, we’ve used the common pool.5. Single threaded performance was 7.25x worse than the best result
Parallelism provided a 7.25x improvement, and considering the machine had 8 cores, it got pretty close to the theoretic 8x prediction! We can attribute the rest to overhead. With that being said, even the slowest parallelism implementation we tested, which this time was parallel streams with 4 threads (30.24sec), performed 5.8x better than the single threaded solution (176.27sec).What happens when you take IO out of the equation? Checking if a number is prime
For the next round of tests, we’ve eliminated IO altogether and examined how long it would take to determine if some really big number is prime or not. How big? 19 digits. 1,530,692,068,127,007,263, or in other words: one quintillion seventy nine quadrillion three hundred sixty four trillion thirty eight billion forty eight million three hundred five thousand thirty three. Argh, let me get some air. Anyhow, we haven’t used any optimization other than running to its square root, so we checked all even numbers even though our big number doesn’t divide by 2 just to make it process longer. Spoiler alert: it’s a prime, so each implementation ran the same number of calculations. Here’s how it turned out:{kind=link}
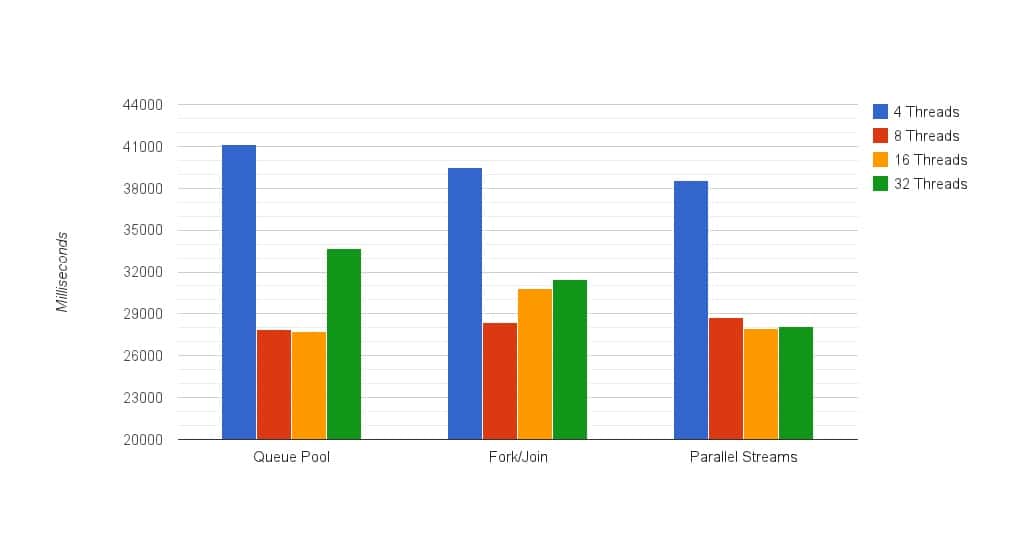 ** Single threaded execution: 118,127msec, or almost 2 minutes.
** Notice the graph starts at 20000 milliseconds
** Single threaded execution: 118,127msec, or almost 2 minutes.
** Notice the graph starts at 20000 milliseconds1. Smaller differences between 8 and 16 threads
Unlike the IO test, we don’t have IO calls here so the performance of 8 and 16 threads was mostly similar, except for the Fork/Join solution. We’ve actually ran a few more sets of tests to make sure we’re getting good results here because of this “anomaly” but it turned out very similar time after time. We’d be glad to hear your thoughts about this in the comment section below.2. The best results are similar for all methods
We see that all implementations share a similar best result of around 28 seconds. No matter which way we tried to approach it, the results came out the same. This doesn’t mean that we’re indifferent to which method to use. Check out the next insight.3. Parallel streams handle the thread overload better than other implementations
This is the more interesting part. With this test, we see again that the the top results for running 16 threads are coming from using parallel streams. Moreover, in this version, using parallel streams was a good call for all variations of thread numbers.4. Single threaded performance was 4.2x worse than the best result
In addition, the benefit of using parallelism when running computationally intensive tasks is almost 2 times worse than the IO test with file IO. This makes sense since it’s a CPU intensive test, unlike the previous one where we could get an extra benefit from cutting down the time our cores were waiting on threads stuck with IO.Conclusion
I’d recommend going to the source to learn more about when to use parallel streams and applying careful judgement anytime you do parallelism in Java. The best path to take would be running similar tests to these in a staging environment where you can try and get a better sense of what you’re up against. The factors you have to be mindful of are of course the hardware you’re running on (and the hardware you’re testing on), and the total number of threads in your application. This includes the common Fork/Join pool and code other developers on your team are working on. So try to keep those in check and get a full view of your application before adding parallelism of your own.Groundwork
To run this test we’ve used an EC2 c3.2xlarge instance with 8 vCPUs and 15GB of RAM. A vCPU means there’s hyperthreading in place so in fact we have here 4 physical cores that each act as if it were 2. As far as the OS scheduler is concerned, we have 8 cores here. To try and make it as fair as we could, each implementation ran 10 times and we’ve taken the average run time of runs 2 through 9. That’s 260 test runs, phew! Another thing that was important is the processing time. We’ve chosen tasks that would take well over 20 seconds to process so the differences will be easier to spot and less affected by external factors.What’s next?
The raw results are available right here, and the code is on GitHub. Please feel free to tinker around with it and let us know what kind of results you’re getting. If you have any more interesting insights or explanations for the results that we’ve missed, we’d be happy to read them and add it to the post. Originally posted on Takipi's blog
Stream (computing)
Framework
Testing
Implementation
Java (programming language)
Opinions expressed by DZone contributors are their own.
Comments