A Framework for Developing Service-Level Objectives: Essential Guidelines and Best Practices for Building Effective Reliability Targets
Here, we will go through a step-by-step approach to define SLOs with an example, followed by some challenges with SLOs.
Join the DZone community and get the full member experience.
Join For FreeEditor's Note: The following is an article written for and published in DZone's 2024 Trend Report, Observability and Performance: The Precipice of Building Highly Performant Software Systems.
"Quality is not an act, it's a habit," said Aristotle, a principle that rings true in the software world as well. Specifically for developers, this means delivering user satisfaction is not a one-time effort but an ongoing commitment. To achieve this commitment, engineering teams need to have reliability goals that clearly define the baseline performance that users can expect. This is precisely where service-level objectives (SLOs) come into picture.
Simply put, SLOs are reliability goals for products to achieve in order to keep users happy. They serve as the quantifiable bridge between abstract quality goals and the day-to-day operational decisions that DevOps teams must make. Because of this very importance, it is critical to define them effectively for your service. In this article, we will go through a step-by-step approach to define SLOs with an example, followed by some challenges with SLOs.
Steps to Define Service-Level Objectives
Like any other process, defining SLOs may seem overwhelming at first, but by following some simple steps, you can create effective objectives. It's important to remember that SLOs are not set-and-forget metrics. Instead, they are part of an iterative process that evolves as you gain more insight into your system. So even if your initial SLOs aren't perfect, it's okay — they can and should be refined over time.
Figure 1. Steps to define SLOs
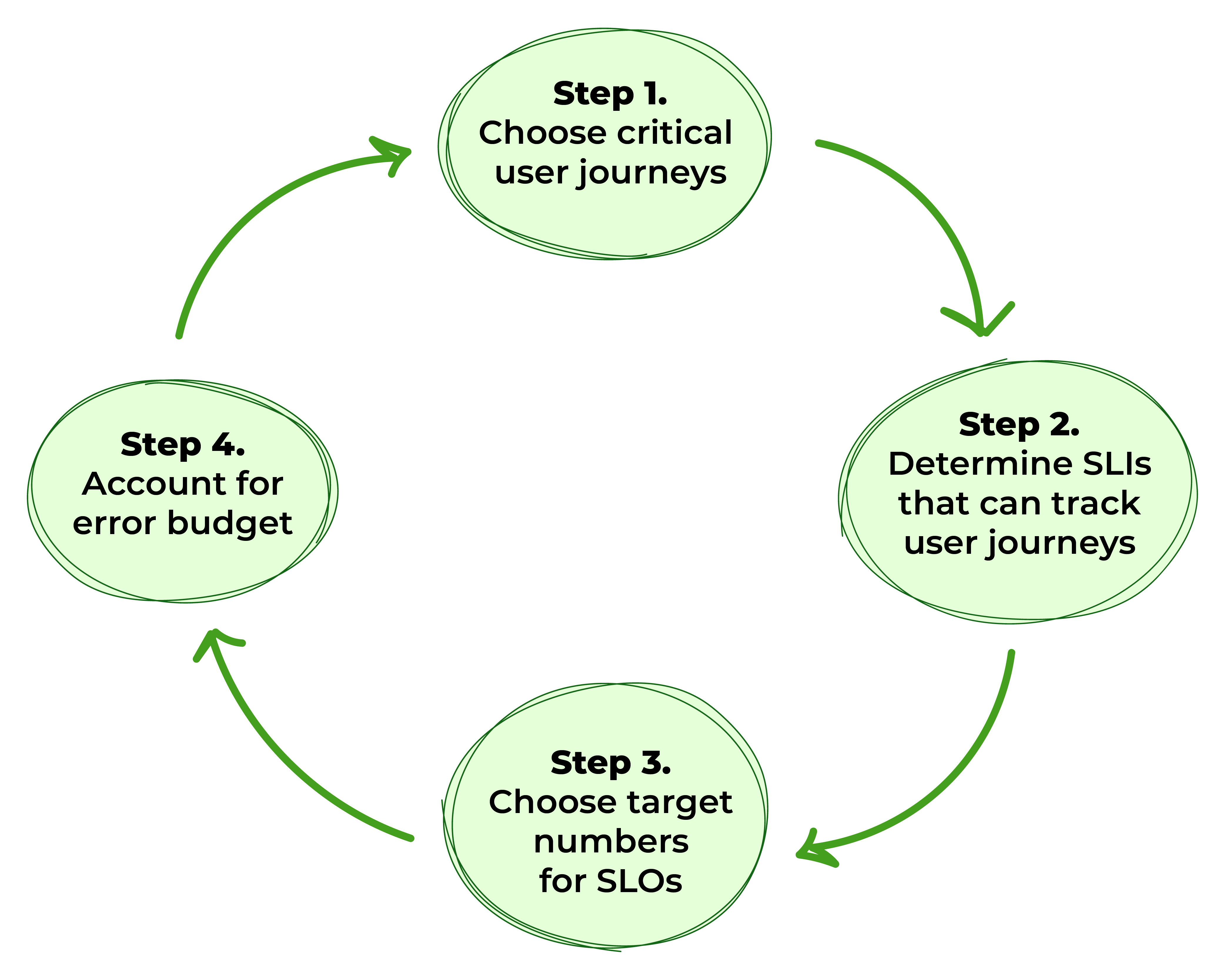
Step 1: Choose Critical User Journeys
A critical user journey refers to the sequence of interactions a user takes to achieve a specific goal within a system or a service. Ensuring the reliability of these journeys is important because it directly impacts the customer experience. Some ways to identify critical user journeys can be through evaluating revenue/business impact when a certain workflow fails and identifying frequent flows through user analytics.
For example, consider a service that creates virtual machines (VMs). Some of the actions users can perform on this service are browsing through the available VM shapes, choosing a region to create the VM in, and launching the VM. If the development team were to order them by business impact, the ranking would be:
- Launching the VM because this has a direct revenue impact. If users cannot launch a VM, then the core functionality of the service has failed, affecting customer satisfaction and revenue directly.
- Choosing a region to create the VM. While users can still create a VM in a different region, it may lead to a degraded experience if they have a regional preference. This choice can affect performance and compliance.
- Browsing through the VM catalog. Although this is important for decision making, it has a lower direct impact on the business because users can change the VM shape later.
Step 2: Determine Service-Level Indicators That Can Track User Journeys
Now that the user journeys are defined, the next step is to measure them effectively. Service-level indicators (SLIs) are the metrics that developers use to quantify system performance and reliability. For engineering teams, SLIs serve a dual purpose: They provide actionable data to detect degradation, guide architectural decisions, and validate infrastructure changes. They also form the foundation for meaningful SLOs by providing the quantitative measurements needed to set and track reliability targets.
For instance, when launching a VM, some of the SLIs can be availability and latency.
Availability: Out of the X requests to launch a VM, how many succeeded? A simple formula to calculate this is:
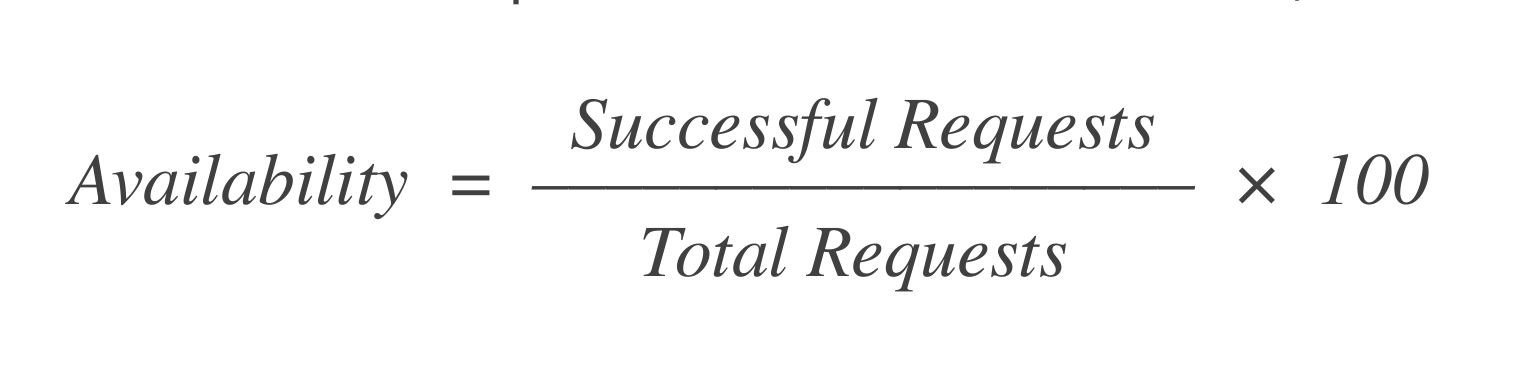
If there were 1,000 requests and 998 requests out of them succeeded, then the availability is = 99.8%.
Latency: Out of the total number of requests to launch a VM, what time did the 50th, 95th, or 99th percentile of requests take to launch the VM? The percentiles here are just examples and can vary depending on the specific use case or service-level expectations.
- In a scenario with 1,000 requests where 900 requests were completed in 5 seconds and the remaining 100 took 10 seconds, the 95th percentile latency would be = 10 seconds.
- While averages can also be used to calculate latencies, percentiles are typically recommended because they account for tail latencies, offering a more accurate representation of the user experience.
Step 3: Identify Target Numbers for SLOs
Simply put, SLOs are the target numbers we want our SLIs to achieve in a specific time window. For the VM scenario, the SLOs can be:
- The availability of the service should be greater than 99% over a 30-day rolling window.
- The 95th percentile latency for launching the VMs should not exceed eight seconds.
When setting these targets, some things to keep in mind are:
-
Using historical data. If you need to set SLOs based on a 30-day rolling period, gather data from multiple 30-day windows to define the targets.
- If you lack this historical data, start with a more manageable goal, such as aiming for 99% availability each day, and adjust it over time as you gather more information.
- Remember, SLOs are not set in stone; they should continuously evolve to reflect the changing needs of your service and customers.
-
Considering dependency SLOs. Services typically rely on other services and infrastructure components, such as databases and load balancers.
-
For instance, if your service depends on a SQL database with an availability SLO of 99.9%, then your service's SLO cannot exceed 99.9%. This is because the maximum availability is constrained by the performance of its underlying dependencies, which cannot guarantee higher reliability.
-
Challenges of SLOs
It might be intriguing to set the SLO as 100%, but this is impossible. A 100% availability, for instance, means that there is no room for important activities like shipping features, patching, or testing, which is not realistic. Defining SLOs requires collaboration across multiple teams, including engineering, product, operations, QA, and leadership. Ensuring that all stakeholders are aligned and agree on the targets is essential for the SLO to be successful and actionable.
Step 4: Account for Error Budget
An error budget is the measure of downtime a system can afford without upsetting customers or breaching contractual obligations. Below is one way of looking at it:
- If the error budget is nearly depleted, the engineering team should focus on improving reliability and reducing incidents rather than releasing new features.
- If there's plenty of error budget left, the engineering team can afford to prioritize shipping new features as the system is performing well within its reliability targets.
There are two common approaches to measuring the error budget: time based and event based. Let's explore how the statement, "The availability of the service should be greater than 99% over a 30-day rolling window," applies to each.
Time-Based Measurement
In a time-based error budget, the statement above translates to the service being allowed to be down for 43 minutes and 50 seconds in a month, or 7 hours and 14 minutes in a year. Here's how to calculate it:
-
Determine the number of data points. Start by determining the number of time units (data points) within the SLO time window. For instance, if the base time unit is 1 minute and the SLO window is 30 days:

-
Calculate the error budget. Next, calculate how many data points can "fail" (i.e., downtime). The error budget is the percentage of allowable failure.
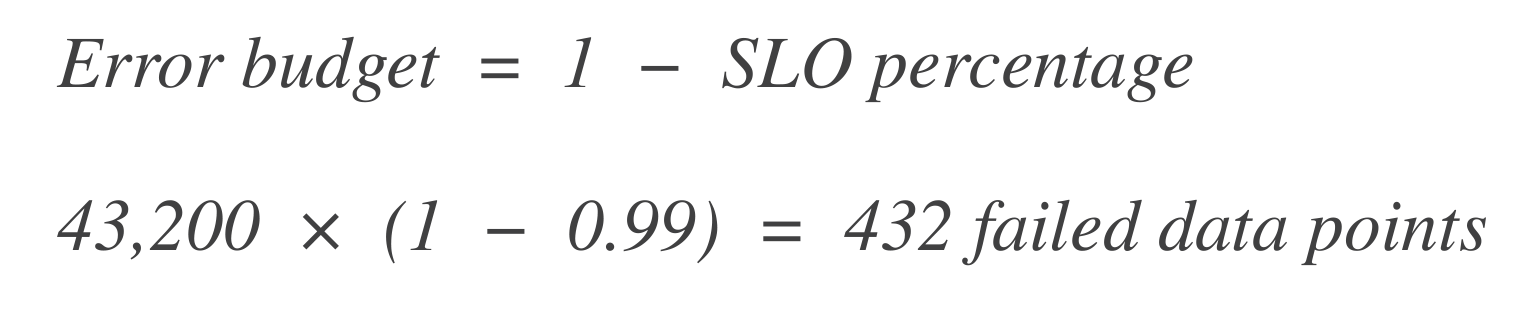
Convert this to time:
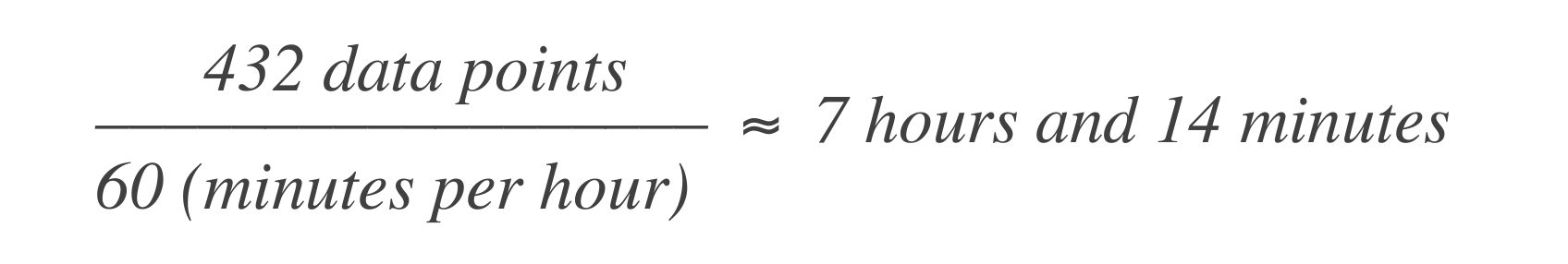
This means the system can experience 7 hours and 14 minutes of downtime in a 30-day window.
Last but not least, the remaining error budget is the difference between the total possible downtime and the downtime already used.
Event-Based Measurement
For event-based measurement, the error budget is measured in terms of percentages. The aforementioned statement translates to a 1% error budget in a 30-day rolling window.
Let's say there are 43,200 data points in that 30-day window, and 100 of them are bad. You can calculate how much of the error budget has been consumed using this formula:
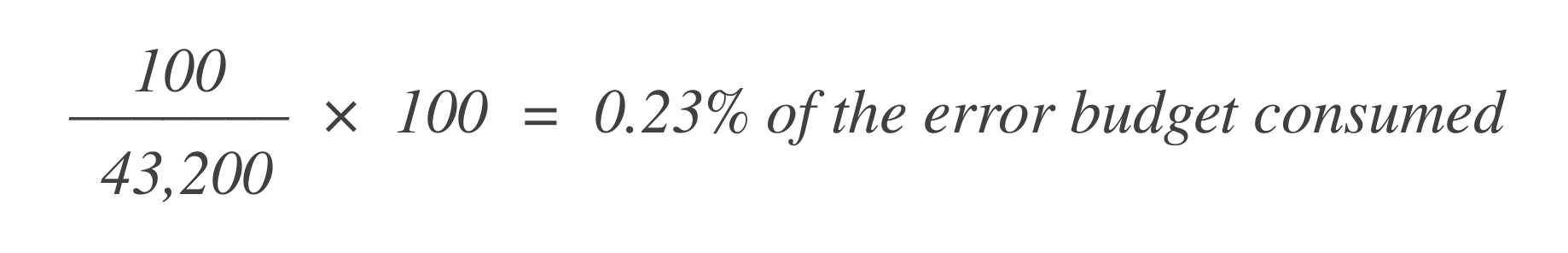
Now, to find out how much error budget remains, subtract this from the total allowed error budget (1%):
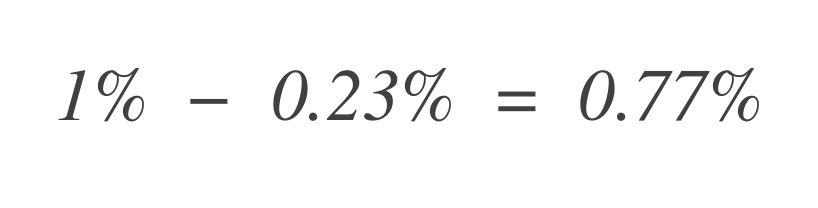
Thus, the service can still tolerate 0.77% more bad data points.
Advantages of Error Budget
Error budgets can be utilized to set up automated monitors and alerts that notify development teams when the budget is at risk of depletion. These alerts enable them to recognize when a greater caution is required while deploying changes to production. Teams often face ambiguity when it comes to prioritizing features vs. operations. Error budget can be one way to address this challenge. By providing clear, data-driven metrics, engineering teams are able to prioritize reliability tasks over new features when necessary. The error budget is among the well-established strategies to improve accountability and maturity within the engineering teams.
Cautions to Take With Error Budgets
When there is extra budget available, developers should actively look into using it. This is a prime opportunity to deepen the understanding of the service by experimenting with techniques like chaos engineering. Engineering teams can observe how the service responds and uncover hidden dependencies that may not be apparent during normal operations. Last but not least, developers must monitor error budget depletion closely as unexpected incidents can rapidly exhaust it.
Conclusion
Service-level objectives represent a journey rather than a destination in reliability engineering. While they provide important metrics for measuring service reliability, their true value lies in creating a culture of reliability within organizations. Rather than pursuing perfection, teams should embrace SLOs as tools that evolve alongside their services. Looking ahead, the integration of AI and machine learning promises to transform SLOs from reactive measurements into predictive instruments, enabling organizations to anticipate and prevent failures before they impact users.
Additional resources:
-
Implementing Service Level Objectives, Alex Hidalgo, 2020
-
"Service Level Objects," Chris Jones et al., 2017
-
"Implementing SLOs," Steven Thurgood et al., 2018
This is an excerpt from DZone's 2024 Trend Report, Observability and Performance: The Precipice of Building Highly Performant Software Systems.
Read the Free Report
Opinions expressed by DZone contributors are their own.
Comments