From 13,000 to 20,000+ Endpoints: Architecting Forensics for the Remote Workforce
Scale enterprise forensics by abandoning full-disk images in favor of automated, surgical artifact collection via EDR and cloud storage.
Join the DZone community and get the full member experience.
Join For FreeTraditional forensic processes fail when dealing with a large number of devices (over 20,000), such as in Fortune 500–level organizations. At that scale, the idea of taking a full disk image of a 512 GB laptop over a VPN is virtually impossible before the device shuts down, the user restarts it, or the legal window expires.
To overcome the physics bottleneck (bandwidth), we need to reverse how we think about remote data collection. Instead of bringing all the data to the tool, we need to send the tool to the data.
At large-scale enterprises, the problem isn’t just bandwidth — it’s also the amount of time investigators spend per case and how many cases occur simultaneously. When 100+ alerts are triggered at once, the organization needs an automated, repeatable “first 30 minutes” process that produces consistent output from all endpoints regarding artifact collection, artifact hashing, and artifact enrichment—without requiring manual triage or additional data requests.
Architecture: The Surgical Artifact Collection Process
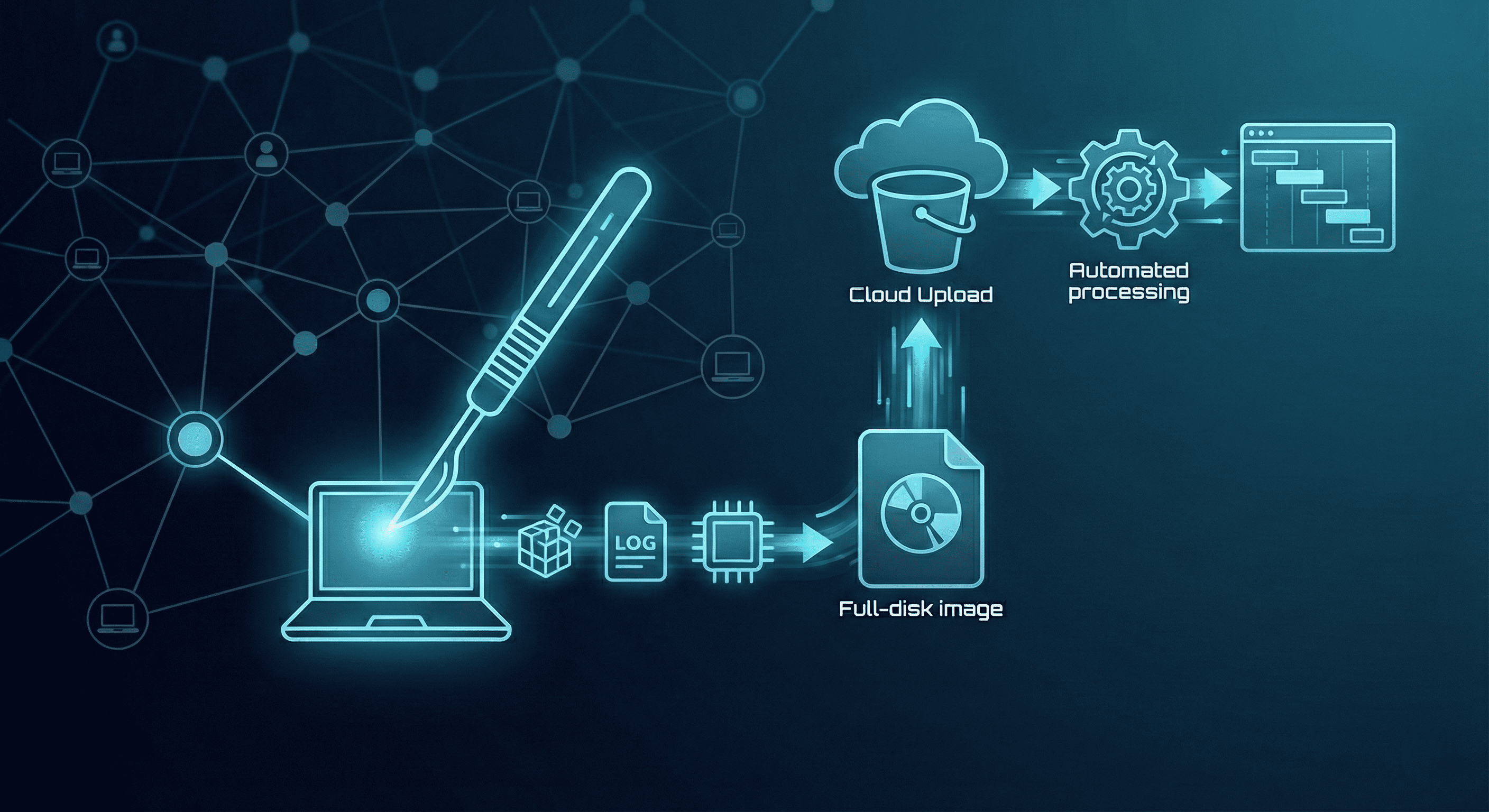
Instead of collecting a full disk image, we build a process that collects only high-value artifacts (MFT, registry, event logs, RAM), dramatically reducing transferred data (from 500 GB to under 2 GB) and accelerating investigations.
Artifacts should be tiered based on severity and volatility:
- Tier-0 (volatile): RAM, running processes, network connections
- Tier-1 (OS artifacts): Event logs, registry hives, scheduled tasks
- Tier-2 (file system artifacts): Master File Table, USN Journal, browser cache
- Tier-3 (selective content pull): Suspect binaries, LNKs, prefetch files, persistence scripts
This allows “collect small and fast” by default, and “collect deep” only when evidence justifies it.
1. The Trigger (EDR Integration)
Manual tickets no longer scale. Collection must be initiated automatically by the EDR system (e.g., CrowdStrike, SentinelOne, Tanium).
Process:
- CrowdStrike detects Mimikatz running on Host A.
- CrowdStrike sends a trigger to the Forensic Orchestrator (SOAR platform).
- The Forensic Orchestrator tags the asset as “under investigation.”
To prevent unnecessary or runaway collections, organizations must establish guardrails:
- Rate limits: e.g., no more than 50 simultaneous collections per geographic region
- Confidence thresholds: e.g., severity “High” or correlation score ≥ 80%
- Cooldown windows: e.g., do not recollect from the same device within 24 hours unless escalated
2. The Agent (The Forensic Surgeon)
The EDR system delivers a specialized forensic binary (e.g., compiled Velvet/KAPE or a Python-based collector) via a Live Response channel. The binary runs entirely in memory, executes the collection process, and then terminates.
Collection Manifest
A JSON document defines exactly what data should be collected. This enables dynamic modification of collection scope without recompiling the binary.
Security Requirements
To ensure the agent is secure:
- Sign the collector code and verify the signature at runtime
- Use the least privilege necessary
- Generate a detailed audit log including:
- Timestamp
- Artifact list
- Bytes collected
- SHA-256 hashes of collected artifacts
- Upload success status
Include a self-destruct capability:
- Securely remove temporary files
- Wipe staging directories
- Terminate cleanly, even if partial collection occurred
3. The Transport (Off-VPN Uploads)
Using a corporate VPN concentrator to transfer forensic data can overwhelm the network.
Methodology:
The agent uploads collected artifacts directly to a cloud storage bucket (e.g., AWS S3 or Azure Blob Storage) using a pre-generated URL.
Security Model:
The storage bucket is write-only. The agent can upload evidence but cannot enumerate or read other files, preventing compromised hosts from exfiltrating unrelated evidence.
Handling Unmanaged Devices & BYOD
What if a contractor uses a personal MacBook? You cannot install permanent EDR or asset management agents.
Solution: The One-Click Web Collector
- Provide a simple web interface that generates a one-time executable.
- The investigator sends a secure link to the user.
- The user runs the collector.
- The collector gathers required artifacts (e.g., browser history, application logs such as Citrix Receiver logs).
- Data is encrypted locally using a public key (preventing tampering), then uploaded to the cloud.
Automation and Analysis
Once the ~2 GB “Surgical Image” lands in the cloud, automation begins.
Auto-Processing:
A Lambda function triggers Plaso or Zimmerman tools to parse artifacts into a timeline.
The 30-Minute Promise:
When the investigator opens the case, the timeline is already generated. Instead of watching a progress bar, they see actionable insights (e.g., “User downloaded evil.exe at 10:00 AM”).
Chain of Custody: Legal Considerations
In remote environments, “who physically touched the laptop” becomes less relevant. Chain of Custody (CoC) is digital.
Hash Chain
- The agent calculates SHA-256 of the MFT before upload.
- Cloud ingestion recalculates SHA-256 on receipt.
- If hashes match, integrity is verified.
Tip: Document the exact EDR Command ID used to initiate collection. This proves the initiating admin was an authorized service account.
Signed Attestation of Collection
The collector generates a signed JSON attestation containing:
- Artifact hashes
- Timestamp of collection
- Collector version
- Unique device identifier
This attestation is stored immutably alongside evidence. In case of dispute, you can prove both:
- Integrity (hash validation)
- Provenance (signed collector + authenticated trigger identity)
Conclusion
Scaling forensics to 20,000 devices is not about buying more hard drives. It requires moving beyond the “dead box” paradigm.
By using automated, surgical artifact extraction through EDR channels, investigation time can shrink from days to minutes — regardless of device location.
Ultimately, the goal is a closed loop:
- Detections trigger surgical collections
- Collections automatically trigger artifact parsing
- Parsing generates enriched investigative summaries
- Validated findings feed back into detection and response playbooks
Over time, the organization builds a true Forensics-at-Scale capability — a consistent, defensible, and fast method of collecting evidence across all environments, just as reliably as telemetry is collected from endpoints.
Opinions expressed by DZone contributors are their own.
Comments