Taming Gen AI Video: An Architectural Approach to Addressing Identity Drift and Hallucination
Most Gen AI tools treat video as stateless images. Discover how better architectures, identity conditioning, and state-aware pipelines make AI video production reliable.
Join the DZone community and get the full member experience.
Join For FreeIf you've spent any time experimenting with generative AI video tools like Runway or Google's Veo, you've seen the magic. You've also, almost certainly, hit the architectural roadblocks.
A character's face subtly morphs from one scene to the next until they’re unrecognizable by the tenth clip. Objects you never prompted mysteriously pop up in the background. These aren't just minor bugs; they are critical consistency failures that can derail any serious AI video project.
We call it "hallucination" when large language models (LLMs) invent facts. In AI video production, this phenomenon manifests as identity drift (unwanted character changes) and prompt-related artifacting (two chairs in the frame instead of one).
Such failures remain the greatest challenge for AI video production companies, causing hours of re-rolling and editing.
That's why I decided to look into the underlying causes of the Gen AI video model hallucinations. The architecture, as expected, proved to be the source of the problem.
The Core Architectural Failure: Stateless, Feed-Forward Generation
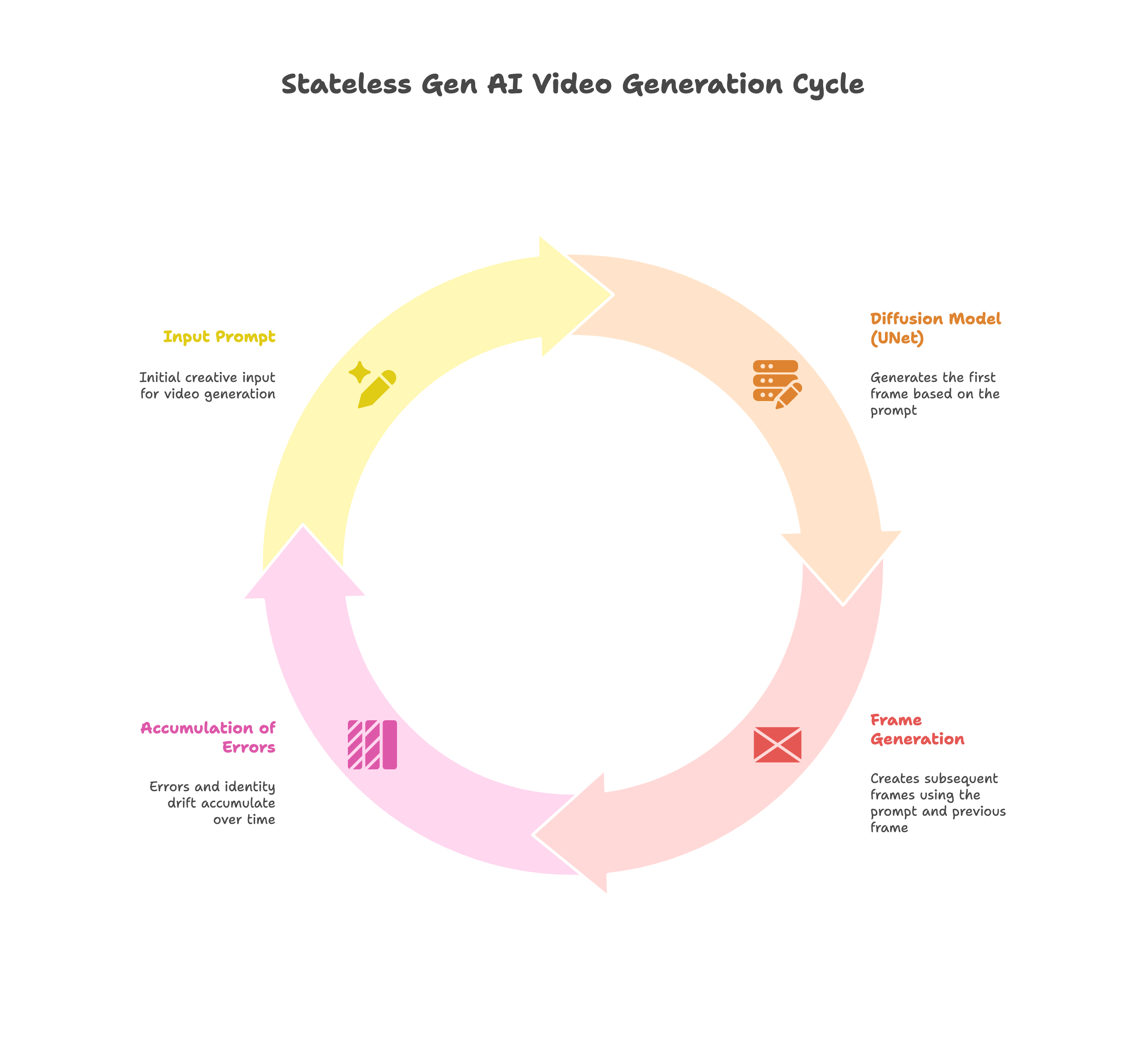
Many early — and still widely used — Gen AI video tools treat video as a sequence of loosely connected images. In practice, they often follow a largely stateless, feed-forward chain:
- Generate Frame 1 based on a prompt
- Look at Frame 1 (and the prompt) to generate Frame 2
- Inspect Frame 2 (and the prompt) to generate Frame 3... and so on
There are newer research systems that try to generate several seconds of video with a more global sense of time and motion. But in the commercial tools you’re likely to use today, the process above is still the norm: each frame is generated by mostly looking at the previous one, plus the prompt. This is equivalent to having a dozen different artists draw sequential frames of a cartoon, with each artist only seeing the previous frame. The end result is "Chinese whispers" at the system level.

The architecture described above has two major flaws:
- Stateless operation. Each new frame is treated as a separate creative task. Gen AI lacks a persistent "mental model" or state of the character. It doesn't know it's "the same guy" from 50 frames ago.
- Error accumulation. Any minor deviation in Frame 2 — a slightly different eye color, a minor adjustment to a jacket's zipper — is baked into the input for Frame 3. The deviation amplifies in Frame 4, and by Frame 100 the character has "drifted" into a completely different person.
The "World Model" Problem: Diffusion vs. 3D Reality
The second major issue, prompt-related artifacting, stems from the models' inherent characteristics.
Most modern Gen AI tools rely on diffusion models. At their core, these models use a specialized neural network architecture — typically a UNet — as the main "engine." The UNet is trained with random noise and then "denoise" it step by step until it matches the prompt. By definition, such models are generative, meaning the UNet fills in gaps with plausible data from its latent space.
When you type "a cat sitting on a sofa," the model's training data "knows" (via statistical correlation) that sofas are frequently placed next to lamps, potted plants, or end tables. The model is not "disobeying" your prompt by adding a lamp; rather, its UNet is "helpfully" creating a more complete, probable scene based on its training. Without a strong, negative-weighted prompt, the default behavior is to embellish.

This "filling the gaps" issue is exacerbated by a 2D-versus-3D problem. Models trained on flat, 2D video clips lack a fundamental understanding of 3D space, object permanence, and physics. They can't reliably distinguish "a camera panning past a motorcycle" from "a motorcycle hovering while the background moves." The lack of a true "world model" causes the spatial inconsistencies and hallucinations that plague many generative outputs.
Architectural Solutions for State and Consistency
The good news is that a new generation of AI models for video production is being built to solve these problems by injecting states, enforcing consistency, and improving understanding of the physical world. Let's look at these solutions in greater detail.

Solution #1: Injecting State Through Reference Adapters (e.g., IP-Adapter)
The most common "fix" users are told to apply is "use a reference image." From an architectural standpoint, this is a form of explicit state injection.
We’re not talking about simple image pasting here. Techniques like Image Prompt Adapter (IP-Adapter) encode the reference image and inject its features directly into the diffusion model's cross-attention layers — fundamental components of the UNet (the denoising engine).
Essentially, you're "conditioning" the denoising process. At each step, the adapter "reminds" the UNet of the visual features it should match, providing a strong, persistent reference signal that anchors the character's identity and significantly reduces drift.
Solution #2: Parameter-Efficient Fine-Tuning (PEFT) for Recurring Assets
A reference image alone is insufficient for branding, mascots, or recurring protagonists. The most reliable solution is to "teach" the base model your character. This is where parameter-efficient fine-tuning (PEFT) techniques, particularly low-rank adaptation (LoRa), come in.
Instead of retraining the entire multi-billion parameter model (which is computationally impractical for most), you "freeze" the baseline. The LoRa then trains small, low-rank matrices that are added to selected weight matrices — often in the model's attention layers — rather than updating the entire set of parameters.
These tiny matrices (often only a few megabytes) learn a new, unique concept, such as a new token like <my-company-mascot>. When you include this token in your prompt, the LoRa adapter "guides" the diffusion process to produce your desired character with high accuracy. This is the pinnacle of consistency: making the character a native concept within the model itself.
Solution #3: From Stateless to State-Aware (Persistent Memory)
The most fundamental architectural change is the transition from stateless, feed-forward chains to models with recurrent state.
Recent research and commercial platforms — including newer generations from vendors such as Runway — are moving toward architectures with persistent “memory.” This is similar to the transition from basic neural networks to recurrent neural networks (RNNs) or transformers in NLP. Conceptually, the model produces a “hidden state” tensor alongside Frame N and reuses that state when generating Frame N+1.
This hidden state serves as the model's memory, preserving temporal context, character details, and scene information over time. This is a true video model, not just an image-sequence generator, and it is critical to resolving long-term temporal consistency.
For readers who want to go deeper into the building blocks behind these techniques, it’s worth looking up IP-Adapter (image-conditioned diffusion via cross-attention) and LoRa as two of the most widely used methods for conditioning and fine-tuning diffusion models in practice.
A Pragmatic Engineering Toolkit for Today's Models

While we wait for these new architectures to perfect 3D world models, AI video creators can adopt an engineering mindset to "debug" and "guide" existing platforms:
Prompt Engineering as Strict Specification
If you want to create realistic AI videos, treat your prompt like a technical spec. A vague prompt ("a woman in an office") invites latent-space ambiguity. A strong prompt is a constraint:
"Medium shot, 16:9, of a woman with red hair in a bun (ID-Ref-789), wearing a blue blazer. She is standing and writing on a large glass whiteboard in a modern, sunlit meeting room. The frame contains *only* the woman, the whiteboard, and one black marker. The background is a clean, blurred window wall."
Use negative prompts as explicit "unit test failures" (e.g., neg: no_other_people, no_chairs, no_desks, no_laptops, no_coffee_cups).
The "Shot" as a Coherent Unit
Do not rely on a single, continuous generation to maintain perfect consistency, even if the tool supports a maximum length of 10-16 seconds. The model's state will drift over time. The better approach is to think like a video editor: create individual, short shots (e.g., 3-5 seconds), each with its own re-initialized state. Stitching these shorter, more controlled clips in a traditional editor is far more effective because it resets error accumulation with each cut.
The "glitches" in AI video are not just bugs; they are the expected side effects of first-generation architectures. Solving identity drift and hallucination isn't a "user" problem; it's an engineering challenge.
We are witnessing a rapid architectural transition: from stateless, feed-forward image chains to state-aware, temporally recurrent, and (eventually) 3D-conscious video models.
Meanwhile, the role of the "AI video creator" is rapidly evolving into that of an "AI systems integrator" — using tools such as reference adapters, LoRas, and strict prompt specifications to debug, constrain, and guide these powerful but imperfect generative systems.
Opinions expressed by DZone contributors are their own.
Comments