How GenAI Can Eliminate SME Bottlenecks in Enterprise Systems
An AI-powered system, a knowledge-enabled system to explain enterprise code, reducing SME dependency and accelerating productivity.
Join the DZone community and get the full member experience.
Join For FreeIn large-scale enterprises, tribal knowledge often stalls developer productivity and slows operational agility. Subject matter experts (SMEs) become bottlenecks when critical business logic and configuration decisions live only in legacy codebases or in the minds of a few veterans.
This article presents an architecture that leverages GraphCodeBERT embeddings, FAISS vector search, and large language models (LLMs) like Sonnet or Claude to transform complex enterprise logic into conversational explanations. Drawing on real-world use cases in asset lifecycle processing and internal platform operations, it outlines a scalable, GenAI-driven approach to overcoming SME bottlenecks and accelerating engineering velocity.
The Problem: Repetitive Questions and SME Bottlenecks
All organizations battle with these very same basic questions:
- What does this flag set?
- Why has this asset been reported as capital?
- Who disrupted this thought, and when?
All of these questions become epic Slack threads, exhausting 1:1s, or dives into convoluted code histories. It comes at a steep price: 3–5 weekly SME-hours spent explaining logic.
New hire onboarding latencies are wrestling to grasp tribal knowledge.
Risk of getting incorrect assumptions and causing operational mistakes.
SMEs become human bottlenecks, and their knowledge becomes valuable institutional knowledge that is best transferred to everyone.
Why Code Isn't Readable Knowledge
Even though business rules are in code, they are usually not accessible or readable to non-techies:
- Code is computer-readable, not analyst- or human-readable.
- Configuration logic gets lost in YAML files, domain-specific languages (DSLs), or nested conditionals.
- Version control histories only show what changed, but not why or how.
Example:
A finance analyst asks: "Why aren't volume snapshots being capitalized?" The answer lies within a 50-line Java function, last updated six months ago, with the tag infra_type=cache_tier_4. This requires time and extensive code familiarity to traverse.
Solution Overview: AI-Native Explainer Using Retrieval-Augmented Generation (RAG)
To resolve the issues mentioned above, we propose an in-house question-answering system built using GenAI components:
Instead of interrupting an SME, users simply inquire: "Why is volume_type=snapshot excluded from monthly capex?"
The system responds with a justification related to relevant code snippets, GitHub commit titles, and recent configurations.
| component | purpose |
|---|---|
|
GraphCodeBERT |
Code-aware vector embeddings |
|
FAISS/ PineCone/ Weavite |
Fast vector similarity search |
|
Bedrock LLM (Sonnet) |
Natural language explanation |
|
MCP (Model Context Protocol) |
Bundles code + context |
|
AWS Lambda + API Gateway |
Query endpoint |
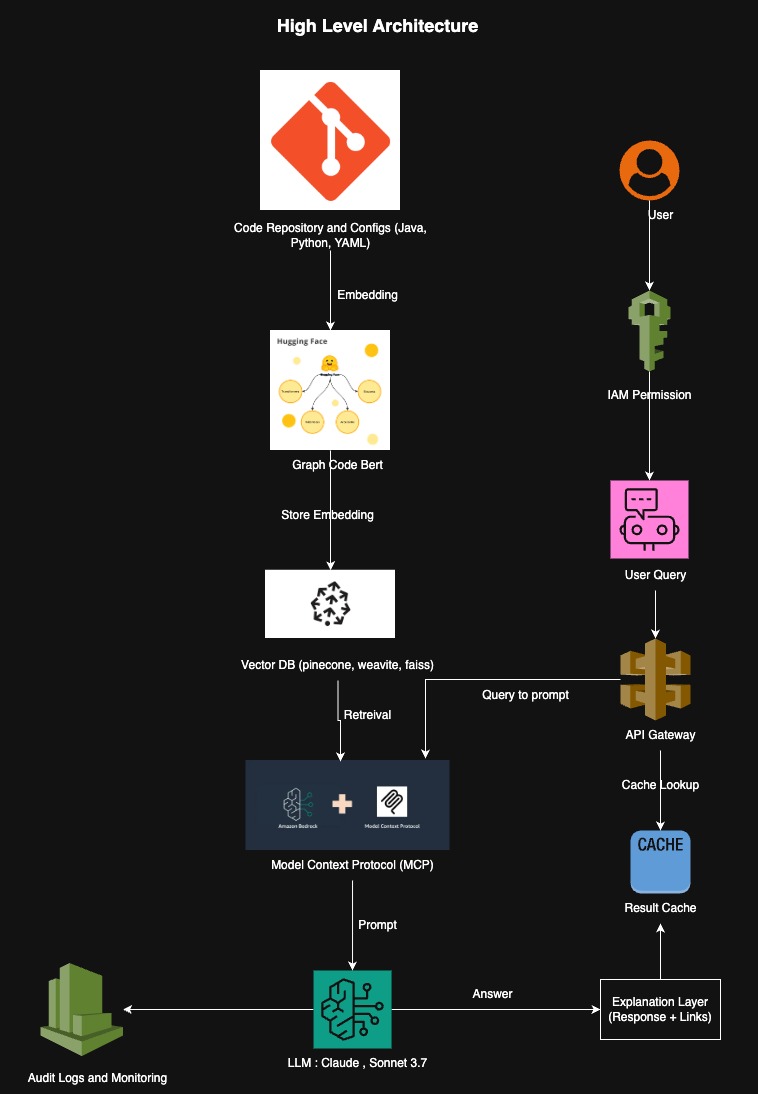
Architecture Diagram
Code Ingestion and Embedding
The process starts with code and configuration file ingestion (e.g., Java, Python, YAML) from a code repository(e.g., GitHub). The files go through a Graph Code BERT model (through Hugging Face) in order to produce semantic embeddings, representing the meaning and relationships within the code structure.
Vector Database Storage
The embeddings generated are stored in a vector database such as Pinecone, Weaviate, or FAISS, which allows for fast subsequent retrieval by similarity.
User Query Flow
A user issues a query through a front-end or chatbot UI. The request is routed through IAM permissions to properly authenticate and authorize.
API Gateway and Caching Layer
The client query is routed through an API Gateway that also searches a result cache to find out whether a similar query was recently resolved. If so, the cached result is returned to reduce compute latency and cost.
Query-to-Prompt Conversion and Retrieval
When no cached result is available, the query is translated into a vector database search-friendly format. The query is then passed on to the vector store to fetch the most similar code embeddings (based on similarity with the query).
Model Context Protocol (MCP)
Retrieved context and code are encoded in a Model Context Protocol (MCP), which likely includes associated documentation, file references, or comments. The MCP is mixed with Amazon Bedrock tools to drive prompt-constructing logic.
LLM Inference (Claude/Sonnet 3.7)
The constructed prompt is forwarded to a big model such as Claude or Sonnet 3.7, which generates an explanation or response to the user question. The output might include reasoning, code walkthroughs, or relevant suggestions.
Explanation Layer
The raw response is subsequently processed in an explanation layer, which can enrich it with hyperlinks, related documents, or structured formatting for improved readability and usefulness.
Monitoring and Audit Logging
Throughout the workflow, important events and user interactions are recorded via CloudWatch or similar logging tools for audit, compliance, and monitoring.
Summary of Key Technologies Involved
- Embeddings: Graph CodeBERT via Hugging Face
- Vector store: Pinecone / Weaviate / FAISS
- Prompt orchestration: Model Context Protocol (MCP)
- LLMs: Claude, Sonnet 3.7 (via Amazon Bedrock)
- IAM and API gateway: To handle security and routing
- Caching: To reduce cost and latency
- Monitoring: For observability and governance
Real Use Case: Automating Accounting Logic for Capitalizable Assets
- Domain: Infrastructure asset lifecycle (e.g., EBS snapshots, Kafka topics)
- Goal: Automatically decide if assets need to be capitalized or expensed.
- Challenge: Decisions are encoded in sprawling rule engines, microservices, and conditionals with minimal human-readable documentation.
How GenAI Helped
- Embedded all asset-related functions using GraphCodeBERT.
- Retrieved relevant code snippets based on natural language queries.
- Bundled context from config files and source control metadata.
- Generated precise explanations, e.g.:
“This snapshot is marked non-capitalizable because the volume duration is less than 7 days, a rule introduced in March 2024.”
Why Code Isn’t Readable Knowledge
Though business rules exist in code, they are rarely accessible or understandable to non-developers:
- Code is optimized for machines, not humans or analysts.
- Configuration logic often hides within YAML files, domain-specific languages (DSLs), or nested conditionals.
- Source control histories show what changed, but lack the why or how context.
Example:
A finance analyst asks:
“Why aren’t volume snapshots being capitalized?”The answer is buried in a 50-line Java function, last updated six months ago. Navigating this requires deep code knowledge and time.
How Codex Enables Product Managers and Stakeholders to Self-Serve Enterprise Logic
It started with a Monday morning stand-up. A product manager asked a simple, reasonable question: "Why isn't the new user experience triggering for some accounts in the EU region?" The engineer stalled. The feature flag logic was buried in a series of YAML conditionals that backed up into a legacy routing override system untouched in months.
Yes, they might work their way through the config files, follow ownership, and cobble together the story — but it would take at least 30 minutes, probably requiring a second meeting and further Slack threads.
Now imagine that same discussion happening over a series of ten PMs, each one of them implementing a different feature release, all wrestling with config drift and policy updates. Times three simultaneous drops, scattered docs, and uneven tribal knowledge — and you begin to see the stealthy cost of scale in most engineering orgs.
With Codex, the same product manager simply types a question into a Slack app or internal portal:
"Why isn't the new onboarding experience available for user cohort X in the EU?"Behind the scenes, Codex checks against the relevant logic, disassembles conditionals from the YAML embedded within, and assembles prompt context based on recent override history, rollout metadata, and version control.
The LLM executes the structured input and produces the response: For users within the EU market, feature_onboarding_v2 is disabled due to an override within routing_config.yaml scoped within cohort: X. This was introduced in April 2024 for phased rollout following a failed A/B test."The product manager receives the full answer — human-readable, technology-based, and source-backed — in seconds. No ticket was ever created. No engineer was interrupted. And no decision was postponed.".
Why This Matters for Stakeholders (PMs, Analysts, Ops)
Stakeholders want context, not code. Codex gives them:
| Need | What Codex Delivers |
|---|---|
| “What does this flag do?” | A semantic explanation + config trace + Jira reference |
| “Who changed the logic?” | GitHub author, date, diff summary |
| “Is this system treating exceptions correctly?” | Logic condition + fallback chain trace |
| “Which users are excluded from feature X and why?” | Rule chain, filter logic, commit history |
Business Value: Codex Becomes an Internal API for Truth
- PMs make faster, more informed product decisions
- Ops teams debug rollout edge cases without paging engineers
- Finance can validate cost behavior (e.g., missed capitalization, unexpected infra spend)
- Support can resolve Tier 2 escalations by querying system behavior directly
And perhaps most importantly:
No one has to Slack an SME and wait two days for a link to an outdated Confluence doc.
Developer and Business Impact
| Metric | Before (Manual) | After (GENAI QA) |
|---|---|---|
|
SME Time Spent (per week) |
5–7 hours |
Less than 1 hour |
|
Mean Time to Answer (MTTA) |
1–2 days |
Instant |
|
Knowledge Base Reusability |
Low |
Auto-generated |
|
Audit/Compliance Readiness |
Manual |
Structured, traceable |
The solution slashes SME interruptions, accelerates onboarding, and enhances compliance readiness with structured audit logs.
Beyond Productivity: Strategic Knowledge Retention
This approach is not just a copilot — it’s a strategic memory layer enabling:
- Root cause analysis (RCA) supports post-incident.
- Clear rationale behind flag changes during outages.
- Assistance for QA teams in identifying test coverage gaps.
As enterprise systems scale, a structured, explainable knowledge layer becomes critical for resilient, decentralized decision-making.
Closing Thoughts
The idea transcends the traditional copilot paradigm. By embedding explainable logic and searchable knowledge directly into development workflows, enterprises can eliminate SME bottlenecks, reduce onboarding friction, and ensure compliance — all while empowering teams to move faster and with greater confidence.
Building this GenAI-driven memory layer will be as fundamental as the systems it supports, unlocking the next leap in developer productivity and operational agility.
Opinions expressed by DZone contributors are their own.
Comments