Why Your AI Agent's Logs Aren't Earning Trust
What did the agent do? That’s a solved problem. Why did it do it? That’s not. Getting this right determines whether anyone trusts it with work that matters.
When you are triaging an incident at 2 AM, caused by what your agent did, the only thing that matters at that moment is whether you can understand why the agent did what they did.
Eighteen months into the agentic AI wave, the gap between what an agent logs and what a human needs is the bottleneck most teams are facing. It’s easy to answer “what the agent did,” but not “why the agent did it.”
An AI agent will not be fully autonomous unless it can explain its reasoning to a variety of stakeholders, ranging from an engineering manager, a customer, or an audit reviewer, at the right granularity. Whether an agent ends up running mission-critical workflows or stays parked on low-stakes tasks boils down to one question: can a human understand what the agent is doing?
Observability and Explainability Are Not the Same Thing
The terms observability and explainability are borrowed from DevOps taxonomy, but in the context of AI agents, they don’t mean the same thing. And that origin matters for how we use them here.
Observability is about what happened. It is a mechanical, deterministic record of tool calls, inputs, outputs, and branching paths. This is a structured logging problem, and it's largely solved. The remaining challenge at this stage is making these logs useful at scale.
Explainability is about why it happened. This is the agent's reasoning behind its actions, the alternatives it considered, and how confident it was. This is a harder and partly unsolved problem.
A real-world example that illustrates the point is that you are sitting at home one afternoon, and your dog comes home covered in mud. Observability is the tracker you have on your dog that shows he went to the park, the creek and the neighbor’s yard. You know where your dog was, but you lack the context as to why. That’s where explainability comes into play, where your dog would tell you why he jumped into the creek (if he could talk), which, as a parent, is the part you care about the most.
When Do You Need Explainability?
Consider a scenario where you are triaging a tier-1 severity incident. As you navigate the codebase and recent pull requests for root cause, you discover that the error lies in the agent modifying, for example, both the authentication logic and the database schema when it was only tasked with updating the authentication logic.
When you look at that code, you have no idea why the agent took that specific approach. Extrapolate that to all the developers in the company, and you will see a macro pattern emerge where developers become less willing to rely on AI agents for critical workflows. Or worse, they add manual steps through the workflow, eroding the productivity gains AI promises and slowing adoption over time.
Product Managers and Analysts may erroneously chalk that up to novelty effect, but it’s really a “trust tax” that your agent incurred. It failed to build trust with its users and has now been relegated to non-critical sidekick tasks,such as clustering the tickets on your issue tracking system.
Three conditions push an agent into explanation-required territory:
- Acting on behalf: When an agent has write access to production systems, or is communicating with people on the user's behalf, or making decisions a human will be held responsible for.
- Cost of being wrong: When errors are expensive or irreversible. For example, agents writing public-facing social media posts, signing contracts, moving money, issuing refunds.
- Sensitive contexts: When agents are operating in regulated environments, working with PII or financial data, or generating output that feeds other agents downstream that operate in a regulated environment. If there is no explainability in such situations, errors can compound exponentially through automation chains.
The Explainability Stack: 8 Layers of "Why"
Explainability is not one feature; it's a layered architecture, and each layer is the right answer for a different user in a different context.
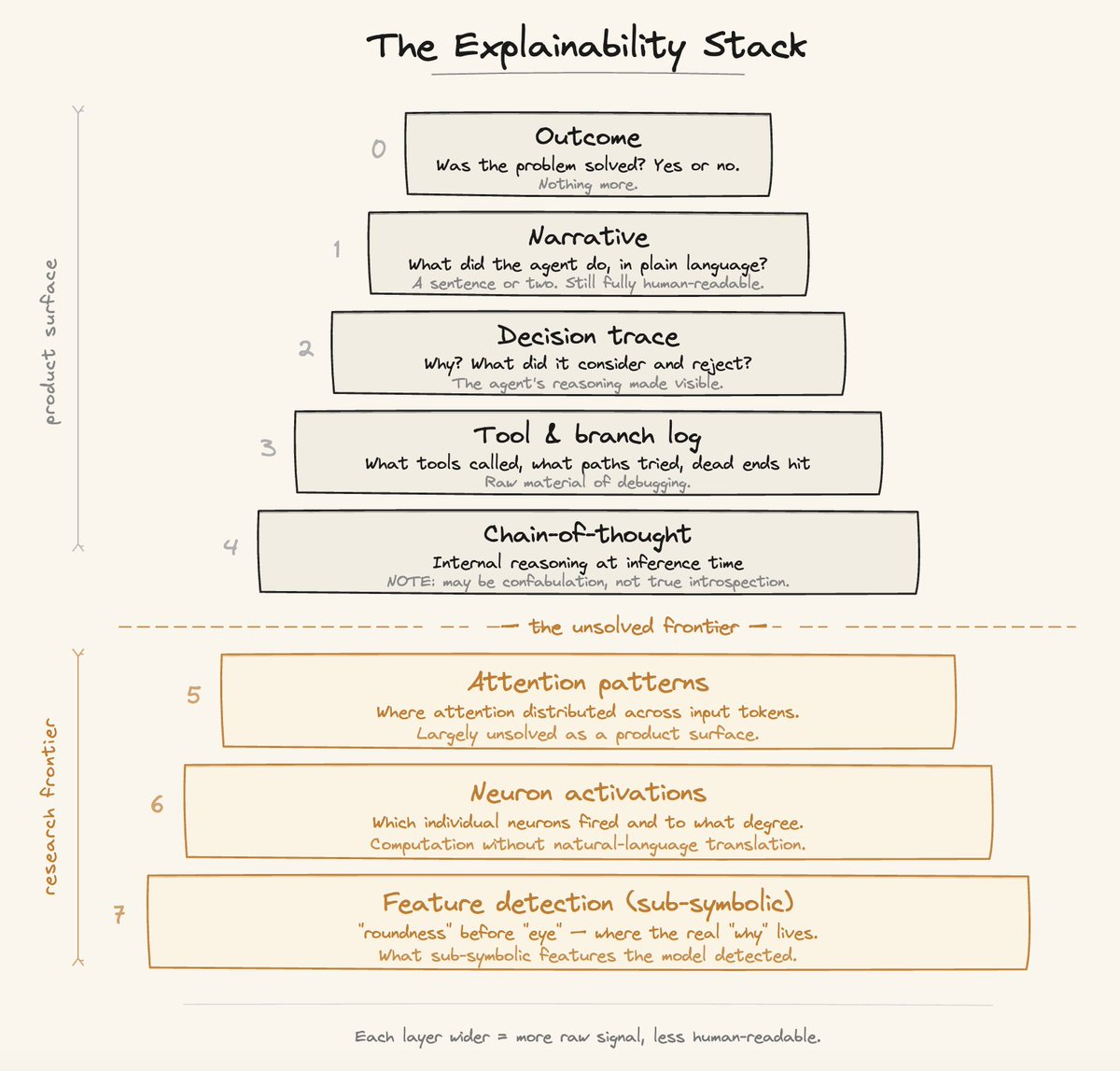
- Layer 0 – Outcome: Did it work? Yes/no. What most users want most of the time.
- Layer 1 – Narrative: A plain-language summary. "Created the PR, flagged three issues, posted inline comments on lines 42, 87, 203." Expedition report: the agent went out, came back, and here is what it found.
- Layer 2 – Decision trace: Why did it choose what it chose? What did it consider and reject? Reasoning made visible, not just actions.
- Layer 3 – Tool and branch log: What tools were called with what parameters, what was returned, what paths were explored, what dead ends were hit. This is where engineers live when something breaks.
- Layer 4 – Model reasoning: Chain-of-thought at inference time. Critical for evals, fine-tuning pipelines, and production debugging. Caveat: CoT may be confabulation, not true introspection.
- Layers 5–7 – The deep stack: Attention patterns, neuron activations, sub-symbolic feature detection. Territory of mechanistic interpretability research, and not a product surface (yet).
The closer someone sits to the implementation, the deeper they want to go. A solutions engineer reviewing a Monday digest lives at Layer 1. A developer debugging an unexpected tool call lives at Layer 3. A researcher studying emergent model behavior lives at Layer 5. Explainability is not one-size-fits-all and is defined by where your user actually sits.
Layered Disclosure Beats "Show Logs"
Most teams collapse this entire stack into a single "show logs" toggle. That over-shows to non-technical users and under-shows to engineers. And ends up losing the trust of both. The fix is layered disclosure tied to specific surfaces:
- Layer 0 in the headline UI. Green check on the PR. "3 tickets resolved" badge.
- Layer 1 in asynchronous recaps. Monday digest in Slack. Weekly email summary.
- Layer 2 behind a one-click "why?" on any decision the user might disagree with.
- Layers 3 and 4 gated behind a developer console or audit export.
The payoff shows up clearly in support across any enterprise deploying agents. When a customer complains and the Solution Engineer sees that the agent did the wrong thing, they can walk down the explainability stack with the customer, starting with the outcome and going deeper only as needed. Explainability, in other words, isn’t just an internal tool. It’s how the customers build trust with you, and that has a dollar value attached to it.
The Goldilocks Constraint
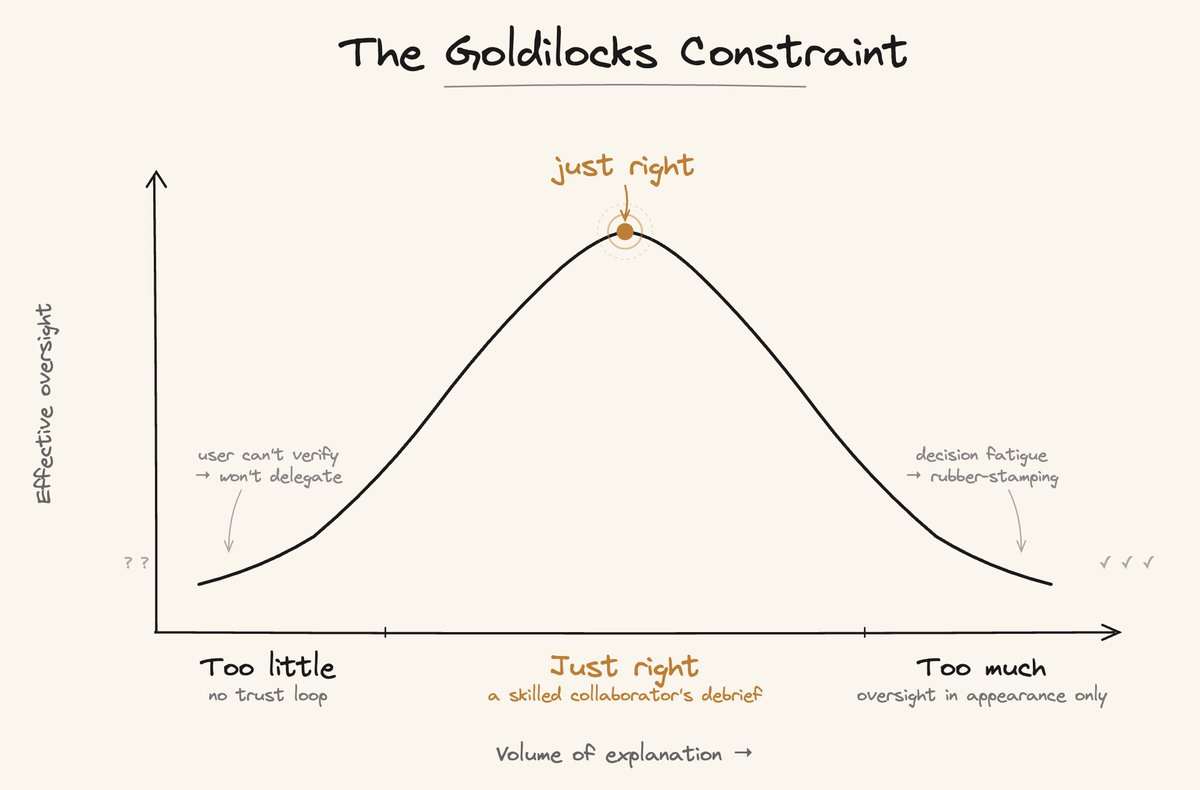
There's a calibration problem at the center of all this:
- Too little explainability: Users can't verify the agent's reasoning, so they won't hand it anything that matters.
- Too much explainability: Users hit decision fatigue. They stop reading and start rubber-stamping. Engagement becomes performative.
The first failure mode is well-documented above. The second is more insidious - it produces the appearance of oversight without the substance. In a regulated environment, that gap can become a compliance liability faster than it looks.
This is Goodhart's Law showing up in a new domain. When "volume of explanation" becomes the proxy for "quality of oversight," products optimize the proxy and lose the thing it was meant to measure. More logs, more traces, more reasoning text, all consumed by a reader who has stopped engaging.
The reference point I keep returning to: what does a skilled human collaborator tell you after working on something independently? They don't narrate every search query or share their browser history. They say: "I looked at X and Y. X was a dead end for this reason. Y is the path forward, here is why, and here is what I am not certain about." That is the goal.
Trust Is the Whole Game
Foundational models are heading toward commoditization. The weights are commoditizing. The homework is not.
A few years from now, the products with better explainability will be the ones running mission-critical workflows — and the ones without it will still be sidekicks. Trust is the foundation of any bond, for humans and for products. It is also the part of the stack you cannot ship in a model upgrade.

At CodeRabbit, we are building explainability across all of our products. Our vision is to show developers what happened and why it happened without burying them in output. More on what that looks like soon.
Comments