What Is a Distributed System?
Engineering is changing day by day at an increasing pace with the appearance of more advanced systems that adapt to the complexity of the processes required for data transformation. Distributed systems play a part in this evolution by offering a high degree of flexibility and complexity at multiple levels, requiring an appropriate observability platform to benefit from many of its advantages. This Refcard is intended for anyone interested in learning more about the management of distributed systems, and more specifically, how to observe this type of platform for proper operation.
Businesses need to be agile to survive in today’s volatile, ever-changing marketplace, which means their applications' underlying architectures must also be agile. The five key architectural features to support agility, speed to market, and ultimately, competitive advantage in today's market are:
- Availability (fault tolerance)
- Scalability
- Deployability
- Testability
- Maintainability
To implement these features, companies rely on distributed systems — reliable architectures consisting of numerous components located on multiple servers that communicate and coordinate actions to appear as one coherent system for the end user.
Distributed systems are widely used today — Kubernetes, Apache Spark, and Apache Kafka, for example, are prominent distributed systems used to improve the way resources are consumed to attain the best performance possible. Achieving this is certainly not easy and requires coordination between development and operations teams for proper management and consumption of available resources.
Benefits of a Distributed System
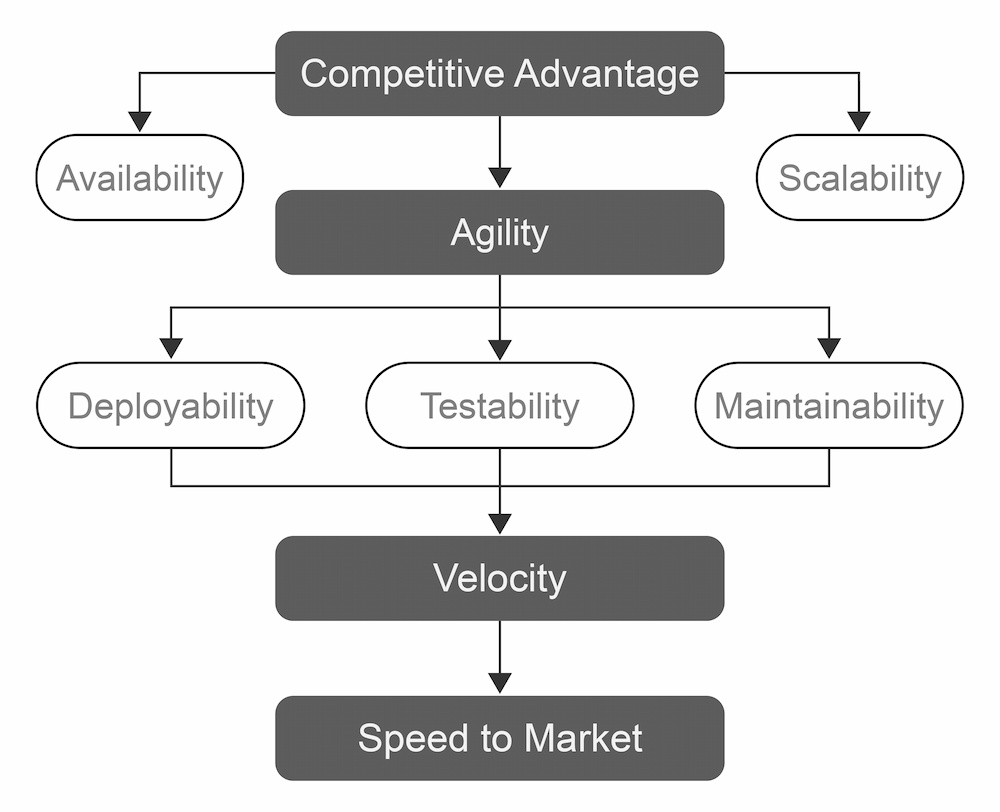
A distributed system can be composed of multiple resources, physical servers, virtual machines, and containers; anything with compute capabilities available on the network can be used to create a cohesive unit consumed by the end user. This kind of architecture, as illustrated in Figure 1, has four global objectives at a company level: competitiveness, agility, velocity, and speed to market.
The competitiveness of an enterprise can be measured according to the level of its product availability. Today, this means an architecture must be capable of scaling to the extent needed to support the product, ultimately, in order to meet both client and end-user demand at all times. Speed to market is the ability to react quickly to change, relying on agility to do it right. Agility is needed in system management as well as in workflows that consume resources to accelerate change. Agility is achieved by integrating flexibility into deployments, tests, and maintenance, which works to improve team performance, thus allowing an increase in velocity.
The design of distributed systems is tailored to meet all these criteria. These systems' high performance and fault tolerance ensures business continuity of service and minimal impact on the end user.
Figure 1: Distributed system advantages at a business level
Disadvantages of a Distributed System
Any distributed system has its disadvantages. By design, a distributed system is spread across multiple resources, which increases the complexity of management at several levels (e.g., automation, installation, upgrade). Indeed, distributed systems are comprised of multiple components based on different lifecycles, using different set of tools and technologies that constantly evolve. Thus, the operations team requires a deep understanding of managing the distributed system to properly operate it in production.
Troubleshooting a distributed system can often be the most complicated phase for both operators and developers, as they must diagnose different systems simultaneously to identify abnormalities. Another disadvantage, though not the least, is the platform's associated costs, including human resources and the time allocated to operationalize it. Plus, the required compute resources can be exponential depending on the use.
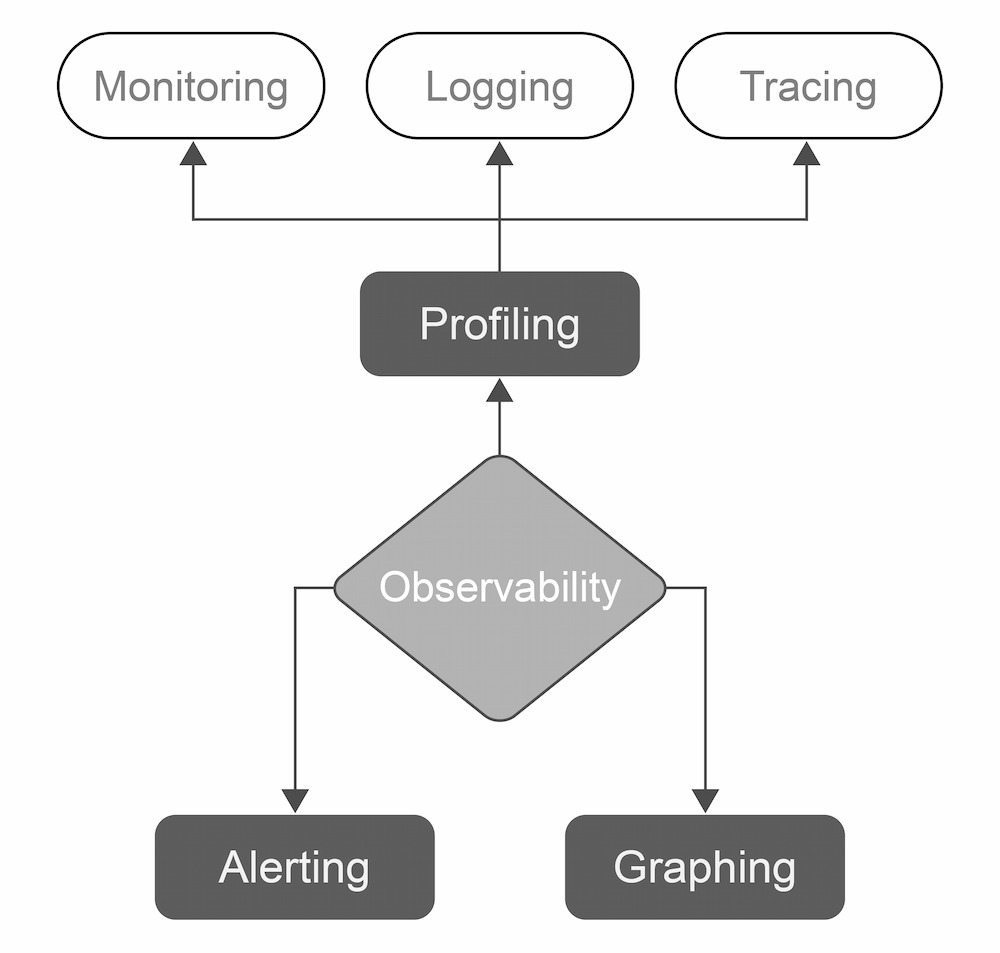
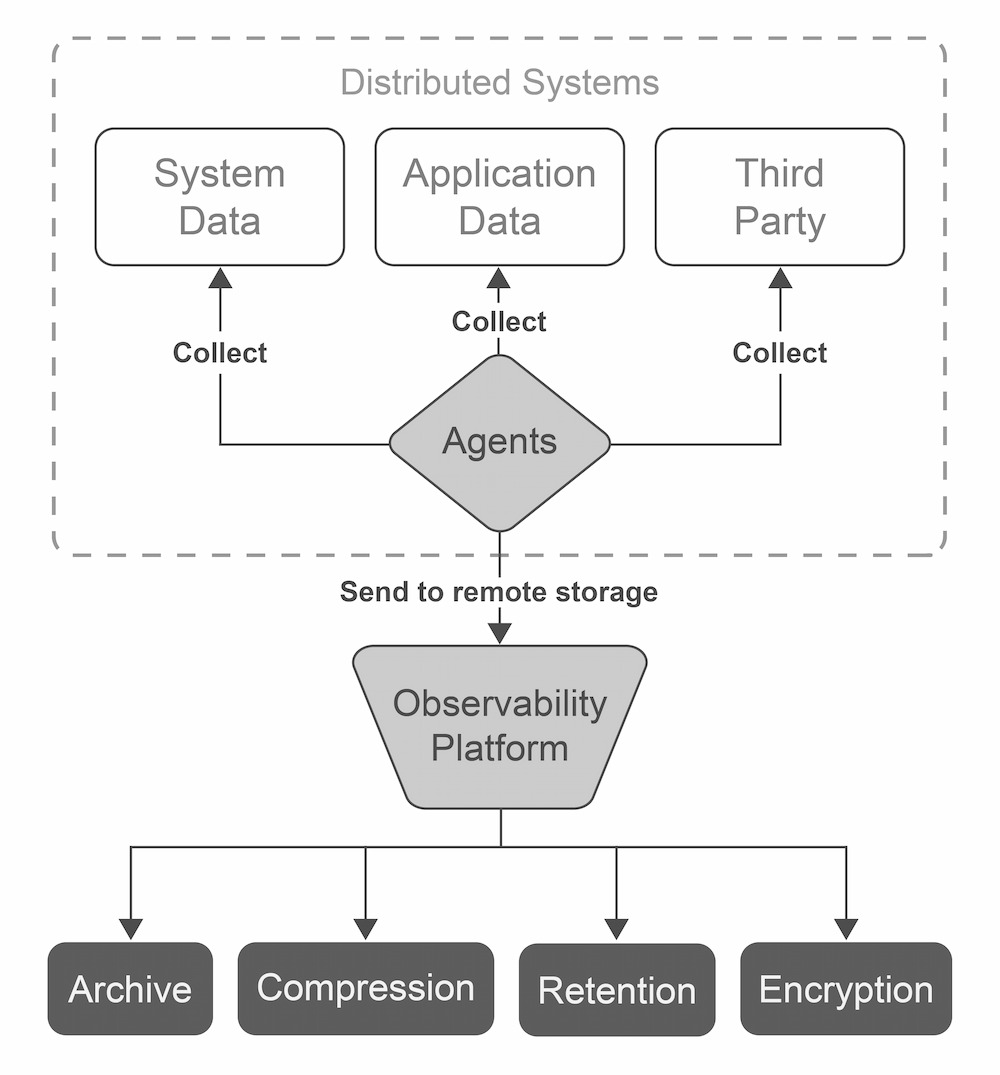
It is, therefore, crucial to have a reliable observability platform in order to quickly access all the data needed for diagnosis and optimization across all areas and at multiple levels of the distributed system.