Getting Started With Redpanda in Kubernetes
Learn how Redpanda is deployed in K8s with components like the reimplementation of Kafka broker, StatefulSets, nodeport, persistent storage, and observability.
Join the DZone community and get the full member experience.
Join For FreeRedpanda is an event streaming platform that is free and open source, similar to MariaDB and CockroachDB. It is compatible with Kafka APIs and is used by many as an alternative to Apache Kafka due to its performance and lightweight design.
Kubernetes (K8s) is the defacto platform for cloud-native environments, so it’s not surprising that many developers choose it to manage their Redpanda clusters. But when things go wrong, it’s not as simple as “kill it, dump it, and rebuild” — much like with other data-intensive software, databases, messaging systems, and even Apache Kafka®. This is especially true when you’re streaming vast amounts of data with high throughput.
This blog post uncovers all the nuts and bolts of running a Redpanda cluster in K8s. It covers install configurations such as resource allocation, network settings, and the location of the persistent store. And also what to do for day two operations. Finally, I've included a hands-on sandbox for you to play with.
The Components
Redpanda and Kubernetes use similar terms to describe their structure, which makes it all simpler to wrap your head around.
Here’s a brief view of each component:
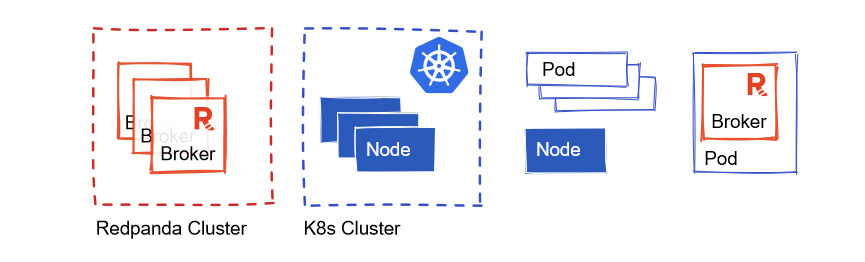
The Architecture of Redpanda in Kubernetes
I currently recommend using the Redpanda Helm chart to deploy a Redpanda cluster in Kubernetes. Helm chart makes it straightforward to deploy a multi-broker Redpanda cluster, and provides the Redpanda Console for easy administration. Regardless of the different ways to deploy (Helm or Operator), the fundamental components in Kubernetes won’t change.
- Redpanda broker: The single binary instance of Redpanda with built-in schema registry, HTTP proxy, and message broker capabilities.
- Redpanda cluster: One or more instances of Redpanda brokers, and aware of all members in the cluster. Provides scale, reliability, and coordination using the Raft consensus algorithm.
- K8s worker node: A physical or virtual machine that runs the containers and does any work assigned to them by the K8s control plane.
- K8s cluster: Group of K8s worker nodes and control plane nodes that orchestrate containers running on top with defined CPU, memory, network, and storage resources.
- Pod: A runtime deployment of the container that encapsulates Redpanda broker — ephemeral by nature, and shares storage and network resources in the same K8s cluster.
Here’s a diagram of what your K8s cluster will look like after deployment:
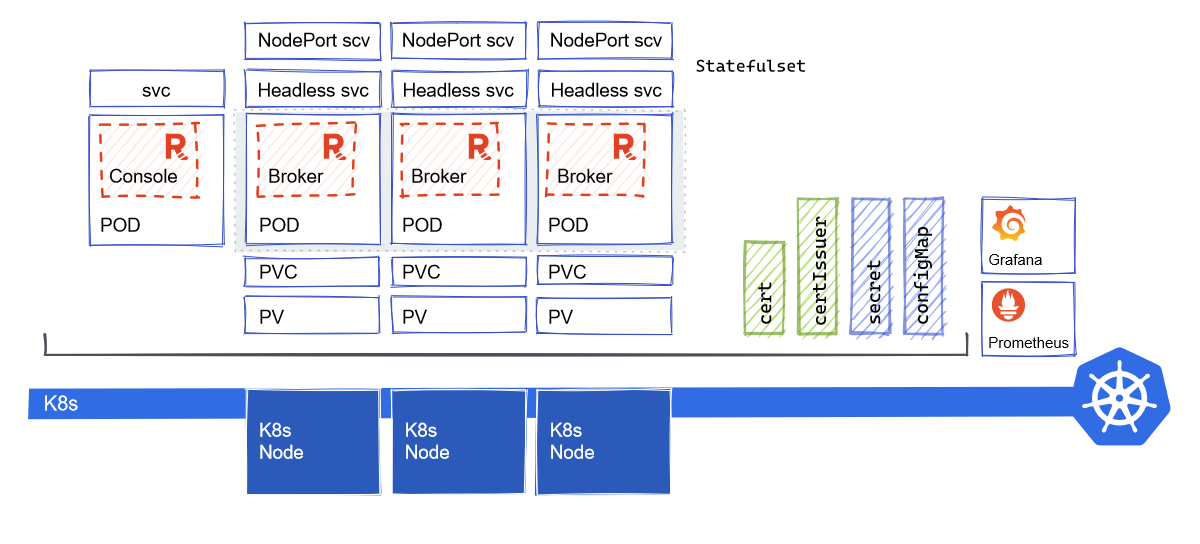
Let’s focus on the Redpanda broker pods for a minute. You can break them down into three logical sections:
- Redpanda broker: The actual engine of the streaming platform. It’s in charge of streaming events from producers and consumers, writing data into storage tiers, and replicating partitions.
- The networks: These are for communicating between clients outside of the K8s cluster and the broker.
- Persistent storage: For storing events and cache shadow index, if Tiered Storage is turned on.
You can change the Redpanda configuration via customizing settings in Helm charts. I recommend defining configuration settings in your own values.yaml file when installing the chart.
There’s a lot more to learn about these three sections, so let’s dig a little deeper into each one.
Redpanda Brokers in StatefulSet
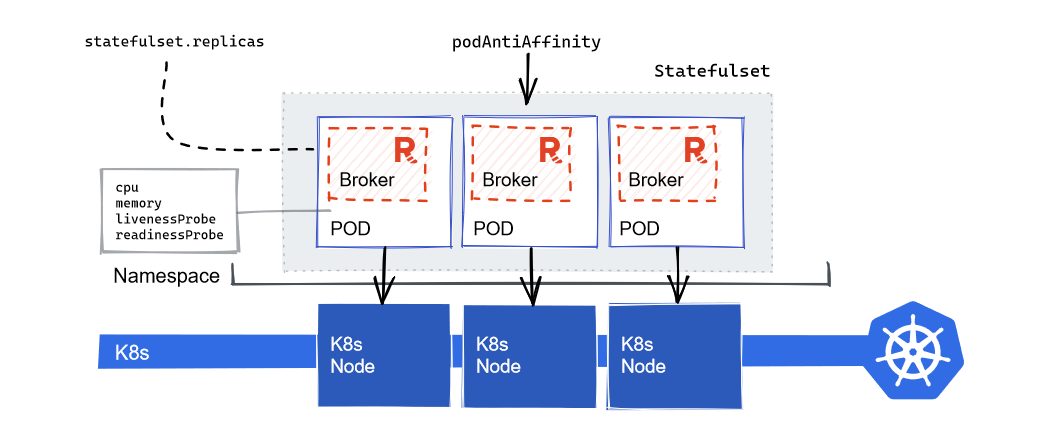
Redpanda relies on StatefulSet to guarantee the uniqueness of a broker. Partitions are replicated and distributed evenly across brokers, so every broker will need to keep state (and remember who they were) even after the restart to pick up where it left off.
It specified K8s rules for not scheduling the broker pods to run together on the same K8s node. This ensures:
- Redpanda brokers don’t compete for the same CPU cores and memory resources on a machine.
- Multiple brokers won’t go down at once if the underlying K8s worker node goes offline.
For the best performance, allocate at least 80% of K8s’ node memory and CPU cores to each container. Leave the remaining for utilities and K8s processes.
The way Redpanda handles cluster and topic-level configuration is no different from other ways of deployment. Settings are replicated across the Redpanda cluster and stored internally inside it. The best way to configure them is through the use of rpk — Redpanda’s command line interface (CLI) utility. The broker-specific configurations are mounted from configmap into local storage under the folder /etc/redpanda.
If TLS is enabled, Redpanda takes advantage of the CertManager operator to generate the certificates, (which helps with automatic renewal). By default, we set Letsencrypt as the certificate issuer. You can overwrite it with your preferred certificate issuer. The issued cert is then stored in a secret, mounted to the broker pod, and then used by the broker for encryption.
The Networks

K8s distributes network traffic among multiple pods of the same service. But for solutions like Kafka or Redpanda, it just won’t work. The clients will have to reach the broker that hosts the leader of the partition directly.
The headless service gives each pod running Redpanda broker a unique ID. Intra-broker communication, such as leader election and partition replication, and clients living inside the same K8s cluster will use the internal K8s address/IP for the pod to communicate.
For external communication, Redpanda uses NodePort service by default. This will expose the listeners to a static port on the K8s node IP. It’s best to customize a domain name and set up DNS to mask the IPs. Alternatively, you can set up a LoadBalancer service for each broker, where the network traffic will be routed via the internal K8s controller.
You also will have to configure the right advertised Kafka address for clients, so the client can locate the brokers correctly. For a deep dive into how it works, check out our blog on “What is advertised Kafka address?”. Pay special attention to the section about using Kafka address and advertised Kafka address in K8s.
Persistent Storage![Persistent storage]()
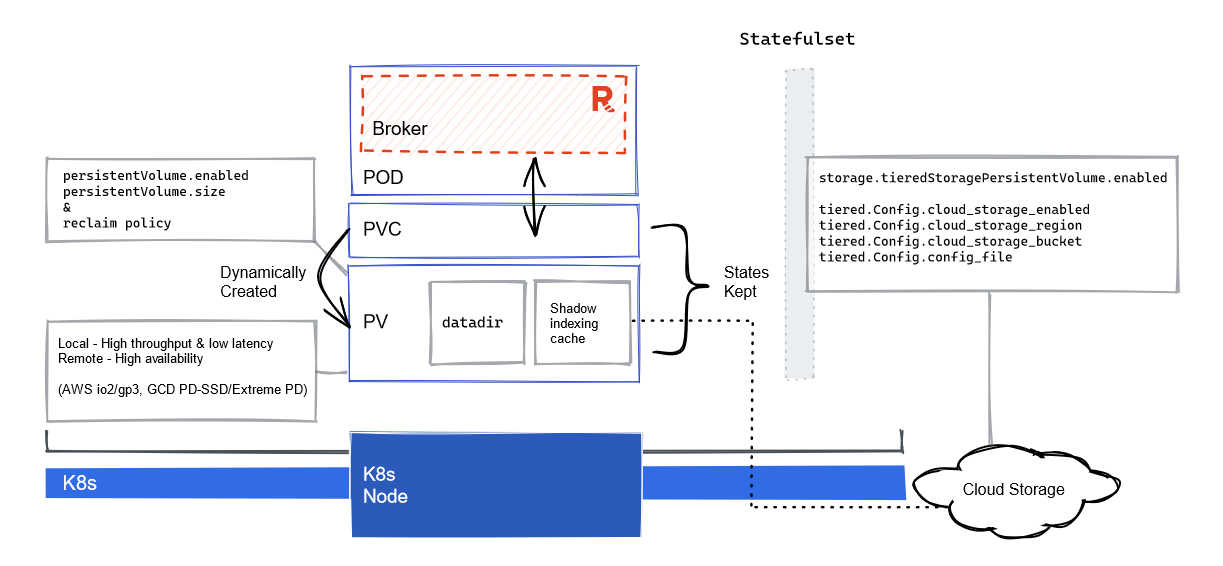
Storage plays the most important role. It’s defined as Persistent Volumes (PV) claimed via a Persistent Volume Claim (PVC) for each pod running a Redpanda broker. The PVs can be predefined or dynamically provisioned, and they determine the size of your storage as well as the types of storage (SSD, NVMe SSD).
Storage placement heavily impacts IOPS capacity and the location of your data. Here’s a good rule of thumb to follow when choosing between local or remote storage: the further away from the K8s cluster, the higher the latency.
You can choose to use local, ephemeral storage on the K8s worker node, but there’s a risk of data loss in the case of node failure. If this happens, Redpanda will automatically attempt to replicate the data from other brokers to minimize that risk.
Always consider enabling Tiered Storage to leverage its benefits, including reduced storage cost and improved recoverability. Tiered Storage can help avoid “disk full” problems by offloading old data into the cloud object store automatically, which in turn reduces the local storage requirements for the Redpanda cluster.
One thing to keep in mind with Tiered Storage is the partition cache. The cache is a portion of the disk space dedicated to temporarily holding data from the object store. Make sure you have taken account of that while planning.
In the case where you absolutely need to expand the size of your storage, please note that not all storage types can support volume expansion. Volume types that allow the users to resize are, for example, gcePersistentDisk, awsElasticBlockStore, and Azure Disk.
Maintaining, Monitoring, and Optimizing Redpanda in Kubernetes
Deploying your Redpanda cluster in K8s doesn’t mean it’s time to put your feet up. To keep the cluster running smoothly, you want to continuously maintain, monitor, and optimize the system — known as “day two operations”.
Day two activities typically include:
- Scaling the cluster
- Upgrading to access new features and bug fixes
- Changing the replication or partition setting
- Modifying the segmentation size
- Setting back pressure
- Tweaking data retention policies
One important “day two” operation is the rolling upgrade, which lets you safely move the software release forward while minimizing client impact. Let’s take a closer look at how to manage rolling upgrades in K8s.
Rolling Upgrades With Kubernetes
K8s adds a layer of complexity when doing upgrades. Here’s what you need to do:
- Turn off some of its self-healing features so it won’t interfere with the broker’s plans for partition relocations.
- Make sure you have the latest Helm chart from Redpanda, then delete the Statefulset with cascade set to orphan so it will keep the old brokers running.
- Use Helm to upgrade, where it will redeploy a new
statefulsetwith the latest version of Redpanda configured (with OnDelete strategy so it doesn’t immediately restart the brokers).
Once it’s set, carry on with how you would normally upgrade a broker: put one of them into maintenance mode, wait for it to drain, let the cluster rebalance, and delete the pod.
The new statefulset will schedule a new pod running the latest version of the broker. With the PV being a separate entity, the data still remains and can be reused. This will allow Redpanda to recover faster and spring back to 100% capacity.
Published at DZone with permission of Christina Lin, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments