go-mysql-mongodb: Replicate Data From MySQL To MongoDB
This tool is relatively lightweight, and only needs to deploy one service for the synchronization of a MySQL instance to MongoDB.
Join the DZone community and get the full member experience.
Join For Free
This year’s Spring Festival holiday is relatively idle, so I organized my open source project go-mysql-mongodb.
This tool is used to synchronize MySQL data to MongoDB. It has been developed for a long time, but there has been no maintenance. A few days ago, I suddenly received an email from a user asking about the problems encountered during use. I realized that this tool is still used by some people. I took advantage of the holiday to maintain it, and hope that I can help more people in the future.
Origins
This project goes back to 2017. At that time, my job was mainly to investigate various big data platforms, and I needed to synchronize MySQL data to databases such as Elasticsearch and MongoDB.
tungsten-replicator
I searched for some solutions on Google. At first, I used tungsten-replicator to synchronize MySQL data to MongoDB. This tool is powerful and is used for data synchronization between multiple heterogeneous databases. For example, the following is the topology diagram of tungsten-replicator synchronizing MySQL/Oracle data to heterogeneous databases:
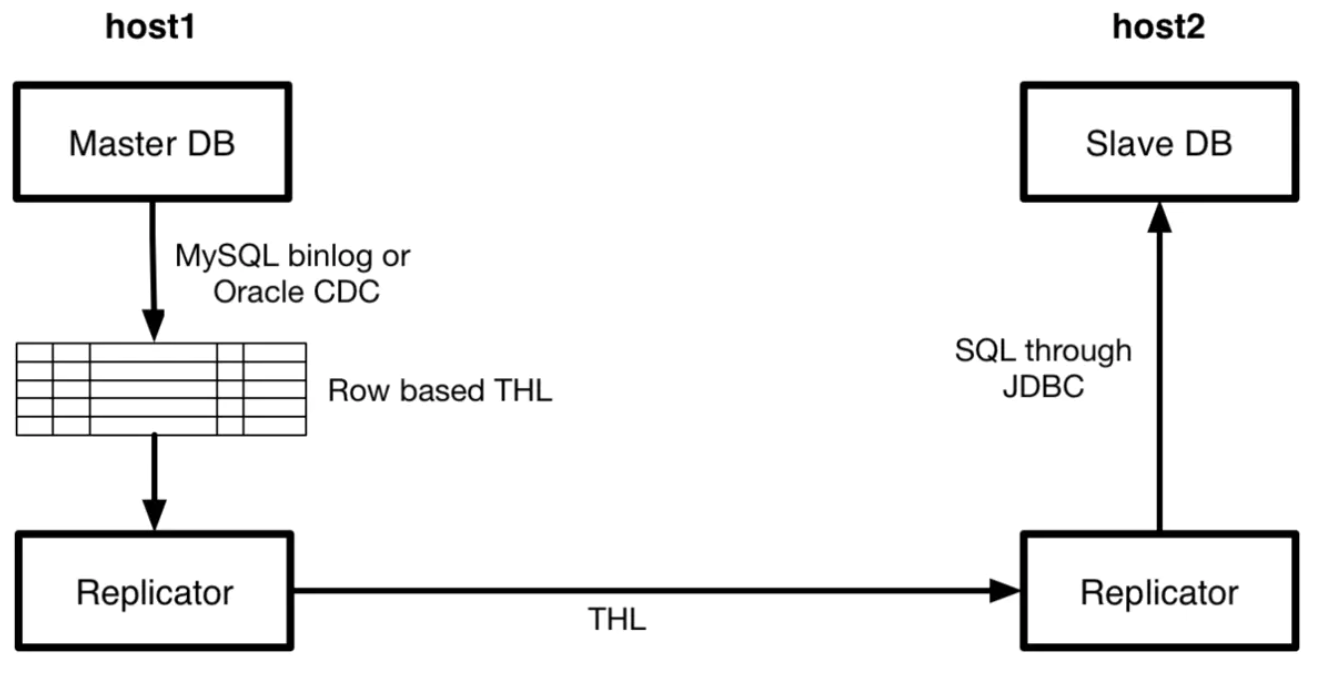
Workflow
- Deploy a Replicator service on the Master and Slave servers respectively.
- Master Replicator pulls binlog/CDC data from Master DB and converts it into a common THL format data.
- Master Replicator transfers THL data to Slave Replicator.
- Slave Replicator converts THL data into SQL and synchronizes it to Slave DB according to the type of Slave DB.
This tool is relatively mature; you can see that their Usage Document, with a total of more than 300 pages, has various scenarios with instructions. But there are mainly these problems in the process of use:
- The structure is too heavy. As you can see from the above example, you need to deploy one on the Master and Slave servers, and you need to save THL data, which will take up a lot of disks.
- The deployment and configuration are more complicated. It supports very rich functions, but its powerful functions also require complex configurations to support. But in fact, we only need to use a small part of the functions.
- Development language (not counting the problem of this tool). This tool was developed in Java, and my group at the time mainly used Python and Golang to develop. If there are new requirements or bugs that need to be fixed, maintenance will be more difficult.
go-mysql-elasticsearch
Later I needed to synchronize MySQL data to Elasticsearch, I found another tool—go-mysql-elasticsearch, tried it out for a while, and found that this tool is relatively lightweight and simple to configure and deploy. The workflow of this tool is as follows:
- Use mysqldump to export the full data of MySQL.
- Import the full amount of data into Elasticsearch.
- Pull MySQL binlog data from the binlog postion position of the full data.
- Convert binlog to Elasticsearch format data, and synchronize to Elasticsearch in the form of RESTful API.
This tool is relatively lightweight, and only needs to deploy one service for the synchronization of a MySQL instance; in addition, it is developed in the Golang language, which I am familiar with. I can also implement it myself when I encounter new requirements during use.
go-mysql-mongodb
After successfully applying go-mysql-elasticsearch to the quasi-production environment, I got the idea of replacing the tungsten-replicator.
MongoDB and Elasticsearch are similar—both belong to NoSQL, and the stored data is all document type. So I reused most of the logic in go-mysql-elasticsearch, just modified the code of the Elasticsearch client in the code to MongoDB and it ran. In this way, the project go-mysql-mongodb was formed.
go-mysql-mongodb Function
As go-mysql-mongodb mainly refers to go-mysql-elasticsearch, the function is basically the same.
To Configure the Data Source
You must set which tables to synchronize MySQL to MongoDB. Example configuration:
xxxxxxxxxx
[[source]]
schema = "test"
tables = ["t1", t2]
[[source]]
schema = "test_1"
tables = ["t3", t4]
It also supports some simple expressions, such as:
xxxxxxxxxx
[[source]]
schema = "test"
tables = ["test_river_[0-9 ]{4}"]
In this way, tables like test_river_0001 and test_river_0002 in the test database are selected.
Conversion Rules
Support synchronizing tables in MySQL to collections specified in MongoDB, and also support conversion of field names in tables, for example:
xxxxxxxxxx
[[rule]]
schema = "test"
table = " t1"
database = "t"
collection = "t"
[rule.field]
mysql = "title"
mongodb = "my_title"
This configuration will synchronize the table test.t1 in MySQL to collection t.t in MongoDB, the title field in the table will also be renamed to my_title.
Filter Fields
Support to synchronize only the fields specified in the table. For example:
xxxxxxxxxx
[[rule]]
schema = "test"
table = "tfilter"
database = "test"
collection = "tfilter"
This configuration will only synchronize the data in the two columns of id and name in the table test.tfilter.
For more functions, please refer to the README of the project.
go-mysql-mongodb Status Quo
This project is still under development. The basic functions should be fine, but more tests are needed to ensure it. In addition, we need to pay attention to the changes of go-mysql-elasticsearch and bring some fixes to go-mysql-mongodb in time.
I hope this tool can help you. If you encounter problems during use, you can raise an issue, or you can directly email me at [email protected].
Opinions expressed by DZone contributors are their own.
Comments