Graph Cache: Caching Data in N-Dimensional Structures
In this tutorial, we will walk you through the usage of the basic APIs provided in the Java Graph Cache library to optimize graph databases.
Join the DZone community and get the full member experience.
Join For FreeAs is already well established, Graph Databases such as Neo4J are great for intuitively storing relationship data in graph-like structures. Neo4J has been around since 2007 and in its current iteration, it is an extremely robust and versatile NoSQL database framework. But, there are limitations to graph databases, namely:
- Query optimization options are limited, although this challenge is certainly being addressed in newer versions.
- Data partitioning is a tough proposition, so horizontal scaling becomes challenging.
- Computationally intensive or costly queries — most real-world graphs are highly dynamic and often generate large volumes of data at a very rapid rate. One challenge here is how to store the historical trace compactly while still enabling efficient execution of point queries and global or neighborhood-centric analysis tasks.
- Queries spanning multiple hierarchies can be time-consuming and not suitable for real-time querying.
- Design is only as good as implementation and this is where the human element comes in. Not everyone can think in terms of graphs.
But, the Graph Cache implementation does not seek to address only the shortcomings of Graph Databases. Over and above these things, Graph Cache seeks to provide a performant framework to do the following:
1. Store any data in a relationship form so that how the data is related also takes on meaning in the form of metadata on edges that connect the data
2. Eliminate data redundancies — since Data is stored in parent-child form, a lot of redundancies in data are avoided by moving repeated values to a parent node. For example, a Jaguar can be a car as well as an animal. Storing Jaguar in a regular cache would mean the following:
- Item 1 -> Jaguar -> Car
- Item 2 -> Jaguar -> Animal
You see that Jaguar object representation is repeated in the value against the keys Item 1 and Item 2.
But in a graph, it looks like so:
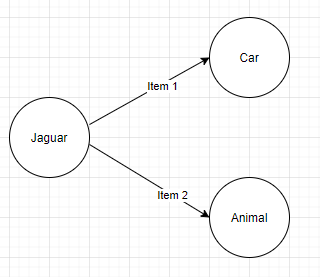
As the Jaguar object becomes a parent with its own properties and metadata that are self-contained, it is stored only once as a parent, and all its relationships are maintained as Children, thus eliminating data redundancy.
On the scale, this can lead to tremendous savings on the amount of data stored.
2. Store minimal subgraphs of deep hierarchical relationships to ensure extremely fast retrieval of data at the leaves by avoiding traversal across the full depth of the tree. The shallower the subgraph that is stored in the cache, the faster the retrieval of data.
3. Represent data in 3 dimensions — Parent node, Edge, and Child node, each having metadata around the relationships so that driving insights from how the data is related becomes easier.
4. Primarily maintained in memory keeps it truly performant, is maintained in memory, and close to the business logic to ensure fast computation.
5. Keeping it simple by providing abstractions over how the data is maintained in the graph. At the same time, give fine-grained control of how you want it to be stored as well.
With some of these key benefits in mind, let's talk about the Java implementation.
The Java Interfaces have been built over the following APIs:
1. JGraphT — A Java library of graph theory data structures and algorithms
2. Caffeine — a high performance, near-optimal caching library
Looking at the POM file you will see the following dependencies listed:
x
<dependency>
<groupId>org.jgrapht</groupId>
<artifactId>jgrapht-core</artifactId>
<version>1.0.1</version>
</dependency>
<!-- Caffeine dependency -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.8.5</version>
</dependency>
JGraphT provides the backing Graph structure to store the data in graph format, specifically Multigraphs.
Caffeine provides a high-performance in-memory Caching solution to specifically store minimal subgraphs.
Let's further deep dive into the available Objects and APIs.
GRAPH APIs
Model Objects:
xxxxxxxxxx
public class Node {
private String identifier;
private Object data;
public Node(String identifier, Object data) {
this.identifier = identifier;
this.data = data;
}
/**
*
* @return String unique identifier that identifies a node within the context
* of your application
*/
public String getIdentifier() {
return identifier;
}
/**
*
* @param identifier Set the unique identifier for the node within the context
* of your application
*/
public void setIdentifier(String identifier) {
this.identifier = identifier;
}
/**
*
* @return Object Get the data stored in the node
*/
public Object getData() {
return data;
}
/**
* Set the data to be stored in the node
* @param data
*/
public void setData(Object data) {
this.data = data;
}
}
The Node object itself is used to store:
1. Identifier: A unique identifier that can be used to search for it and retrieve the data stored in it.
2. Data: Any data that you need to store in the Node. Can be any Java type that inherits from the Object class.
xxxxxxxxxx
public class DataWeighedEdge extends DefaultWeightedEdge {
private Object relationMetadata;
public DataWeighedEdge() {
super();
}
/**
* Get edge metadata
* @return edgeMetadata object
*/
public Object getRelationMetadata() {
return relationMetadata;
}
/**
* Set edge metadata
* @param relationMetadata Set the Edge relational metadata
*/
public void setRelationMetadata(Object relationMetadata) {
this.relationMetadata = relationMetadata;
}
public String toString() {
return "DataWeighedEdge{" +
"relationMetadata=" + relationMetadata +
'}';
}
/**
*
* @return Get the edge parent vertex
*/
public Object getSourceVertex() {
return this.getSource();
}
/**
*
* @return Get the edge child vertex
*/
public Object getTargetVertex() {
return this.getTarget();
}
}
The DataWeighedEdge class represents the Edges that connect nodes and define the relationships between them. The provided fields are as follows:
1. RelationMetadata: This field can be used to store any metadata that provides further information into how the nodes that are connected by the edge are related. By default this field stores the identifiers of the parent and child node in a string format as
"parentIdentifier:childIdentifier"
The DataWeighedEdge also provides the Source (Parent) node and Target (Child) node that the edge connects.
Backing Graph APIs
The GraphInstance class creates the MultiGraph instance of Nodes connected by DataWeighedEdge edges.
xxxxxxxxxx
public class GraphInstance {
private static Multigraph<Node, DataWeighedEdge> multiGraph = new Multigraph<>(DataWeighedEdge.class);
/**
*
* @return the Multigraph instance
*/
public static Multigraph<Node, DataWeighedEdge> getMultiGraph() {
return multiGraph;
}
/**
* Set the provided Multigraph instance
* @param multiGraph
*/
public static void setMultiGraph(Multigraph<Node, DataWeighedEdge> multiGraph) {
GraphInstance.multiGraph = multiGraph;
}
}
We have the GraphUtil class maintaining the instance of the individual GraphInstance created above that will be stored in the cache. The following methods are provided by GraphUtil:
void addRelationship(Node parentNode, Node childNode):
Add a Parent node, a child node, and an edge connecting the two into the GraphInstance.
List<Node> findNodes(String identifier):
Given an identifier that uniquely identifies a Node object, find the Node that has the identifier within the GraphInstance.
DataWeighedEdge findEdge(String parentIdentifier, String childIdentifier):
Given the unique parent node identifier and child identifier, find the edge that connects the two nodes within the GraphInstance.
GraphInstance getCurrentGraphInstance():
Get the GraphInstance stored in this instance of the Util.
The GraphUtil class is the utility class that provides easy-to-use APIs that allow developers to store data into Minimal Subgraphs. These subgraphs are the actual graph structures that are cached in the Caffeine cache.
Cache APIs
The Cache itself is a Caffeine instance that as a best practice is maintained in memory closes the business logic itself.
To initialize the instance The CacheInitializer class is used that provides a default API to initialize a Cache like so:
Cache defaultInitialize(Long maxRecords, Integer expireAfterWriteInMinutes,
Integer expireAfterAccessInMinutes): Initialize the Caffeine cache instance with the following:
maxRecords: A maximum size defined by maxRecords that can be stored.
expireAfterWriteInMinutes: Defines the time unit in minutes before a record is marked as invalid in the cache since it was last written.
expireAfterAccessInMinute: Defines the time unit in minutes before a record is marked as invalid in the cache since it was last accessed.
Caffeine createSelfCustomizableInstance(): Return an instance of a Caffeine builder object that can be customized according to the developers' own preferences.
Once the Cache instance is initialized, the CacheUtil class provides the utility APIs to store the Graph data into the Cache like so:
void initCacheDefault(Long maxRecords, Integer expireAfterWriteInMinutes,
Integer expireAfterAccessInMinutes): Initializes the cache instance with default params and creates the cacheInstance that is maintained within the CacheUtil.
void clearCache():Clears all data from the cache.
void removeKey(String key):Removes the data pertaining to the key from the cacheInstance
void cacheGraph(String key, GraphInstance graph):Cache an instance of the minimal subgraph Instance with any key that the developer provides.
void cacheNode(String key, Node node): Cache just a Node object with data and an identifier that identifies it
void cacheEdge(String key, DataWeighedEdge edge): Cache a DataWeighedEdge object containing a Source vertex, a child vertex, and the metadata that defines the relationship.
getObject(String key): Get the cached Graph, Node, or DataWeighedEdge object that pertains to the key.
The CacheUtil class intentionally provides APIs to cache Nodes and Edges as well to give flexibility to developers in using the Cache just like any other Keystore as well.
So, What Can the GraphCache Be Used for?
The answer is Caching anything like a relationship. It could be any of the following:
1. The state of a Parent div that contains a child div in a React app. The Edge represents the route between the two.
2. Stock prices across days for a stock listed in multiple stock exchanges and priced in different currencies.
3. Service mesh analytical data on the health information of all the connected nodes and how each node depends on each other.
Example Implementation
x
//storing a graph structure in the cache
GraphUtil graphUtil = new GraphUtil();
Node rootNode = new Node("0", "root");
Node childNode1 = new Node("1", "child1");
Node childNode2 = new Node("2", "child2");
Node childNode3 = new Node("3", "child3");
Node childNode4 = new Node("4", "child4");
Node childNode5 = new Node("5", "child5");
Node childNode6 = new Node("6", "child6");
graphUtil.addRelationship(rootNode, childNode1);
graphUtil.addRelationship(rootNode, childNode2);
graphUtil.addRelationship(childNode1, childNode3);
graphUtil.addRelationship(childNode1, childNode4);
graphUtil.addRelationship(childNode1, childNode5);
graphUtil.addRelationship(childNode2, childNode6);
GraphInstance graphInst = graphUtil.getCurrentGraphInstance();
String graphKey = UUID.randomUUID().toString();
cacheUtil.cacheGraph(graphKey, graphInst);
We can store a subgraph in this way. Retrieval can be done using the graphKey like so:
graphInst = (GraphInstance)cacheUtil.getObject(graphKey);
In a similar fashion, we can cache Nodes as well as Edges themselves into the CacheUtil->CacheInstance.
Hopefully, you will find this primer on the Graph Cache useful for your application.
Opinions expressed by DZone contributors are their own.
Comments