Greenplum vs Apache Doris: Features, Performance, and Advantages Compared
Compare Greenplum vs. Apache Doris for MPP-based analytics. Learn which database suits real-time, high-concurrency workloads and evolving data architectures.
Join the DZone community and get the full member experience.
Join For FreeAs organizations increasingly rely on data for real-time decision-making, the demand for scalable, high-performance analytical databases has never been higher. Among the contenders in the modern analytics space, Greenplum and Apache Doris stand out for their MPP (Massively Parallel Processing) architectures and ability to handle large-scale data workloads. While both are designed for analytics, they differ significantly in architecture, performance, and ease of management. This article provides a side-by-side comparison to help data teams evaluate which solution better aligns with their technical and business needs.
1. Overview and Architecture
Greenplum
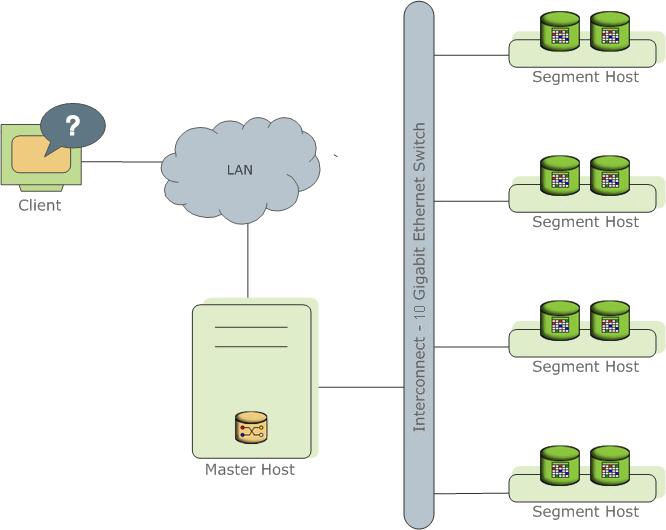
Greenplum is an open-source distributed relational database based on PostgreSQL. It adopts an MPP (Massively Parallel Processing) architecture, designed specifically for large-scale data analytics. Its architecture consists of three main components:
- Master Node: The control center of the system. It receives SQL requests, generates query plans, and coordinates task execution on Segment nodes. Typically, one primary and one standby master node are deployed.
- Segment Nodes: Responsible for parallel computation and data storage. The system scales linearly in performance and capacity by adding nodes, supporting anywhere from 1 to 10,000 nodes.
- Interconnect: A high-speed network (e.g., gigabit or 10-gigabit switches) enabling data transmission between the Master and Segment nodes. It supports parallel data loading.
Greenplum is designed for distributed computation to handle large-scale data analytics but introduces architectural complexity. Its Master node can become a performance bottleneck due to its single-point nature.
Apache Doris
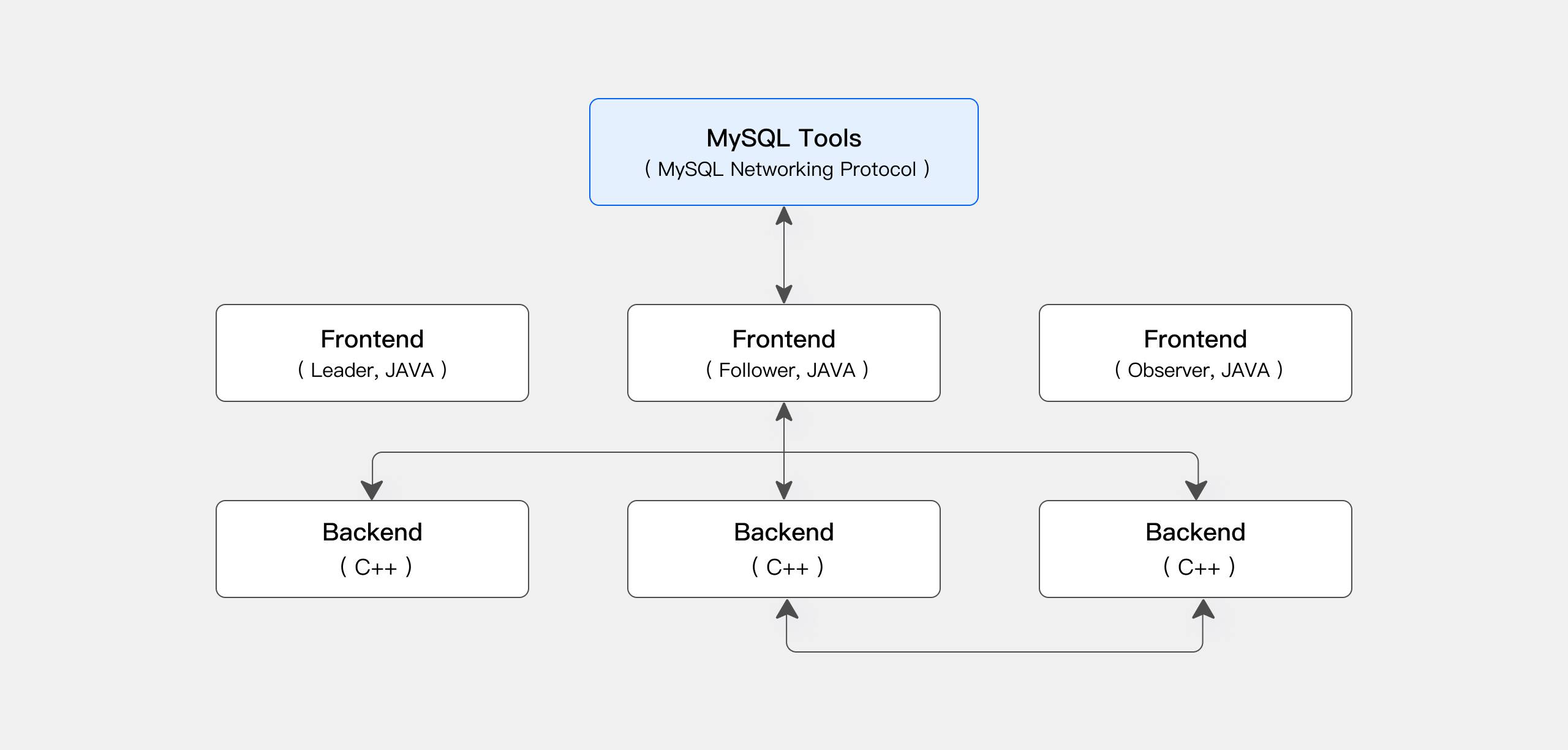
Apache Doris is a high-performance, real-time analytical database that also uses an MPP architecture. It is known for being efficient, simple, and unified. The architecture uses a tightly coupled compute-storage design and mainly includes:
- Frontend (FE): Handles user requests, query parsing, metadata management, and node scheduling. It supports multi-node deployment for high availability.
- Backend (BE): Manages data storage and query execution. Data is stored in shards with multiple replicas.
Doris offers a streamlined architecture that is easy to deploy and maintain. It supports the MySQL protocol and standard SQL, providing excellent compatibility. It can process large-scale queries in sub-second latency and supports both high-concurrency point queries and high-throughput analytical workloads.
2. Feature Comparison
The table below compares key features of Greenplum and Apache Doris.
| Feature | Greenplum | Apache Doris |
|---|---|---|
| Incremental Aggregation | Not supported | Supported via incremental aggregation storage engine for improved query speed |
| High-Concurrency Queries | 1. Data is hash-distributed across all nodes regardless of table size, limiting concurrency 2. Frontend planner is a single node and cannot scale |
1. Supports various partitioning strategies; not all nodes involved in each query 2. Frontend planning is horizontally scalable |
| Column Sorting | Not supported | Supported for faster queries and better compression |
| Master High Availability | Manual failover with hot standby | FE nodes support automatic failover for high availability |
| Elastic Scaling | Requires full data redistribution and manual operation | Only partial data migration required; automatic and efficient |
| Data Fault Tolerance | Data mirrored across 2 nodes; complex recovery process | Data randomly distributed across 3 nodes; automatic recovery with high reliability |
| Resource Utilization | Only primary nodes compute; standby idle | All replicas participate in computation, improving utilization |
| Data Synchronization | No native support for syncing from Kafka/MySQL | Supports real-time syncing from Kafka/MySQL |
| Data Lake Integration | Not supported | Integrated access to Hive, Iceberg, Hudi, Paimon via Data Catalog |
| Storage-Compute Separation | Not supported | Supported, offering greater flexibility |
| Inverted Index | Not supported | Supported |
| SQL Support | Based on PostgreSQL, supports SQL-92 and some SQL:2003 features. Some proprietary dialects and limitations | Fully compatible with MySQL protocol and syntax; supports standard SQL, multiple storage models, and MySQL ecosystem tools |
| Execution Framework | 1. MPP architecture, Master coordinates Segments 2. Parallel query optimization with resource queues 3. Master node may become bottleneck |
1. Advanced MPP and vectorized execution engines 2. Supports pipeline execution for efficient parallelism 3. FE nodes scale horizontally, avoiding single points of failure |
| Application Scenarios | 1. Bulk data analytics like traditional data warehousing and ETL 2. Suitable for complex SQL analysis 3. Limited ecosystem and poor integration with data lakes or real-time pipelines |
1. Covers real-time analytics, lakehouse integration, structured data processing, observability 2. Supports high concurrency and throughput; ideal for real-time dashboards and behavior analysis 3. Ecosystem compatibility via MySQL protocol and mainstream BI tools |
| Maintainability | 1. Complex architecture with centralized Master-Segment control 2. Scaling requires full data redistribution 3. Fault recovery is complicated |
1. Simple architecture with easy FE/BE deployment 2. Auto scaling without full data redistribution 3. Built-in HA and auto-recovery lowers ops cost |
| Optimizer | 1. PostgreSQL-based query optimizer with parallel support 2. Configurable via optimizer parameters 3. Performance limited by Master node resources |
1. Advanced Cost-Based Optimizer (CBO) 2. Supports vectorized execution and runtime filters 3. Tight integration with execution engine for efficient query planning |
Summary
- Greenplum: Based on PostgreSQL, excels in bulk analytics and traditional data warehousing, offering rich SQL support and parallel processing. However, its complex architecture, high maintenance cost, and weak real-time and concurrency capabilities make it unsuitable for modern analytics.
- Apache Doris: With a streamlined MPP design, Doris excels in real-time analytics, concurrency, and lakehouse integration. Features like incremental aggregation, compute-storage separation, vectorized engines, and cost-based optimization make it performant, easy to manage, and ecosystem-friendly.
3. Use Cases and Ecosystem
Greenplum
Greenplum mainly targets bulk data analytics scenarios like traditional data warehousing and ETL tasks. Its ecosystem is relatively closed, lacking integration with modern data lakes and real-time data streams.
Apache Doris
Apache Doris supports a wide range of modern analytics scenarios, including:
-
Real-Time Analytics:
-
Real-time dashboards and decision-making
-
Interactive ad hoc analysis
-
User behavior analytics and profiling
-
-
Lakehouse Analytics:
-
Accelerated querying of Iceberg, Hudi, etc.
-
Cross-source federation to eliminate data silos
-
-
Semi-Structured Data Analytics:
-
Log and event analysis from distributed systems
-
Ecosystem Compatibility: Doris supports the MySQL protocol and standard SQL. It integrates seamlessly with BI tools such as Tableau, Power BI, and Apache Superset, offering low migration costs.
4. Technical Innovations
Greenplum
Greenplum builds on PostgreSQL’s technology, using row-based storage and MPP. However, it lacks advanced feature extensions and modern innovation.
Apache Doris
Doris introduces multiple technical innovations:
- Columnar Storage: Combines sorted compound keys, bloom filters, and inverted indexes to optimize performance and compression.
- Flexible Storage Models: Supports detail, primary key, and aggregation models for various scenarios.
- Materialized Views: Includes strong-consistency single-table and async multi-table materialized views for simplified modeling.
- Execution Engine: Implements vectorized and pipeline engines for sub-second querying.
5. Conclusion
In summary, Apache Doris outperforms Greenplum in features, performance, and applicability:
- More Comprehensive Features: Doris supports incremental aggregation, high concurrency, and data lake integration.
- Superior Performance: Benchmark tests show Doris can be several times faster in multi-table joins and complex queries.
- Broader Use Cases: Covers real-time, lakehouse, and semi-structured data analytics with strong ecosystem compatibility.
Greenplum remains suitable for traditional batch analytics, but its complex architecture, limited scalability, and closed ecosystem hinder its use in modern data platforms. Apache Doris offers high availability, compatibility, real-time capabilities, and technical innovations, making it a future-proof choice for building unified and efficient analytical platforms.
Published at DZone with permission of li yy. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments