How To Ensure Fast JOIN Queries for Self-Service Business Intelligence
JOIN queries are always a hassle, but yes, you can expect fast joins from a relational database. Read this and learn how.
Join the DZone community and get the full member experience.
Join For FreeA business intelligence (BI) tool is often the last stop of a data processing pipeline. It is where data is visualized for analysts, who then extract insights from it. From the standpoint of a SaaS BI provider, what are we looking for in a database? In my job, we are in urgent need of support for fast-join queries.
Why JOIN Query Matters
I work as an engineer that supports a human resource management system. One prominent selling point of our services is self-service BI. That means we allow users to customize their own dashboards: they can choose the fields they need and relate them to form the dataset as they want.
Join query is a more efficient way to realize self-service BI. It allows people to break down their data assets into many smaller tables instead of putting them all in a flat table. This would make data updates much faster and more cost-effective because updating the whole flat table is not always the optimal choice when you have plenty of new data flowing in and old data being updated or deleted frequently, as is the case for most data input.
In order to maximize the time value of data, we need data updates to be executed really quickly. For this purpose, we looked into three OLAP databases on the market. They are all fast in some way, but there are some differences.
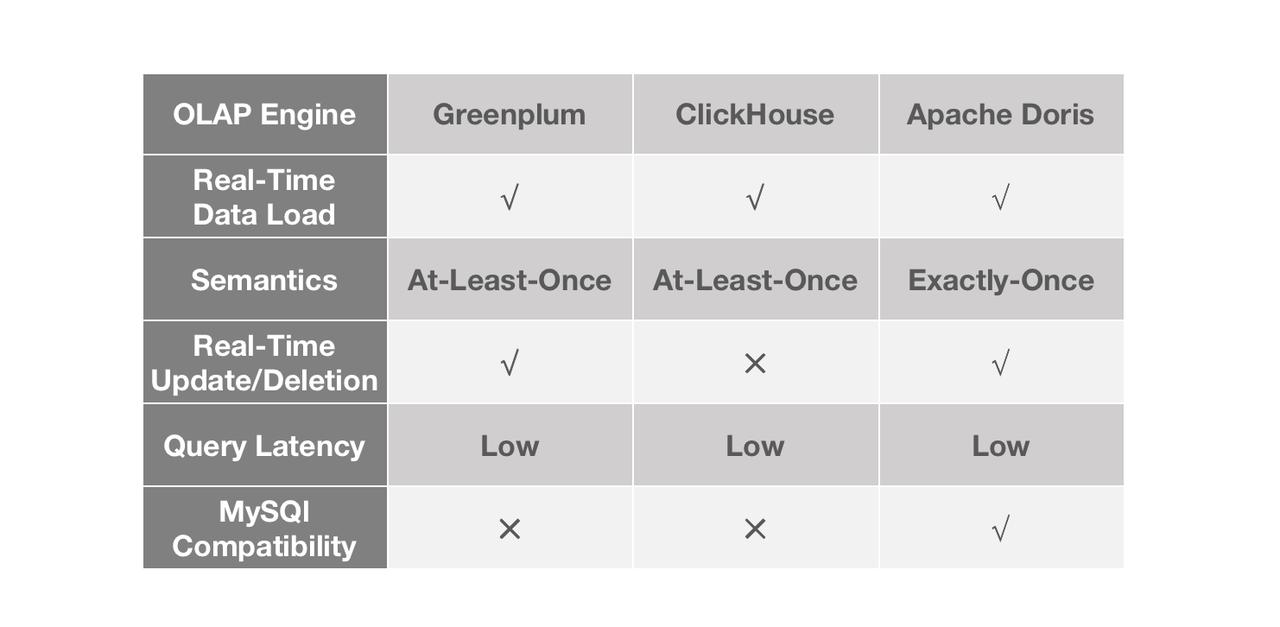
Greenplum is really quick in data loading and batch DML processing, but it is not good at handling high concurrency. There is a steep decline in performance as query concurrency rises. This can be risky for a BI platform that tries to ensure a stable user experience. ClickHouse is mind-blowing in single-table queries, but it only allows batch update and batch delete, so that's less timely.
Welcome To JOIN Hell
JOIN, my old friend JOIN, is always a hassle. Join queries are demanding for both engineers and the database system. Firstly, engineers must have a thorough grasp of the schema of all tables. Secondly, these queries are resource-intensive, especially when they involve large tables. Some of the reports on our platform entail join queries across up to 20 tables. Just imagine the mess.
We tested our candidate OLAP engines with our common join queries and our most notorious slow queries.
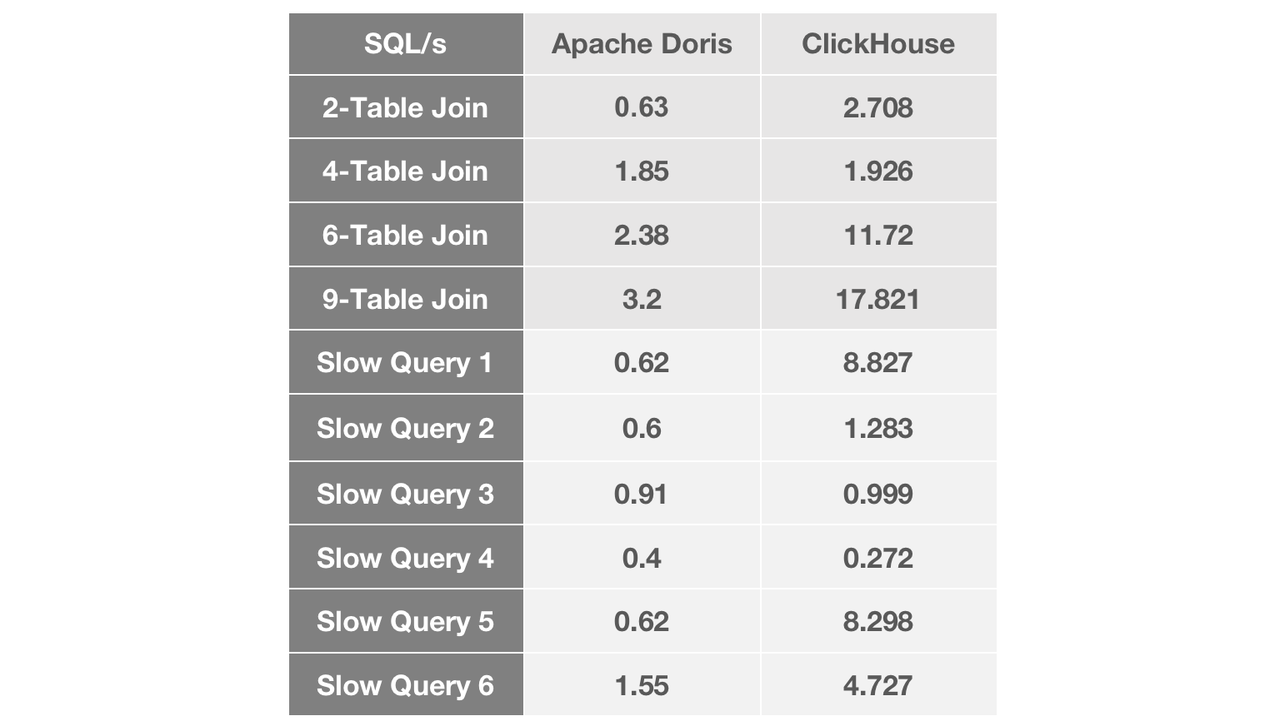
As the number of tables joined grows, we witness a widening performance gap between Apache Doris and ClickHouse. In most join queries, Apache Doris was about five times faster than ClickHouse. In terms of slow queries, Apache Doris responded to most of them within less than 1 second, while the performance of ClickHouse fluctuated within a relatively large range.
And just like that, we decided to upgrade our data architecture with Apache Doris.
Architecture That Supports Our BI Services
Data Input:
Our business data flows into DBLE, a distributed middleware based on MySQL. Then the DBLE binlogs are written into Flink, getting deduplicated, merged, and then put into Kafka. Finally, Apache Doris reads data from Kafka via its Routine Load approach. We apply the "delete" configuration in Routine Load to enable real-time deletion. The combination of Apache Flink and the idempotent write mechanism of Apache Doris is how we get an exactly-once guarantee. We have a data size of billions of rows per table, and this architecture is able to finish data updates in one minute.
In addition, by taking advantage of Apache Kafka and the Routine Load method, we are able to shave the traffic peaks and maintain cluster stability. Kafka also allows us to have multiple consumers of data and recompute intermediate data by resetting the offsets.
Data Output
As a self-service BI platform, we allow users to customize their own reports by configuring the rows, columns, and filters as they need. This is supported by Apache Doris with its capabilities in join queries.
In total, we have 400 data tables, of which 50 have over 100 million rows. That adds up to a data size measured in TB. We put all our data into two Doris clusters on 40 servers.
No Longer Stalled by Privileged Access Queries
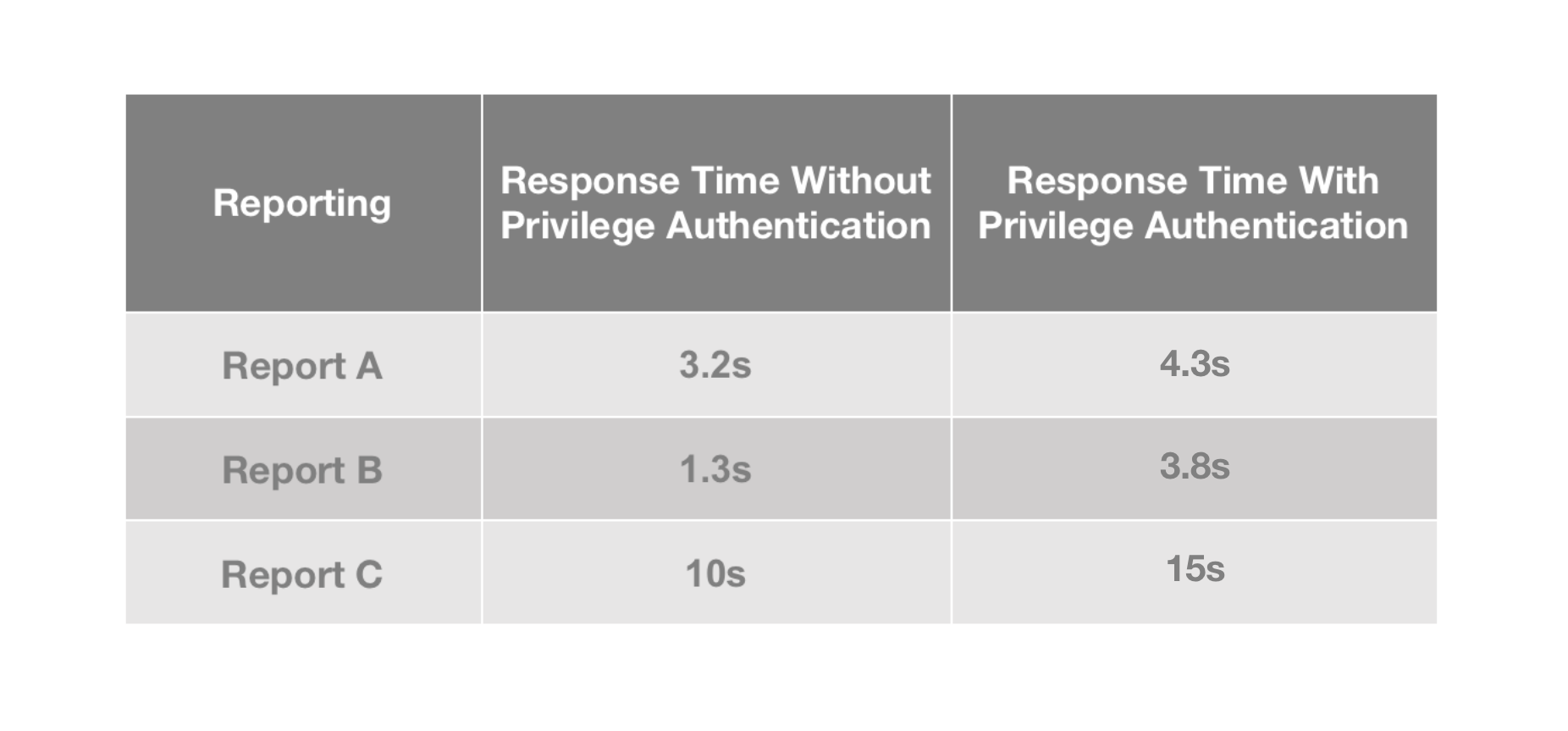
On our BI platform, privileged queries are often much slower than non-privileged queries. Timeout is often the case, and even more so for queries on large datasets.
Human resource data is subject to very strict and fine-grained access control policies. The role and position of users and the confidentiality level of data determine who has access to what (the data granularity here is up to fields in a table). Occasionally, we need to separately grant a certain privilege to a particular person. On top of that, we need to ensure data isolation between the multiple tenants on our platform.
How does all this add to the complexity of engineering? Any user who inputs a query on our BI platform must go through multi-factor authentication, and the authenticated information will all be inserted into the SQL via in and then passed on to the OLAP engine. Therefore, the more fine-grained the privilege controls are, the longer the SQL will be and the more time the OLAP system will spend on ID filtering. That's why our users are often tortured by high latency.

So, how did we fix that? We use the Bloom Filter index in Apache Doris.
By adding Bloom Filter indexes to the relevant ID fields, we improve the speed of privileged queries by 30% and basically eliminate timeout errors.
Tips on when you should use the Bloom Filter index:
- For non-prefix filtering
- For
inand=filters on a particular column - For filtering on high-cardinality columns, such as UserID. In essence, the Bloom Filter index is used to check if a certain value exists in a dataset. There is no point in using the Bloom Filter index for a low-cardinality column, like "gender", for example, because almost every data block contains all the gender values.
To All BI Engineers
We believe self-service BI is the future in the BI landscape, just like AGI is the future of artificial intelligence. Fast join queries are the way towards it, and the foregoing architectural upgrade is part of our ongoing effort to empower that. May there be fewer painful JOINs in the BI world. Cheers.
Published at DZone with permission of Paulman Cheung. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments