How Our gRPC Services Collapsed During Traffic Bursts — and What Finally Stopped It
A latency-driven dynamic rate limiter can keep gRPC services stable during traffic bursts by rejecting early instead of collapsing under queueing.
Join the DZone community and get the full member experience.
Join For FreeTraffic bursts don’t look dangerous at first. Most of the time, dashboards are still mostly green while the system is already drifting toward failure. That’s exactly what kept happening to us.
For a long time, our services behaved predictably. Traffic grew gradually. Autoscaling worked. Latency stayed reasonable. Things felt stable. Then we started seeing short, sharp traffic bursts — often triggered by promotions or external events. Request rates jumped within seconds. Autoscaling never had time to react. What followed became uncomfortably familiar.
Latency crept up slightly at first, sometimes due to CPU pressure or garbage collection. Requests kept getting admitted at full speed. Queues started growing. Retries kicked in. Threads saturated. Timeouts spiked. Throughput collapsed. By the time new capacity came online, a large part of the fleet was already unhealthy and slow to recover.
The most frustrating part wasn’t how bad these incidents were. It was how quickly everything unraveled. In more than one case, the system was already failing before alerts even fired.
Eventually, we had to accept something that felt counterintuitive at first: during traffic bursts, trying to serve every request is the wrong goal. The real goal is to shed load early enough that the system survives the burst and recovers on its own.
This article is about what we learned while getting there.
From Production Incidents to a Reproducible Model
The incidents I’m describing happened in real production systems. The dashboards shown below, however, come from a deliberately simplified gRPC sample service.
This demo doesn’t attempt to recreate our full production stack — there’s no autoscaling, no circuit breakers, and no static rate limits. That’s intentional. The goal is to isolate the failure mechanics that kept showing up during burst-related incidents: executor saturation, queue buildup, delayed completion signals, and latency-driven overload.
By stripping the system down to these essentials, the behavior becomes easier to see, reason about, and reproduce.
Why Autoscaling, Rate Limits, and Circuit Breakers Didn’t Save Us
We weren’t missing basic resilience mechanisms.
Autoscaling was too slow. Autoscaling reacts to lagging signals like CPU utilization. Traffic bursts overwhelmed services in seconds; autoscaling reacted minutes later. In a few incidents, the burst destabilized a large part of the existing fleet before new instances were ready, which actually reduced effective capacity.
Static rate limits didn’t age well. Conservative limits wasted capacity during normal traffic. Permissive limits did nothing during partial degradation. No single value worked across traffic conditions, and limits needed constant re-tuning as systems evolved.
Circuit breakers reacted after damage was visible. By the time breakers tripped, queues were already full, and user impact was obvious. In partial failures, breakers often oscillated, producing unstable throughput and making recovery harder.
All of these mechanisms reacted after the system was already in trouble. None helped much during the brief window when a burst first hit.
Why Queueing Made Things Worse, Not Better
Our first instinct was to rely on queues. If traffic spiked, let requests wait.
At the time, this felt reasonable. We even increased queue sizes to “buy time” during bursts. On dashboards, it looked fine at first. Throughput held. Error rates stayed low.
But when bursts lasted longer than expected, queues filled completely. Latency exploded. Retries piled on. Recovery took much longer than before.
What we eventually realized was that queueing delayed the overload signal. It hid the moment when the system crossed from stressed to unsafe. By the time failures became obvious, we were already digging out of a much deeper hole.
Burst Without Adaptive Concurrency
Sample application run without DRL enabled, showing:
- p99 latency climbing and flattening
- Queue depth growing
- Inflight requests piling up
- Request rate spike
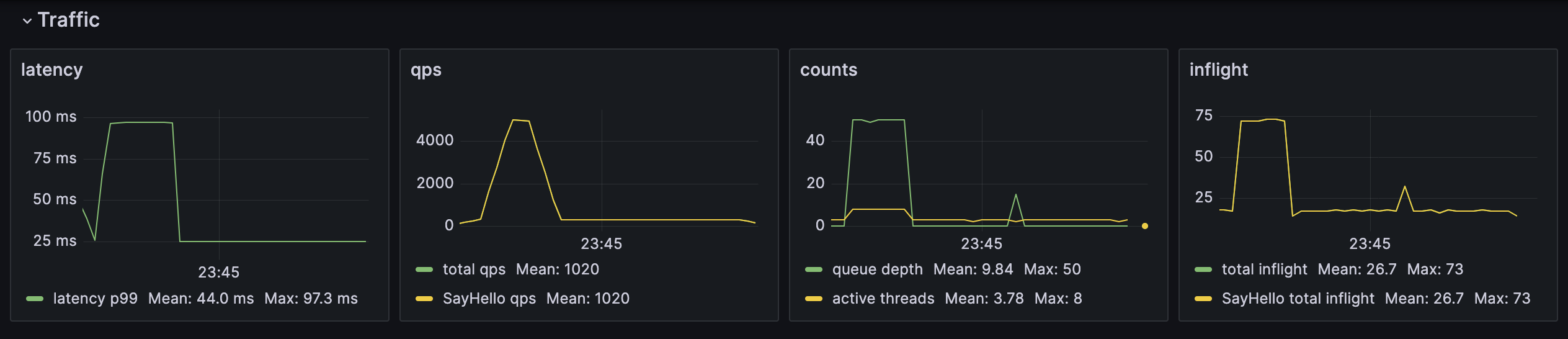
Traffic burst without adaptive concurrency (sample service)
Latency Was the Only Signal That Moved Early Enough
Across every burst-related incident we looked at, one signal moved first: latency.
Round-trip times increased almost immediately as queues started forming. CPU utilization, error rates, and other saturation metrics lagged behind. In several cases, the CPU still looked “fine” while the latency was already climbing rapidly.
Early on, this cost us time. The dashboards we trusted most were the least useful during bursts. Eventually, we stopped treating the CPU as the primary signal and started treating latency as the truth.
That shift pushed us toward controlling request admission based on latency, not raw resource utilization.
Introducing Adaptive Concurrency — and the Problems It Exposed
We introduced latency-driven adaptive concurrency using Netflix’s open-source concurrency-limits library.
The idea was straightforward:
- Measure request latency.
- Track a minimum baseline.
- Reduce allowed concurrency when latency rises.
- Reject excess requests immediately.
At first, this worked exactly how we hoped. During bursts, concurrency dropped within milliseconds. Queues stopped growing. The system stayed responsive long enough to recover.
Same Burst With Adaptive Concurrency
Sample app run with DRL enabled, showing:
- Adaptive concurrency limit changing
- Rejected requests rising early
- Acceptance ratio dipping and recovering
- p99 latency staying low
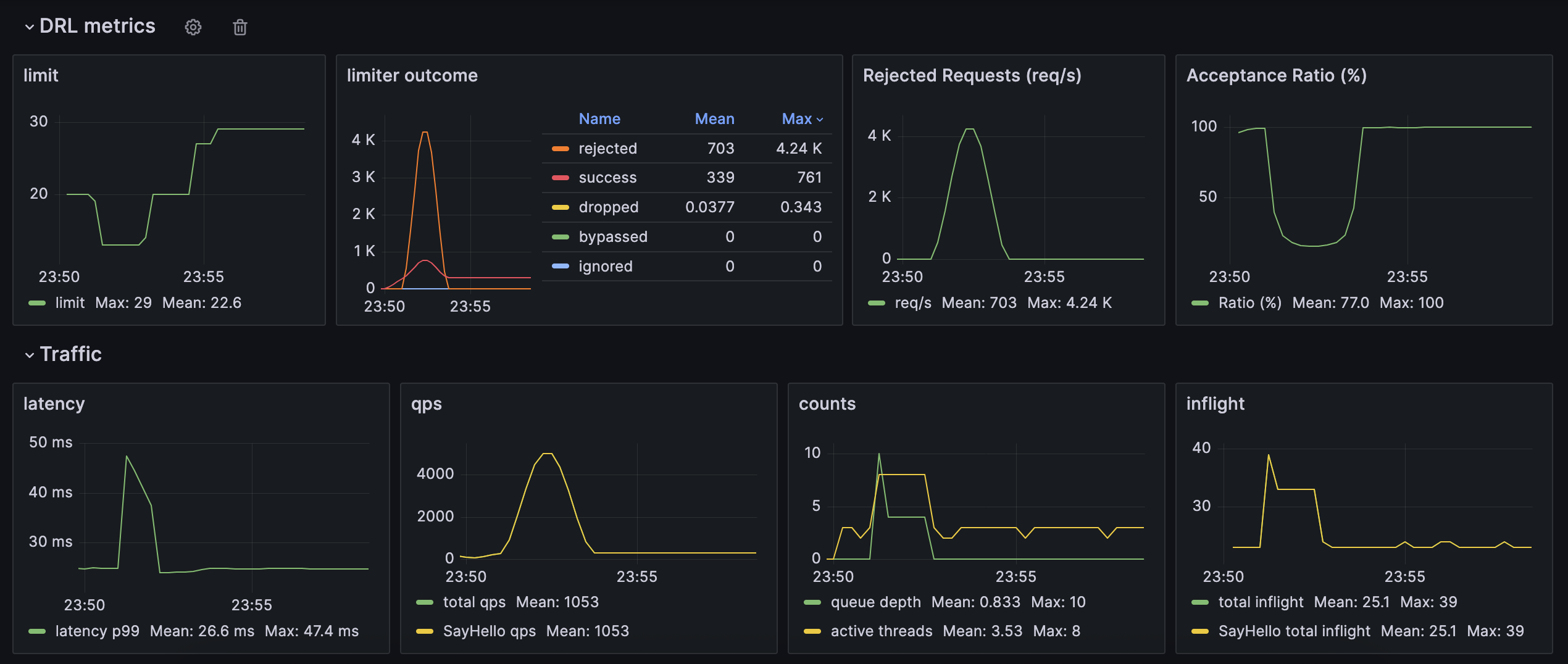
Adaptive concurrency during the same burst (sample service)
When the Requests Finished, But the System Never Noticed
After rolling this out, we ran into a problem that took time to understand.
Under heavy burst traffic, rejection rates sometimes stayed high even after traffic dropped back to normal. From the limiter’s point of view, some requests never finished. Concurrency permits were never released.
The root cause turned out to be executor saturation in gRPC Java. Completion callbacks were delayed or never scheduled when executors were overwhelmed. From the control loop’s perspective, those requests were never completed.
We fixed this by increasing executor queue capacity and adding explicit permit timeouts to reclaim leaked permits. Only then did rejection rates behave the way we expected during recovery.
When “Successful” Requests Looked Like Failures
Another issue took even longer to spot.
Some requests were completed normally, but didn’t emit terminal signals along every code path. Missing completion signals caused the limiter to record these requests as failures, tightening concurrency limits unnecessarily.
The fix wasn’t clever tuning — it was discipline. We audited gRPC request lifecycles end-to-end and made sure every request reliably emitted completion signals. Once failure classification matched reality, limiter behavior stabilized.
None of this showed up under steady load. It only appeared under extreme stress — exactly when adaptive control mattered most.
Tuning Never Really Stopped
Adaptive concurrency wasn’t something we configured once and forgot.
Growth rates, backoff behavior, and latency thresholds all affected stability. Different services behaved differently depending on traffic shape and downstream dependencies. Infrastructure changes shifted baseline latency enough to require retuning.
Even so, this was still easier than constantly revisiting static rate limits.
What Actually Changed
Adaptive concurrency didn’t eliminate failures. Some requests still had to be rejected.
What changed was how the system failed.
Before, bursts caused collapses: exploding latency, saturated queues, and long, manual recovery. After we started shedding load early, degradation became controlled. Throughput dipped instead of falling off a cliff. Recovery usually happened automatically once traffic normalized.
Early rejection felt uncomfortable at first. But it turned out to be far better than a late collapse.
What We Don’t Argue About Anymore
A few lessons are now non-negotiable for us:
- Traffic bursts will happen.
- Autoscaling doesn’t protect you during the burst itself.
- Queueing hides overload and slows recovery.
- Latency is the earliest useful signal — but only if request lifecycles are correct.
- Adaptive concurrency helps, but only if its assumptions hold.
Final Thoughts
Surviving traffic bursts isn’t about serving everything. It’s about failing early, failing predictably, and giving the system a chance to recover.
Most of these lessons weren’t obvious up front. We learned them only after systems failed faster than we expected and in ways we didn’t initially understand.
That experience is the point of this article.
Note on Reproducibility
To make these failure modes concrete and repeatable, I built a small Java 17 gRPC sample service that reproduces executor saturation, queue buildup, missing completion callbacks, and permit leaks under burst traffic. It includes a load generator and Grafana dashboards, similar to those shown above.
GitHub: https://github.com/parveensaini/grpc-adaptive-concurrency-demo
Opinions expressed by DZone contributors are their own.
Comments