Hadoop vs. Snowflake
This is an objective summary of the features and drawbacks of Hadoop/HDFS as an analytics platform and compare these to the cloud-based Snowflake data warehouse.
Join the DZone community and get the full member experience.
Join For FreeA few years ago, Hadoop was touted as the replacement for the data warehouse which is clearly nonsense. This article is intended to provide an objective summary of the features and drawbacks of Hadoop/HDFS as an analytics platform and compare these to the cloud-based Snowflake data warehouse.

Hadoop: A Distributed, File-Based Architecture
First developed by Doug Cutting at Yahoo! and then made open source from 2012 onwards, Hadoop gained considerable traction as a possible replacement for analytic workloads (data warehouse applications), on expensive MPP appliances.
Although in some ways similar to a database, Hadoop Distributed File System (HDFS), is not a database with the corresponding workload, read consistency, and concurrency management systems. While Hadoop has many similarities to an MPP database including its multi-node scalability, its support for columnar data format, use of SQL, and basic workflow management, there are many differences which include:
- No ACID compliance: Unlike Snowflake, which supports multiple concurrent read-consistent reads and updates complete with ACID compliance, HDFS simply writes immutable files with no updates or changes allowed. To change a file, (for the most part), you must read it in, and write it out with the changes applied. This makes HDFS more suitable for very large volume data transformation, but a poor solution for ad-hoc queries.
- HDFS is for large data sets: Unlike Snowflake, which stores data on variable length micro-partitions, HDFS breaks down data into fixed sized (typically 128Mb) blocks which are replicated across three nodes. This makes it a poor solution for small data files (under 1GB) where the entire data set is typically held on a single node. Snowflake, however, can process tiny data sets and terabytes with ease.
- HDFS is not elastically scalable: Although it’s possible (with downtime) to add additional nodes to a Hadoop cluster, the cluster size can only be increased. This compares poorly to Snowflake which can instantly scale up from an X-Small to a 4X-Large behemoth within milliseconds, then quickly scale back or even completely suspend compute resources.
- Hadoop is very complex: Perhaps the biggest single disadvantage of Hadoop is the legendary cost of deployment, configuration, and maintenance. This compares poorly to Snowflake, which requires no hardware to deploy or software to install and configure. Statistics are automatically captured, and used by a sophisticated cost-based query tool, and DBA Management is almost zero.
The diagram below illustrates the key components in a Hadoop/HDFS platform. It illustrates how a Name Node is configured to record the physical location of data distributed across a cluster.

While this delivers excellent performance on massive (multi-terabyte) batch processing queries, the diagram below illustrates why it’s a poor solution for general purpose data management.

The diagram above illustrates how the Service Layer manages concurrency, workload and transaction management. Unlike the Hadoop solution, on Snowflake data storage is kept entirely separate from compute processing which means it’s possible to dynamically increase or reduce cluster size.
The above solution also supports built-in caching layers at the Virtual Warehouse and Services layer. This makes Snowflake a suitable platform for a huge range of query processing, from petabyte scale data processing, to sub-second query performance on dashboards.
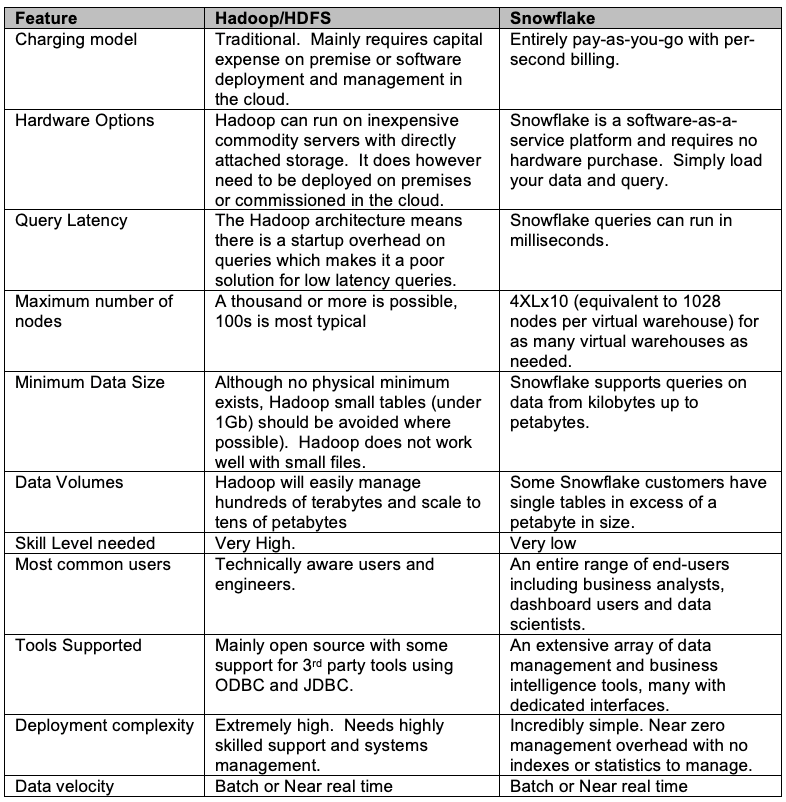
The table below provides a simple side-by-side comparison of the key features of Hadoop and Snowflake:
"Most of those who expected Hadoop to replace their enterprise data warehouse have been greatly disappointed." James Serra
The primary advantage posited by Hadoop was the ability to manage structured, semi-structured (JSON), and unstructured text with support for schema-on-read. This meant it was possible to simply load and query data without concern for structure.
While Hadoop is certainly the only platform for video, sound, and free text processing, this is a tiny proportion of data processing, and Snowflake has full native support for JSON, and even supports both structured and semi-structured queries from within SQL.
Conclusion
In conclusion, while it’s possible to achieve good batch query performance on very large (multi-terabyte) sized data volumes using brute force, Hadoop is remarkably difficult to deploy and manage, and has very poor support for low latency queries needed by many business intelligence users.
Having failed to capture significant MPP database market share, Hadoop is being touted as the recommend platform for a Data Lake – an immutable data store of raw business data. While this may be a suitable platform to repurpose an existing Hadoop cluster, it does have the same drawbacks of MPP solutions, in potentially over-provisioning compute resources as each node adds both compute and storage capacity. It’s arguable that a cloud-based object data store (eg. Microsoft Blob Store or Amazon S3) is a better basis for a data lake, making use of the separation of compute and storage to avoid over-provisioning. However, with the Snowflake support for real-time data ingestion and native JSON support, this is an even better platform for the data lake.
Where perhaps Hadoop does have a viable future is in the area of real-time data capture and processing, using Apache Kafka and Spark, Storm or Flink, although the target destination should almost certainly be a database, and Snowflake is the clear winner in data warehousing.
As a replacement for an MPP database, however, Hadoop falls well short of the required performance, query optimization, and low latency required, and Snowflake stands out as the best datawarehouse platform on the market today.
Disclaimer: The opinions expressed in my articles are my own, and will not necessarily reflect those of my employer (past or present) or indeed any client I have worked with.
This article was first published on Analytics.Today at: Hadoop Vs Snowflake.
Published at DZone with permission of John Ryan. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments