Hazelcast: Introduction and Clustering
In this article, we take an introductory look at the Java-based tool Hazelcast, with a focus on clustering.
Join the DZone community and get the full member experience.
Join For FreeEvery time I read the term Hazelcast, it makes a picture of some weather forecast in my mind like a forecast of hazy situations.
According to Wikipedia, Hazelcast IMDG is an open-source in-memory data grid based on Java. Hazelcast provides central, predictable scaling of applications through in-memory access to frequently used data and across an elastically scalable data grid. These techniques reduce the query load on databases and improve speed. Hazelcast is now one of the renowned caching technology in the market associated with distributed computing.
Oops, that is a lot to grab in a single statement. So, let's take this subject point by point. The term caching refers to the substitute memory space provided for faster access to data. Some relevant caching engines are available such as Redis, Gridgain, etc. But today we will be learning about Hazelcast.
General Trivia
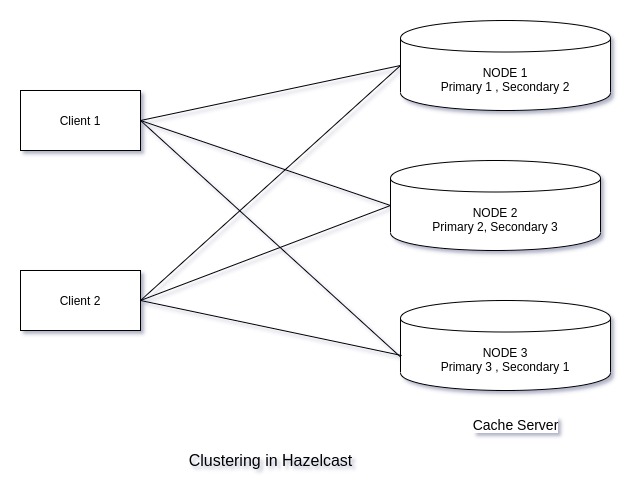
Hazelcast is an in-memory data grid for clustering and highly scalable data distribution. One of the main features of Hazelcast is not having a master node. Instead, every node is configured in the same manner in terms of functionality. Each node maintains a partition table that contains the metadata i.e., cluster health, backup information, re-partitioning, etc., of every node in a cluster. The primary node (the earliest node created in the cluster) performs the data assignment in the cluster.
All clients in Hazelcast also have limited metadata of the cluster. Therefore a client can directly connect to any node of the cluster and hence helps in faster availability of data. Another major feature of Hazelcast is that the data in the cache is copied multiple times across the nodes, thus helps in handling the failover condition. If any node fails another node provides data to the client till the failed node comes up hence provide better availability.
Clustering
As mentioned above, Hazelcast always ensures two things for its client one is the availability and the other is fault tolerance. And both these functionalities can work only because of the cluster of caches in the ecosystem of the cache server. The cluster caches when formed always communicate over a TCP network regardless of their proximity.
Stay tuned for the next article in which we will be configuring the Hazelcast server.
Opinions expressed by DZone contributors are their own.
Comments