High-Cardinality Threat Detection: Why MapReduce Breaks and Heuristics Win
Scalable systems that succeed don’t process more — they ignore more, using heuristics to isolate the small fraction of activity that actually matters.
Join the DZone community and get the full member experience.
Join For FreeThe Fundamental Problem: Signal Is Infinitesimal Compared to Noise
Modern cloud systems operate at a scale where traditional data processing assumptions begin to break down. In large distributed environments, telemetry pipelines routinely process tens of billions of events per minute across millions of users, accounts, and resources.
At this scale, the objective of threat detection is often misunderstood. The goal is not to process data — it is to extract actionable signals for incident response.
The critical observation is simple, but non-intuitive:
By design, almost all data is benign.
For any given key — such as a combination of user, account, action, and source — the overwhelming majority of activity falls within expected behavior. Only a tiny fraction represents anomalies such as abuse, credential compromise, or unintended automation.
This imbalance introduces two fundamental challenges.
First, key cardinality becomes extremely high. Most keys appear once, or only a handful of times, within any given time window. The system is forced to track a vast number of unique identifiers, the majority of which will never become relevant.
Second, signals are sparsely distributed. The events that matter — the ones that indicate potential threats — are rare, but carry disproportionate importance. Missing them is not acceptable, but exhaustively processing everything to find them is not scalable.
Under these conditions, traditional aggregation approaches begin to lose their advantage. Systems built on MapReduce-style paradigms rely on the assumption that data can be meaningfully reduced through grouping and aggregation. That assumption does not hold when most keys are unique, and most activity is noise.
When the input size approaches the output size, there is no real reduction taking place. The system spends the majority of its resources maintaining state and processing events that will never contribute to a detection.
At that point, the bottleneck is no longer compute capacity — it is the system’s inability to ignore what does not matter.
Where MapReduce Works — and Where It Breaks
Before discussing alternatives, it is important to acknowledge that MapReduce-style systems are highly effective — when applied to the right class of problems.
At a high level, the model is simple. The map phase transforms incoming data into key-value pairs. The reduce phase aggregates values for each key, producing a condensed representation of the dataset.
This approach works well when aggregation leads to a meaningful reduction.
Consider counting page views per URL across billions of requests. While the input volume is massive, the number of unique URLs is relatively bounded. Millions or billions of events collapse into a much smaller set of aggregated counts. The system compresses the data as it processes it.
In this setting, the overhead of grouping and shuffling data is justified because the output is significantly smaller than the input.
Threat detection, however, does not behave this way.
Security telemetry is typically keyed on combinations such as:
(user_id, account_id, action, resource, source_ip)This key space is effectively unbounded. It evolves continuously with user behavior, infrastructure changes, and external interactions.
Most keys appear once. Some appear a few times. Very few appear frequently enough to matter.
When MapReduce is applied here, aggregation does not reduce the dataset — it merely reorganizes it.
The system pays the full cost of aggregation without realizing its benefits.
State must be maintained for an enormous number of keys. Data must be shuffled across nodes to ensure correct grouping. The output remains nearly as large as the input because almost every key contributes a single record.
This is the fundamental mismatch. MapReduce assumes that aggregation compresses data. High-cardinality threat detection violates that assumption.
A Concrete Example: When the System Starts to Hurt
Consider a scenario where an IAM principal begins issuing a burst of mutating API calls—creating roles, attaching policies, and modifying permissions across multiple accounts.
This pattern is often associated with credential compromise or automated abuse.
A detection might look like:
Alert if a single
(principal, source_ip)pair performs more than 100 mutating IAM actions within 5 minutes.
In a real environment, millions of principals are active at any given time. Most perform one or two operations and stop. Some perform legitimate bursts due to deployments or automation workflows. A very small fraction represents potential abuse.
A naive system will track every (principal, source_ip) pair. It will maintain state, update counts, and evaluate thresholds for all of them.
Meanwhile, the one key that actually matters — the compromised principal — moves through the same pipeline as everything else.
The system is functioning correctly, but inefficiently. It spends most of its effort processing keys that will never cross the detection threshold.
From Exactness to Selectivity
The turning point comes when the problem is reframed.
Instead of attempting to compute exact counts for every key, the system first determines which keys are worth tracking at all.
Reduction must happen before aggregation.
This introduces a form of selective attention into the pipeline.
Early stages apply lightweight, probabilistic techniques to eliminate obvious noise. Keys that appear only once — or exhibit behavior unlikely to lead to a signal — are deprioritized immediately.
Keys that show repeated activity are then tracked using approximate counting methods. These methods do not aim for exactness. They aim to answer a simpler question: Is this key becoming significant?
Only a small subset of keys — those that appear to be trending toward anomalous behavior — are promoted to later stages for precise evaluation.
This shifts the system from exhaustive computation to targeted analysis.
Heuristics That Make This Possible
Two classes of techniques are particularly effective in enabling this shift.
The first is probabilistic membership filtering. Structures such as Bloom filters allow the system to quickly determine whether a key has been seen before. Single-occurrence keys, which dominate the dataset, can be filtered out early without maintaining explicit state for each one.
The second is approximate frequency tracking. Structures such as Count-Min Sketch provide a compact way to estimate how often a key appears. While the counts are not exact, they are sufficient to identify keys whose activity is increasing and may cross a detection threshold.
These techniques share an important property: their cost is independent of the number of unique keys. Memory usage and computation are bounded, even as cardinality grows.
In practice, they allow the system to discard the majority of data before it reaches expensive stages of processing.
Why This Model Scales
This approach fundamentally changes how the system scales.
Instead of maintaining state proportional to the number of unique keys, the system maintains state proportional to the size of its probabilistic structures. Communication between nodes is similarly bounded, as these structures can be merged without requiring per-key coordination.
More importantly, expensive operations are applied selectively.
Exact aggregation is no longer the default path for all data. It is reserved for a small subset of keys that have already demonstrated potentially anomalous behavior.
This leads to a significant reduction in resource usage across the pipeline — compute, memory, and network.
In practice, the majority of events are filtered or summarized early, allowing the system to focus its resources on the small fraction of activity that may represent a real threat.
How This Looks in a Real Pipeline
A practical system can be thought of as a staged funnel.
Incoming events first pass through a lightweight filtering layer that removes one-off or low-signal keys. The remaining events are then processed by an approximate counting layer that identifies keys with increasing activity.
Only those keys are promoted to an exact aggregation layer, where precise counts are computed, and detection logic is applied.
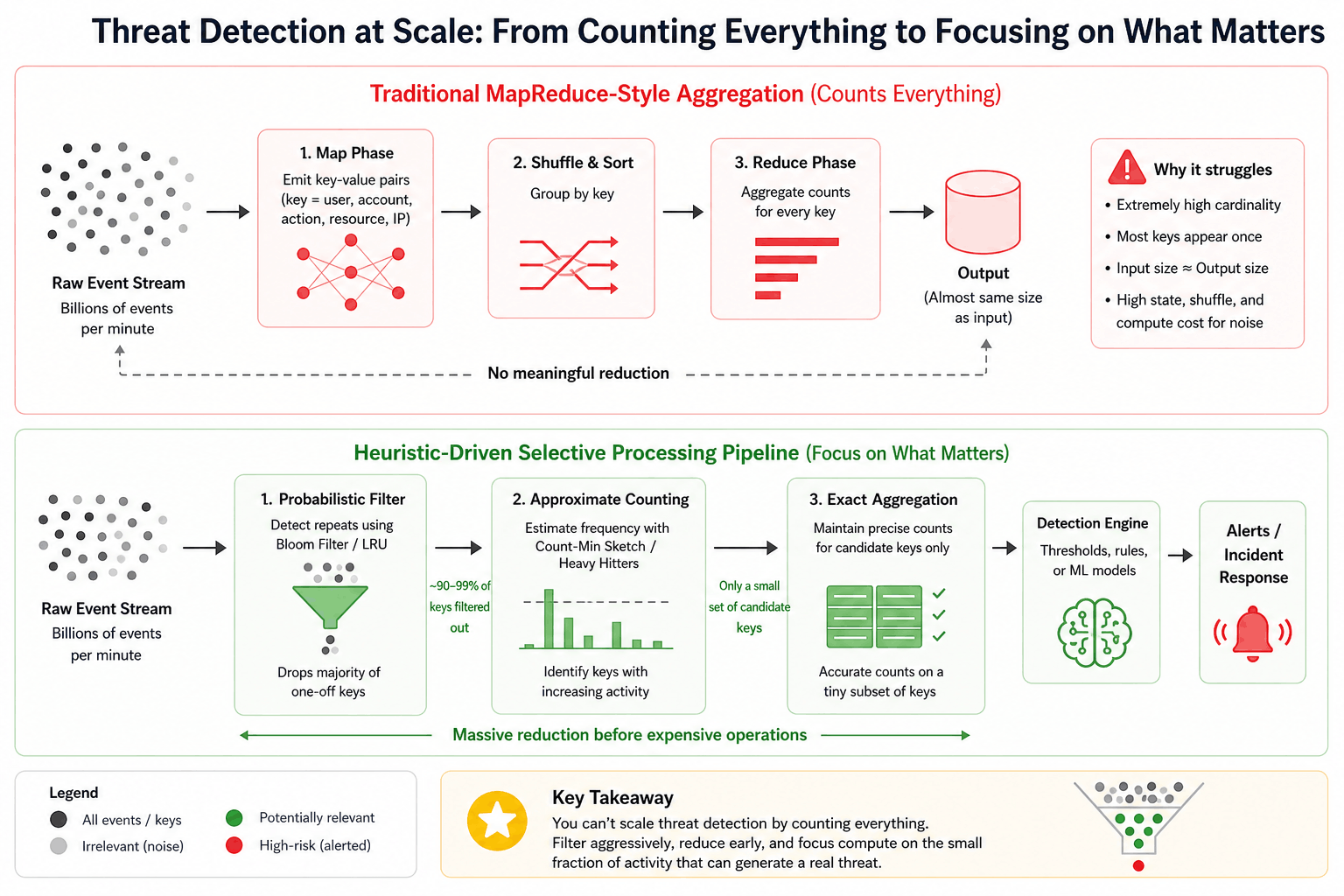
Each stage reduces the volume of data that flows into the next. By the time the system reaches exact aggregation, it is operating on a very small subset of the original stream.
Closing Observation
The instinct in distributed systems is often to scale computation to match data volume. In threat detection, that instinct leads to diminishing returns. The more effective approach is to reduce the amount of data that requires precise computation. At a large scale, the challenge is not computing aggregates efficiently. It is deciding which aggregates are worth computing at all. Once that distinction is made, the system becomes both simpler and scalable.
Opinions expressed by DZone contributors are their own.
Comments