How Carbon Uses PrestoDB With Ahana to Power Real-Time Customer Dashboards
Why ad tech company Carbon chose Presto on AWS for SQL data lake analytics.
Join the DZone community and get the full member experience.
Join For FreeThe author, Jordan Hoggart, was not compensated by Ahana for this review.
The Background
At the base of Carbon’s real-time, first-party data platform is our analytics component, which combines a range of behavioral, contextual, and revenue data, which is then displayed within a dashboard in a series of charts, graphs, and breakdowns to give a visual representation of the most important actionable data. Whilst we pre-calculate as much of the information as possible, there are different filters that allow users to drill deeper into the data, which makes querying critical.
AWS Athena – The Good and the Bad
For the past 2 years, Athena has been our Presto provider of choice. Athena is Amazon’s offering of a serverless query engine, using Presto under the hood. The serverless nature of the service made it very easy to get going as all of our data already lived in S3, so Athena was more than capable of running any query we threw at it. The biggest benefit by far was the fact we only paid for what we used, specifically data scanned — no need to worry about over/under provisioning a cluster.
Once more data was coming in, Athena started to show signs of struggle. Anyone who has pushed Athena too far will recall the dreaded “Resources exhausted at this scale factor” error — the message you get when you hit the memory limit for the query. Amazon’s advice here is to write better queries that don’t hit the limit. While we can all agree it’s decent advice, it doesn’t help when you hit the tipping point with data where scaling is necessary. This effectively gave us a hard cap on the compute power we had available and in the long run was only going to cause bigger headaches.
Another big drawback is the single tenant nature of the service. Athena is a resource that is shared between all AWS accounts. Each account has restrictions applied in the way of a concurrency limit — the docs say 20 but in some cases, we’ve seen queries entered a “queued” state as low as 2. Along with this, each account only gets a single queue, which means it’s possible for any random query to block a production dashboard query from running.
It’s worth saying that Athena really shines for running low-importance ad-hoc queries. We still make use of it for some quick data science checks that are fine to sit in a queue for a bit. It’s also great at running infrequent stuff like queries for gathering metrics. We have a system in place that runs a bunch of quick queries and sends results to Grafana, it basically costs nothing. Athena is a fantastic tool but in the wrong use case it can really leave your hands tied, but we needed something to meet the demand of our more intensive queries. Enter Ahana Cloud.
Ahana Cloud
Ahana Cloud is a service that takes care of the annoying parts of getting a cluster going. It makes use of cloud formation templates to set up the compute plane and launch any Presto clusters with configuration that’s defined in either a web UI or API. This kept the operational complexity down while giving us the ability to scale the cluster to what we needed. The cluster gets deployed in AWS and has connectors for glue so we didn’t have to shift data about and could get straight to testing.
One of the biggest concerns was that we had no idea how powerful Athena actually was. We had a rough idea of the scale of query that would cause it to fail, but couldn’t really tell what sort of node configuration it was using behind the scenes. So the first thing we did was set up a bunch of different cluster configurations to try and get a performance similar to Athena.
Ahana and the Numbers
From the dashboard, we picked the seven most important queries for benchmarking covering queries on overview data, brand, date, location, site, interest categorization data, and demographics. Even on a relatively small cluster we started to see query times that were the same, if not better, than Athena. The categorization and demographic breakdowns were pulling in the most data, around 4 billion rows, so they were always going to be the toughest. Even then it was good to see that we could get close. There was always the fear that we would have had to provision a cripplingly large cluster to get the performance we wanted. Although the cost was definitely going to be more than Athena, this showed it was viable and would give us the stability we were after.

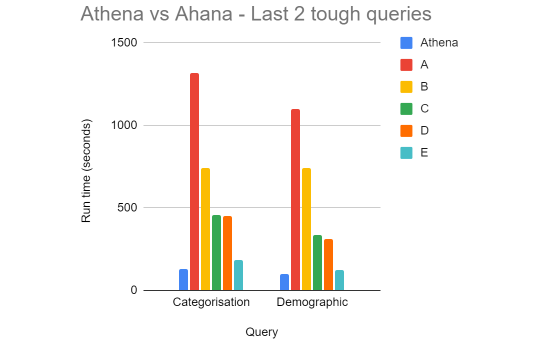
From the dashboard, we picked the seven most important queries for benchmarking covering queries on overview data, brand, date, location, site, interest categorization data and demographic. Even on a relatively small cluster, we started to see query times that were the same, if not better, than Athena. The categorization and demographic breakdowns were pulling in the most data, around 4 billion rows, so they were always going to be the toughest. Even then it was good to see that we could get close. There was always the fear that we would have had to provision a cripplingly large cluster to get the performance we wanted. Although the cost was definitely going to be more than Athena, this showed it was viable and would give us the stability we were after.
| Cluster Name | Worker config | $/hr* |
| Athena | ? | ? |
| A | 3 x c5.2xlarge | 1.02 |
| B | 5 x c5.2xlarge | 1.70 |
| C | 10 x c5.xlarge | 1.70 |
| D | 20 x c5.large | 1.70 |
| E | 10 x c5.2xlarge | 3.40 |
Having our own cluster also lets us go a bit further with optimization. Before we couldn’t make use of session parameters, which meant we couldn’t do things like influence the join strategy. After a bit of parameter tweaking, swapping from parquet to the ORC data format and using a hive metastore, we found a setup that actually gave a decent speed boost to the queries. Across all queries, it gave around a 90% speedup.
| – | Overview | Brand | Categorisation | Date | Demographic | Location | Site |
| Before | 7 | 11 | 183 | 8 | 121 | 8 | 6 |
| After | 5 | 3 | 122 | 5 | 98 | 3 | 4 |
Key Takeaways
Overall, Presto makes it easy to query data without shifting it around and there are some great options to get going with various connectors. Whilst Athena is great for running small volume loads, it can be sensitive to issues such as its single query queue and low compute ceiling — both of which can limit query speed and scale. When seeking something that allows for more scale Ahana Cloud provides a good next step with more control over your own cluster, as well as more predictable performance.
Published at DZone with permission of Jordan Hoggart. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments