AWS Multi-Region Resiliency Aurora MySQL Global DB With Headless Clusters
In this article, the reader will learn how to perform a failover with a headless Aurora Global Database and its outcomes.
Join the DZone community and get the full member experience.
Join For FreeA headless cluster in Amazon Aurora global database refers to a cluster that has no database instance attached to it. In other words, the cluster only includes the database storage and is used as a backup in case of a failure of the primary cluster. The primary cluster is the one that has a database instance attached to it and is serving the application's read and write requests. The headless secondary cluster is used for disaster recovery and to provide high availability for the database. The data in the primary cluster is automatically replicated to the headless secondary cluster, so in case of a failure, the secondary cluster can take over as the primary cluster and provide a seamless transition with minimal disruption.
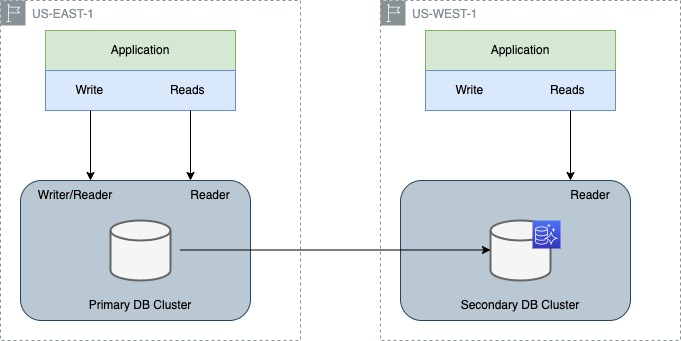
In this article, we will see how to perform a failover with a headless Aurora Global Database and its outcomes.
Steps To Create Aurora Global Database
I’ve created an RDS database (named "testaurocluster") and created a global cluster using the AWS CLI using the following commands:
Create a Global Cluster
aws rds create-global-cluster --region us-east-1 \
--global-cluster-identifier global-cluster \
--source-db-cluster-identifier arn:aws:rds:us-east-1:<AWSAccountId>:cluster:testauroclusterCreate a Headless Secondary Cluster
aws rds create-db-cluster \
--region us-west-1 \
--source-region us-east-1 \
--db-cluster-identifier testaurocluster\
--global-cluster-identifier global-cluster \
--engine aurora-mysql \
--engine-version 5.7.mysql_aurora.2.10.2 \
--kms-key-id <key value> KMS Key
Make sure you used the correct KMS key before running the above command. (The KMS key should belong to the region where you are going to create the secondary cluster, i.e., us-west-1).
Cloud Watch Metric Health Check
Create a CloudWatch metric for health checks:
- Log in to the Amazon Web Services (AWS) Management Console.
- Navigate to the RDS service.
- Select the RDS cluster you want to monitor.
- Click on the "Metrics" tab.
- Click on the "Create Alarm" button.
- Select the "RDS" namespace and the "DBInstanceIdentifier" dimension.
- Choose the metric (e.g., CPUUtilization).
- Set the alarm threshold (e.g., greater than or equal to 75%).
- Choose the desired alarm actions (e.g., sending an SNS notification).
- Give the alarm a name and description (optional).
- Click the "Create Alarm" button.
Your CloudWatch metric for CPU utilization of the RDS cluster is now set up. The alarm will trigger the specified actions if the CPU utilization exceeds the threshold.
Health Check Using Route 53
- Log in to the Amazon Route 53 console.
- Choose "Health checks" from the navigation panel.
- Choose "Create health check."
- Give your health check a name and choose "CloudWatch Alarm" as the type.
- Choose the appropriate alarm from the list. The alarm should reflect the health of your RDS cluster.
- Choose "Create."
- Once the health check has been created, you can use it in a Route 53 record set to route traffic to your RDS cluster.
This will allow Route 53 to monitor the state of the CloudWatch alarm and redirect traffic to a healthy endpoint if one of your instances becomes unavailable. The state of the CloudWatch alarm should reflect the health of your RDS cluster, so you will need to set up the alarm appropriately in CloudWatch.
Route53 Hosted Zone
Create a Route53 Hosted Zone:
- Open the Route 53 management console in the AWS Management Console.
- In the navigation pane, choose "Hosted zones."
- Choose "Create Hosted Zone."
- In the "Create Hosted Zone" dialog box, enter a domain name for the hosted zone.
- Choose "Create"
Create a DNS Record for the DB Cluster:
- In the Route 53 management console, select the hosted zone that you created in Step 2.
- Choose "Create Record. " Add the record’s name.
- In the "Create Record " dialog box, set the type of record to "A" or "CNAME," depending on your use case.
- Check the alias button and fill in the option as required. Choose the endpoint and enter the endpoint of the cluster in the field.
- Select failover as a route policy and choose failover record type as primary. Add the health check ID that was created in the previous step. Give a name to record the ID.
- Click on add record button and add one more record for a secondary cluster.
- Choose "Create"
Pre-Failover Step
Before proceeding with failover, you must add a DB instance to an existing headless cluster in the secondary region. After a failover, the headless secondary cluster becomes the primary cluster and takes over the role of serving the read and write requests from the application.
It needs to configure the new database instance with the necessary settings, such as the database engine type, storage type, and instance size, and then connect it to your application.
It is important to have a well-defined disaster recovery plan in place to ensure that you can quickly and effectively respond to a failover event.
Using the AWS CLI command to add a DB instance to an existing headless cluster in the secondary region:
aws rds create-db-instance \
--db-instance-identifier testaurocluster-instance-1 \
--db-cluster-identifier testaurocluster\
--db-instance-class db.r5.large \
--engine aurora-mysql \
--region us-west-1CloudWatch Dashboard
Create a CloudWatch dashboard to check the metrics over time and quickly see any changes or trends in performance after deleting the read instance.
- Log in to the AWS Management Console.
- Navigate to the CloudWatch service.
- Click on "Dashboards" in the left navigation panel.
- Click on the "Create dashboard" button.
- Give the dashboard a name and choose a preferred layout.
- Click on the "Add widget" button to add the relevant metrics to the dashboard.
- Select the metrics you want to add and set the desired time range for them.
- Customize the appearance of the widget if desired, such as adding a title, axis labels, and legend.
- Click on the "Save dashboard" button to save the dashboard.
Failover Process Steps
- Navigate to the RDS Console and select the target global database for which you want to perform a failover.
- Initiate a failover. You will be prompted to select a target instance to which to perform the failover.
- After the failover is initiated, you can verify that it has been completed by checking the status of the target instance in the RDS Console. The target instance should now be in the "available" state, and the original primary instance should now be in the "failover" state.
- Monitor the failover: After the failover is complete, it is important to monitor the performance of the new primary instance to ensure that it is serving traffic as expected. This can be done through Amazon CloudWatch, or by monitoring the performance of your application.
Failover Time
It took a few minutes to complete the failover process (time can be tracked using RDS event logs). However, the failover of a global Amazon Aurora cluster can take anywhere from a few minutes to several hours, depending on the following factors.
- Network latency (the time it takes to redirect traffic from the primary cluster to the secondary cluster will depend on the network latency between the two clusters).
- Size of the database (larger databases will take longer to failover than smaller databases).
- Performance of the secondary cluster (performance of the secondary cluster, as a slower secondary cluster will take longer to start serving traffic than a faster secondary cluster).
- Application requirements (specific requirements of your application, such as the amount of data that needs to be recovered or the number of updates that need to be made to your DNS records).
In the secondary (previously headless) Amazon Aurora database cluster, there is only one instance. When the secondary cluster becomes the primary cluster after a failover, this single instance acts as both the reader and writer instances. It serves to read requests from the application and updates the database, making it the new primary writer instance.
It's important to note that in Amazon Aurora, the reader and writer instances are separate and can be managed independently, even in the same cluster. However, in the case of a headless secondary cluster, there is only one instance that acts as both the reader and writer. This single instance is designed to provide a cost-effective solution for disaster recovery, as it eliminates the need for a separate reader instance in the secondary cluster.
Conclusion
In conclusion, performing a failover with a headless Aurora Global Database can provide significant benefits for achieving cost-effective multi-region resiliency.
Opinions expressed by DZone contributors are their own.
Comments