Web Crawling for RAG With Crawl4AI
Automate web crawling and data extraction to natural language processing with Crawl4AI for RAG applications in your enterprise.
Join the DZone community and get the full member experience.
Join For FreeThe importance of AI-powered web crawling and data extraction cannot be overstated. With the exponential growth of online data, businesses and organizations need efficient and accurate methods for collecting and analyzing data to inform their decision-making processes. Crawl4AI and Ollama offer a range of features and benefits that can help address these challenges, from automated web crawling and data extraction to natural language processing and machine learning.
Crawl4AI is a powerful tool for AI-powered web crawling and data extraction. It offers a range of features and benefits, including automated web crawling, data extraction, and natural language processing. With Crawl4AI, users can easily extract data from websites, social media platforms, and other online sources, and then analyze and visualize the data using a range of tools and techniques. Crawl4AI is particularly useful for data scientists and machine learning engineers who need to collect and analyze large datasets for their projects.
One of the key benefits of using Crawl4AI is its ability to handle complex web crawling tasks with ease. It can navigate through multiple web pages, extract relevant data, and store it in a structured format for further analysis. Crawl4AI also offers a range of customization options, allowing users to tailor the tool to their specific needs and requirements. For example, users can specify the types of data they want to extract, the frequency of web crawling, and the format of the output data.
On the other hand, Ollama is an open-source project that enables running Large Language Model (LLM) models locally. It provides both Command-Line Interface (CLI) and Application Programming Interface (API) for interaction. With Ollama, you can run a wide range of LLM models, including popular ones like LLaMA 3.2, Gemma, Mistrals, and more.
Integrating Crawl4AI with Ollama unlocks powerful capabilities. By extracting real-time information from online sources, Crawl4AI can feed structured data into LLMs running on Ollama, enriching their responses with up-to-date and highly relevant information. This combination enhances the accuracy and efficiency of AI-powered applications, making it easier to build intelligent systems that provide precise and contextual insights.
In this short post, we’ll extend our previous local setup of Retrieval-Augmented Generation (RAG) by adding web crawling capabilities. This will allow us to extract and incorporate fresh data from online sources, enhancing the accuracy and relevance of our AI-driven responses.
The RAG mechanism can be summarized as follows:
To build a local RAG system, you'll need the following components:
- Sources: Source documents—in this case, it will be website.
- Load: A loader which will load and split the documents into chunks
- Transform: Transform the chunk for embedding.
- Embedding model: The embedding model takes the input as a chunk and outputs an embedding as a vector representation.
- Vector DB: Vector database for storing embedding.
- LLM model: Pre-trained model, which will use the embedding to answer the user query.
To get started, let me summarize the key components that I will be using next.
- LLM server: Ollama local server
- LLM model: LLama 3 8b
- Embedding model: all-MiniLM-L6-v2
- Vector database: SQLiteVSS (sqlite3)
- Framework: LangChain
- Crawl engine: Crawl4AI
- Programming language: Python 3.11.3 with Jupyter notebook.
The setup will be as follows:
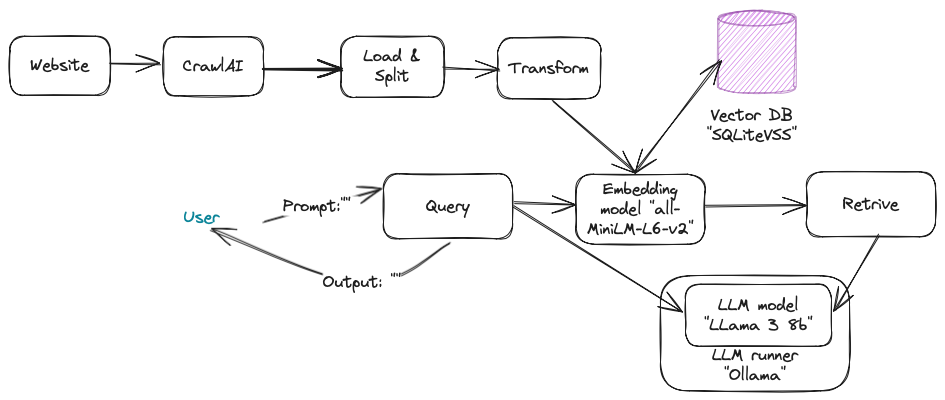
Run your Jupyterlab notebook and start adding Python code.
Step 1. Install necessary libraries.
# Install the package
!pip install -U crawl4ai
# Run post-installation setup
!crawl4ai-setup
# Verify your installation
!crawl4ai-doctor
!pip install --upgrade langchain
!pip install -U langchain-community
!pip install -U langchain-huggingface
!pip install sentence-transformers
!pip install --upgrade --quiet sqlite-vss The above codes will install Crawl4ai, LangChain and Hugging Face packages. Also, we are going to use SQLite-VSS as a vector database.
Step 2. Extract information from the Wikipedia website.
from crawl4ai import AsyncWebCrawler
from crawl4ai.chunking_strategy import RegexChunking
async with AsyncWebCrawler(verbose=True) as crawler:
result = await crawler.arun(url="https://en.wikipedia.org/wiki/Wikipedia:Very_short_featured_articles", bypass_cache=False)
content = result.markdownFor memory consumption, I am extracting information from a very short Wikipedia page.
After running the cell, you should have a similar output in the Jupyter notebook.
[INIT].... → Crawl4AI 0.4.247
[FETCH]... ↓ https://en.wikipedia.org/wiki/Wikipedia:Very_short... | Status: True | Time: 0.05s
[COMPLETE] ● https://en.wikipedia.org/wiki/Wikipedia:Very_short... | Status: True | Total: 0.06sStep 3. Import necessary libraries.
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import SQLiteVSS
from langchain.text_splitter import CharacterTextSplitter
from langchain.schema.document import DocumentStep 4. Split the downloaded text.
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = [Document(page_content=x) for x in text_splitter.split_text(content)]
docs = text_splitter.split_documents(documents)
texts = [doc.page_content for doc in docs]Step 5. Embedded the texts.
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")Step 6. Load the text embeddings in SQLite-VSS in a table.
db = SQLiteVSS.from_texts(
texts = texts,
embedding = embedding_function,
table = "crawling",
db_file = "/tmp/vss.db"
)Step 7. Let's use a similarity/semantic search and print the result.
question = "What is a Featured Articles?"
data = db.similarity_search(question)
# print results
print(data[0].page_content)After running the above statements, you should get a very similar result shown below.
There has often been discussion about whether very short articles can attain Featured article (FA) status.
Some editors are opposed to short articles at Featured article candidates (FAC). Many bring up fair arguments, such as potential overflow of FACs, lack of reviewers, and loss of quality main page TFAs. Other FAC reviewers argue that any article which meets Wikipedia's notability requirements can become featured. So, should a 500-word (or less) article be able to make FA?Step 8. Run the local Ollama server.
ollama run llama3Step 9. Import the langchain LLM package and connect to the local server.
# LLM
from langchain.llms import Ollama
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
llm = Ollama(
model = "llama3",
verbose = True,
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]),Step 10. Use the LangChain prompt to ask a question.
# QA chain
from langchain.chains import RetrievalQA
from langchain import hub
# LangChain Hub is a repository of LangChain prompts shared by the community
QA_CHAIN_PROMPT = hub.pull("rlm/rag-prompt-llama")
qa_chain = RetrievalQA.from_chain_type(
llm,
# we create a retriever to interact with the db using an augmented context
retriever = db.as_retriever(),
chain_type_kwargs = {"prompt": QA_CHAIN_PROMPT},
)Step 11. Print the result.
result = qa_chain({"query": question})This prints the query result. The query result should be something as follows:
A Featured Article (FA) is a designation given to the highest-quality articles on Wikipedia, meeting strict standards for accuracy, neutrality, completeness, and style. There is some debate about whether very short articles can achieve Featured Article status, but there is no strict minimum length requirement.Note that it may take a few minutes to respond, depending on your local computer resources.
In this case, LLM generates a concise answer for the query based on the embeddings. During semantic similarity search, we issue a query to the vector database, which returns a similarity score for the answer.
Published at DZone with permission of Shamim Bhuiyan. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments