How Do You Measure If Your Customer Churn Predictive Model Is Good?
This article talks about the practical aspect of what to measure and how to measure.
Join the DZone community and get the full member experience.
Join For Free
Accuracy is a key measure that management looks at it before giving a green light to take the model to production. This article talks about the practical aspect of what to measure and how to measure. Please refer to this article to learn about the common mistakes made in measuring accuracy.
Two Important Points to Consider When Measuring Accuracy
- The data to use when measuring the accuracy should not have been used in the training. You can split your data into 80% and 20%. Use 80% to train and use the rest — 20% — to predict and compare the predicted value with the actual outcome to define the accuracy
- One outcome eclipsing the other outcome. Say 95% of your transactions are not fraud. If the algorithm marks every transaction is not fraud, its right 95% of the time. So the accuracy is 95% but the 5% its wrong can break the bank. In those scenarios, we need to deal with other metrics such as Sensitivity & Specificity etc. which we will cover in this article in a practical way.
Problem Definition
The goal for this predictive problem is to identify which customers would churn. The dataset has 1000 rows. Use 80% sample (800 rows) for training and the 20% of the Data to measure accuracy. (200 rows). Say we have trained the model with 800 rows and predicting on the 200 rows.
Actual Churn Outcome Marked

To visually explain this problem, let’s say my testing data has 25 customers.
Out of those 25 customers, 15 will not churn (green) and 10 have churned (red). Those are the actual outcomes. Now, let's apply the trained model to predict who will churn.
Predicted Churn Outcome Marked

These are the predicted results. The algorithm made a number of mistakes.
It predicted some correctly and it predicted few incorrectly. For example, it marked some of the customers who will churn as not churn and also marked some of the customers who will not churn as someone who will churn. The ones predicted incorrectly are marked with an X.
Prediction Outcome Stats

To make it easier to follow along I have visually separated predictions within each group so we know what was predicted correctly and what was not.
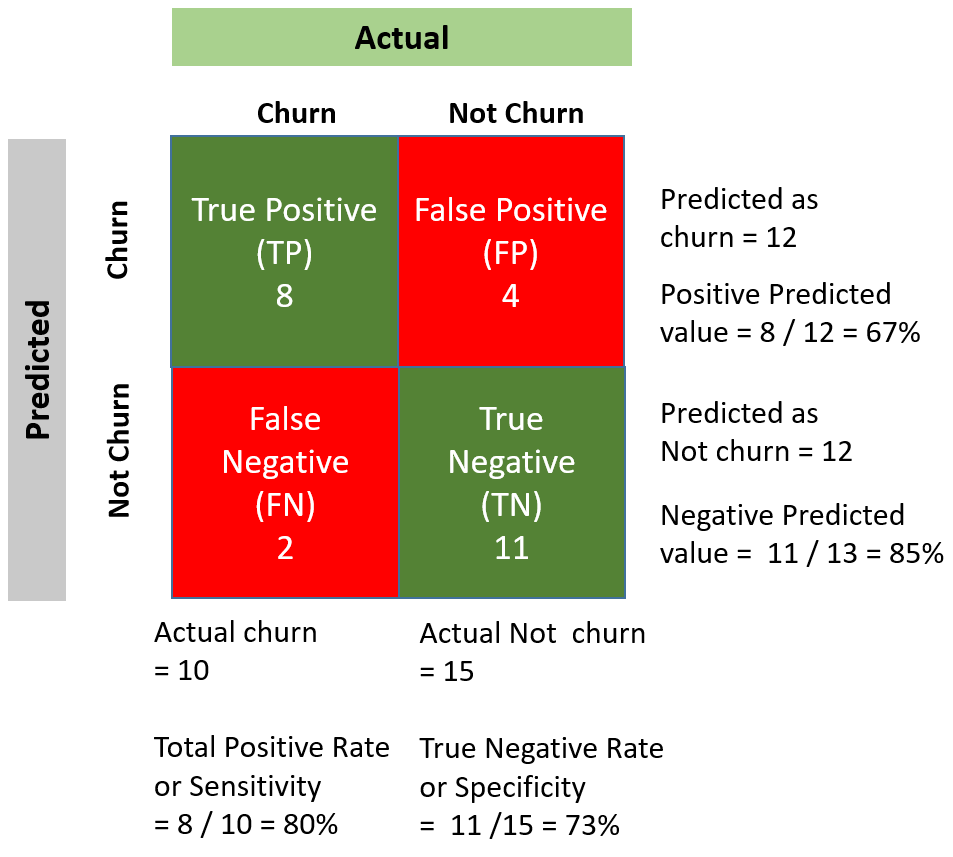
- It predicted 8 customers who will churn correctly. (This is called True Positive)
- It incorrectly predicted 2 customers who will churn as not churn. (This is called False Positive )
- It predicted 11 customers who will not churn correctly (This is called True Negative)
- It incorrectly predicted 4 customers who will not churn as churned. (This is called False Negative)
The way to remember these buzzwords is…False Positive is incorrectly predicted as positive (aka incorrectly predicted as churn) and False Negative is incorrectly predicted as negative (aka incorrectly predicted as will not churn).
Accuracy Measures of Interest
The normal questions that come up are:
- What is the overall accuracy?
- What % of the customers who will actually churn is the model able to tag as will churn?
- What % of the customers who will actually Not churn is the model able to tag as will Not churn?
- What % of customers predicted as churn actually churned?
- What % of customers predicted as will not churn actually Not churn?
1. What Is the Overall Accuracy?
Total Predicted correctly / Total Number = (11 + 8) / 25 = 76%
2. What % of the Customers Who Will Actually Churn Is the Model Able to Tag as 'Will Churn?'
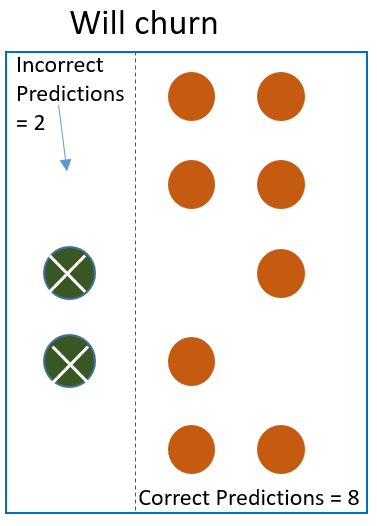
We have 10 churned customers and we correctly predicted 8. So ratio = 8/10 = 80%
This is also called Sensitivity or Positivity rate or Recall. Since this measure does not include what was predicted incorrectly, this measure tends to be biased for imbalanced classes.
A model that is 100% sensitive will identify all churned customers. It’s rare that any model will be 100% sensitive. A model with 85% sensitivity will identify 85% of churned customers but will miss 15% of churned customers. A highly sensitive model can be useful for ruling out a customer predicted as will not churn. The logic is it's highly accurate in predicting who will churn. Which means if it says this customer will not churn, we can potentially rule them out.
3. What % of the Customers Who Will Actually 'Not Churn' Is the Model Able to Tag as 'Will Not Churn?'
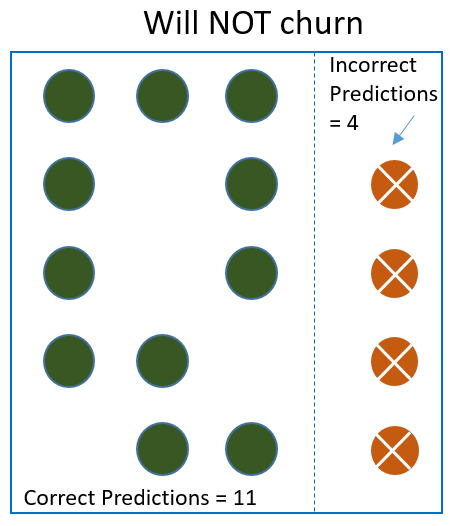
We have 15 Non churned customers and we correctly predicted 11. So ratio = 11/15 = 73.3%
This is also called Specificity or True Negative rate. Since this measure does not include what was predicted incorrectly, this measure tends to be biased for imbalanced classes.
A model that is 100% specificity will identify all Non churned customers. It’s rare that any model will be 100% specificity. A model with 90% specificity will identify 90% of Non churned customers, but will miss 10% of Non churned customers. A highly specificity model can be useful for identifying customer who will churn. The logic is it's highly accurate in predicting who will Not churn. Which means if it says this customer will churn, it's more trustworthy.
4. What % of Customers Predicted to Churn Actually Churned?

We have 12 customers predicted as churned customers (all red including X) and we correctly predicted 8 (red without X). So ratio = 8/12 = 67%
This is means out of 100 customers predicted as will churn, only 67 of them will churn and the rest 33 will not churn.
This is also called Precision or Positive Predicted Value.
5. What % of Customers Predicted to Not Churn Actually Did Not Churn?
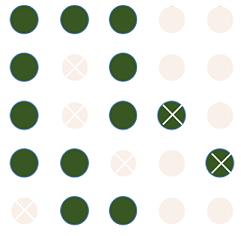
We have 13 customers (green circles including X) predicted as 'Not churned' customers and we correctly predicted 11 (green without X). Ratio = 11/13 = 85 %
This is means out of 100 customers predicted as will Not churn, 85 of them will Not churn and the rest 15 will not churn.
This is also called Negative Predicted Value
Quick Summary of the Measures in Simple Terminology
- The model will catch 80% of the customers who will actually churn.
- The model will catch 73% of the customers who will actually Not churn
- Overall all accuracy is 76%
- Out of the customers it predicted as will churn, 67% of them will actually churn
- Out of the customers it predicted as will Not churn, 73% of them will actually Not churn
Bottom Line
This is fairly a decent model. You are able to engage with 80% of the customers who will churn. You are missing 20% for sure. Out of all the customers who are predicted to churn, you have 27% who are incorrectly predicted as churned. If the goal is to engage and talk to the customers to prevent them from churning, its ok to engage with those who are mistakenly tagged as 'not churned,' as it does not cause any negative problem. It could potentially make them even happier for the extra love they are getting. This is the kind of model that can add value from day one. Note that it's important to distribute this information to the right audience and allow users to take action.
Opinions expressed by DZone contributors are their own.
Comments