How Related Are Your Documents?
Measure document similarity automatically and query them efficiently.
Join the DZone community and get the full member experience.
Join For FreeMany industry pundits claim that 75 to 80 percent of all enterprise data remains in an unstructured format. Various permutations of text-like word processing files, simple text files, and emails make up the most considerable amount of unstructured data in the enterprise. Most of the time it is required to compare these documents or find out the similarity between these documents.

"Have we ever created a legal document like the one we need now?" "Is there an existing article that we can cater to the customer's requirements?" "I think I responded to a similar query like this before; let me try to find that email." These are some of the typical questions that everyone faces, and we start hunting for answers in truckloads of emails and documents.
In this article, we will focus on a machine learning method for two use cases:
Automate a document comparison task and make life easier. You can use the later code directly in a folder where you have stored your documents and compare to detect similarities and differences between them.
Find relevant documents with ease by passing a query text. For example, just query 'Data Science and it's capabilities' to a function, and it would return all the documents that are similar to this query.
How Do We Measure Document Similarity?
The similarity between documents is measured by using various similarity metrics. The Jaccard similarity and cosine similarity are used most often. If you want to know more about this metric, you can view the DZone Refcard: Understanding Data Quality.
These metrics have already been packaged and are ready to use in Python, like gensim and spaCy. I tried with both, however, the similarity measures from gensim seem better to me.
Use Case 1: Automate the Document Comparison Task
The following code snippet reads all the text files from a folder and stores them as separate elements in a list. We have stored six articles in the folder. Three are related to data science (topic documents 1, 2, and 6), two are associated with Databases (topic documents 4 and 5), and one article is related to politics (topic_document_3.txt). You can find the below code along with the data on my GitHub repo.
import glob
import os
file_list = glob.glob(os.path.join(os.getcwd(), "zone/text_mining/document_similarity", "*.txt"))
raw_documents = []
for file_path in file_list:
with open(file_path, encoding="utf8") as f_input:
raw_documents.append(f_input.read())
print("Number of documents:",len(raw_documents))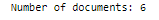
Next, we tokenize the words for each document. Now, we need to create tokens out of the text. Tokens can be loosely defined as words, but technically, they are a sequence of characters that are grouped as a semantic unit. Each document is tokenized in words using word_tokenize. For this task, we use the NLTK (Natual Language Toolkit) library. The NLTK package is a leading library for building applications around Natural Language data. It provides various text processing capabilities, such as easy-to-use text preprocessors and text-based model techniques, like document classification, named entity recognition, and much more.
from nltk.tokenize import word_tokenize
gen_docs = [[w.lower() for w in word_tokenize(text)]
for text in raw_documents]
print(gen_docs)
Then, import the genism package. The genism package provides good methods for topic modeling and measuring document similarity. It is easy to use and has implemented word2vec and sentence2vec to produce word embeddings. These are the most popular techniques to learn word embeddings using neural networks. While NLTK is great at tokenization, text parsing, and POS tagging, the benefits of using open source languages and packages are using the things that are best for a task.
We now use the genism package to convert the tokens to a dictionary. The Dictionary() function traverses each document and assigns a unique ID to each unique token along with their counts.
import genism
dictionary = gensim.corpora.Dictionary(gen_docs)Next, the dictionary is converted into a bag-of-words model using the doc2bow method. The result is a list of vectors equal to the number of documents. Each document vector has a series of tuples with a token ID and a token frequency pair.
corpus = [dictionary.doc2bow(gen_doc) for gen_doc in gen_docs]
print(corpus)
Then, we create a TF-IDF model. TF-IDF stands for 'Term Frequency-Inverse Document Frequency.' TF-IDF encoding represents words as their relative importance to the whole document in a collection of documents, namely corpus.
tf_idf = gensim.models.TfidfModel(corpus)
print(tf_idf)Genism has made available various state-of-the-art, pre-trained models that help extract word vectors. We use the fasttext-wiki-news-subwords-300 model, which is trained on 1 million word vectors trained on Wikipedia 2017. These models are huge and might take some time depending on the bandwidth of your internet connection and can be installed using the gensim download API. When API.load is used, it first checks whether the model is available in the system. If not, it downloads it from the internet.
import gensim.downloader as api
fasttext_model300 = api.load('fasttext-wiki-news-subwords-300')To compute cosine similarity, first we need to compute the similarity matrix.
similarity_matrix = fasttext_model300.similarity_matrix(dictionary, tfidf=None, threshold=0.0, exponent=2.0, nonzero_limit=100)Next, we pass the document corpus and similarity_matrix to the softcossim function that calculates the similarity between the two documents.
from gensim.matutils import softcossim
softcossim(corpus[0], corpus[1],similarity_matrix)
The first and second documents are related to the 'Data Science' article, and it found around 95 percent similarity between these two documents.
from gensim.matutils import softcossim
softcossim(corpus[0], corpus[3],similarity_matrix)
The third document in our folder is a political document, and it has much less similarity with the Data Science piece. So, it yielded a similarity of around 42 percent. This similarity is due to the use of standard English words and can be eliminated before the text mining exercise to compute better similarity and dissimilarity measures.
For measuring the effectiveness of a document-similarity algorithm implemented in gensim, I compared the first document (topic_document_1.txt) to the last document (topic_document_6.txt). It accurately computed them as 100 percent similar.
from gensim.matutils import softcossim
softcossim(corpus[0], corpus[5],similarity_matrix)
Use Case 2: Find Out the Relevant Documents With Ease by Passing a Query Text
Now that we have developed this model, let's provide a search capability as well. Let's say we want to find articles that have 'Data Science' in it. We can do this task in a couple of steps, as shown below.
The Similarity method builds an index for the set of documents. Once the index is built, the object can be used, and we can perform queries on it that would compute the similarity between the query text and documents.
similar_docs = gensim.similarities.Similarity('zone/text_mining/document_similarity',tf_idf[corpus],
num_features=len(dictionary))
similar_docsWe use 'Data Science' as the query to be performed on the folder of documents. We tokenize the query text and store the corresponding TFIDF metrics.
query_doc = [w.lower() for w in word_tokenize("Data Science")]
print(query_doc)
query_doc_bow = dictionary.doc2bow(query_doc)
print(query_doc_bow)
query_doc_tf_idf = tf_idf[query_doc_bow]
print(query_doc_tf_idf)
Next, we pass this query's documents to TFIDF to the object similar_docs to tell us what documents are similar to the query.
similar_docs[query_doc_tf_idf]
We can see that the text 'Data Science' is somewhat related to documents 1, 2, and 6, which are Data Science-related articles. The third piece (topic_document_3.txt) is a political article, and it is 0 percent related to the words 'Data Science.' The fourth (topic_document_4.txt) and fifth (topic_document_5.txt) articles are related to databases, so they have some relationship, but a negligible relationship.
Now, that you know the benefits of using document similarities, you can try it out for yourself and use it at your work.
You can find the code along with the data on my GitHub repo.
Opinions expressed by DZone contributors are their own.
Comments