How to Tame Java GC Pauses? Surviving 16GiB Heap and Greater
Learn how to survive 16GiB and greater heaps, and control Java GC pauses.
Join the DZone community and get the full member experience.
Join For FreeMemory is cheap and abundant on modern servers. Unfortunately there is a serious obstacle for using these memory resources to their full in Java programs. Garbage collector pauses are a serious treat for a JVM with a large heap size. There are very few good sources of information about practical tuning of Java GC and unfortunately they seem to be relevant for 512MiB - 2GiB heaps size. Recently I have spent a good amount of time investigating performance of various JVMs with 32GiB heap size. In this article I would like to provide practical guidelines for tuning HotSpot JVM for large heap sizes.
You may also want to look at two articles explaining particular aspects of HotSpot collectors in more details “Understanding GC pauses in JVM, HotSpot's minor GC” and “Understanding GC pauses in JVM, HotSpot's CMS collector”.
Target Application Domain
GC tuning is very application specific. This article is about tuning GC for java applications using large heaps (10GiB and greater) and having strict response time SLA (few milliseconds). My practical experience is mostly with data grid type of software, but these tips should also apply to other applications have following characteristics:
- Heap is used to store data structures in memory.
- Heap size 10GiB and more.
- Request execution time is small (up to dozens of milliseconds).
- Transactions are short (up to hundreds of milliseconds). Transaction may include several requests.
- Data in memory is modified slowly (e.i. we do not modify whole 10GiB in heap within one seconds, though updating of 10MiB data in heap per second is ok).
I'm working with java GC implementations for a long time. Advises in this article are from my practical experience. GC economics for 2GiB heap and 10GiB heap are totally different, keep it in mind while reading.
Economy of Garbage Collection
Garbage collection algorithms can be either compacting or non-compacting. Compacting algorithms are relocating objects in heap to reclaim unused memory, while non-compacting are managing fragmented heap space. For both kinds of algorithms effort for reclamation of free space is proportional to ratio of garbage vs. live objects (amount of garbage / amount of live objects). In other words, more memory we can spare for garbage (waste) more effective collector algorithm will be (in terms of work effort, not necessary GC pauses).
Normally we cannot afford to have more than half of memory to be wasted as garbage, nor do we want to have more than half of CPU horse power to be busy with memory cleaning. In general CPU efficiency of garbage collector is reverse proportion with memory efficiency.
Solution to this Gordian knot lies in “weak generational hypothesis”. This hypothesis postulates that:
- Most objects become garbage short after creation (die young).
- Number of references from “old” to “young” objects is small.
That means, if we would use different collection algorithms for young and old objects we can achieve better efficiency compared to single algorithm approach. Using different algorithms requires splitting of heap into two spaces. Space for young objects will have lower density of live, so garbage will be collected efficiently (to compensate high death rate). Space for old objects will have higher density and in most cases large size, this way we can waste less memory for garbage. Cost of memory reclamation in old space will be higher but it will be compensated with lower death rate. In genarationally organized heap new object always allocated in young space, then promoted to older space if they survive (one or several young space collection). Most popular aproach is to use 3 generational spaces:
- space for allocation (eden) - youngest objects,
- survival space - objects survived one collection (survival space is colected together with allocation space),
- tunured (old) space - objects survived several young collections.
Object Demography
Below is a chart showing an example of demography we could expect from our class of application.
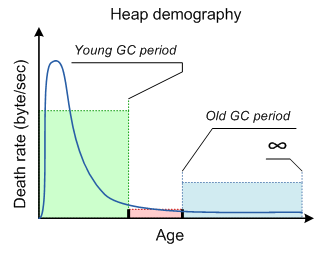
On this chart we have several critical points. Most important is period of young space collection. Object live-time distribution have a peak, and it is important to ensure that all this short lived objects are collected in young space. We can control period of young GC, so it is important aspect of tuning. Another key point is a period of old GC, period of old GC depends on how many memory we can waste for garbage in old space (e.i. we are not going to tune old GC period to improve demography chart). Objects with lifetime between these two points are mid-aged garbage. Criteria of good demography is to keep Ryoung >> Rold >> Rmid_aged (there R is death rate in corresponding lifetime diapason).
Shape of demography can be improved by tuning young collections (size of young space, size of survival spaces, tenuring threshold). Period of old space collection is dictated to total heap size, and long lived objects death ratio, so it can be considered a constant concerning demography shape.
Fortunately, this is quite natural distribution for server type application which does not execute long transaction this is quite normal distribution. But if length of transactions will exceeds period of young collection they will start contributing to mid-age which is a bad for GC performance. Another treat of GC efficiency is bad caching strategy, producing large amount of mid-aged garbage.
Confirming Demography of the Application
Before starting tuning of GC we must ensure that our application demography is in good shape. Before doing any GC measurement you should come up with some test scenario which ensure constant load to application (performance tests are usually good choice). Instruction below is for HotSpot JVM. If you use other JVM you still can do these measurements using HotSpot (HotSpot only JVM which displays exact demography of objects in young space).
You should configure GC for “demographics research”. For "demographic research" we should make survival space same size as Eden (-XX:SurvivorRatio=1), increase new space to account grow of survivor spaces is also a good idea (-XX:MaxNewSize=<n> -XX:NewSize=<n>) you should triple your young space size. Finally we need to enable diagnostic options (-XX:+PrintGCDetails -XX:+PrintTenuringDistribution -XX:+PrintGCTimestamps).
In research configuration logs of your application will be filled with JVM GC diagnostic frames like this:
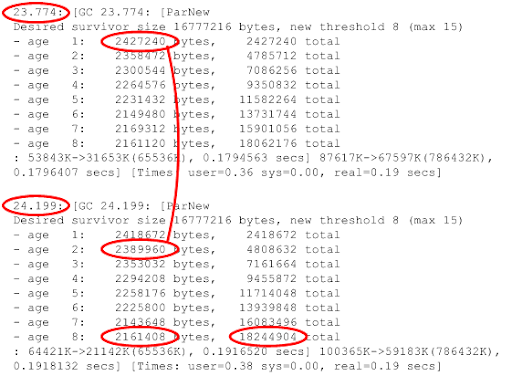
Skip some initial logging (while your application is loading data and stabilizes). From logs you can calculate several important GC metrics. Second column show cumulative size of each generation of objects (generations are divided by young collection event). You should see fairly same size of different generations. If first one or two generations are significantly large than older generations – your young collections are two frequent, you have to increase Eden size to increase period of collection. If size of generation is not stabilizing, this indicates problem with your application demography.
Young collection period. You have simple to calculate time between timestamps.
Total allocation rate. Size of Eden + size of survivor space – size of all ages (bottom value in rightmost column) divided by young collection period.
Short lived objects allocation rate. Eden size (young space size – 2 * survivor space size) – size of age 1 reported by collector divided by collection period.
Long lived object allocation rate. Size oldest age divided by collection period.
Mid aged objects allocation rate. Total allocation rate – short lived object allocation rate – long lived object allocation rate.
Having these numbers you can verify health of your demography.
Scalability of Different GC Algorithms
My experience tells that HotSpot’s CMS is most robust GC for 10-30Gb heaps (30Gb is my practical limit for single JVM so far). Unlike its main competitors like HotSpot’s G1 and JRockit, HotSpot’s CMP is not compacting. CMS does not relocate objects in memory. Theoretically it makes it prone for fragmentation, but in my experience compacting algorithms are having even more problems with fragmentation in practice while CMS is smart enough to manage fragmented memory efficiently (e.g. it uses different free lists for different object sizes). Once again we are speaking about >10GiB heap sizes, while I could agree that for small heap size fragmentation can be an issue, for big heaps it never was a problem for me.
Another argument against compacting collector is that coping object is not just CPU cycles waste to move data and update of reference sites; coping can only be done during stop-the-world pause. For compacting collector sum of pauses is proportional to amount of reclaimed memory (which is a bad math). In practice we have to waste more memory for garbage in old space to keep efficiency of compacting collector reasonable.
Azul’s Zing JVM can do coping without stopping application threads. But it is using hardware read barrier and cannot be run or regular OS (though it can be run as virtual appliance on top of commodity hardware).
Unlike compacting collectors CMS can effectively work even if heap density is very high (~80%) while having pauses defined mostly by geometry of heap (on 10Gb and more young and remark pause time are dominated by time spent to scan card table).
CMS Collector Tuning for Large Heaps
Pauses in CMS
CMS is doing most of its work in parallel with application, though few types of pauses cannot be avoided. If CMS is enabled JVM will experience following types of pauses:
- Young space collection – for large heaps this pause is dominated to time to scan card table, which is proportional to size of old space.
- Initial mark pause – if initial mark is done right after young collection, its time doesn’t depend on heap size at all.
- Remark – time of this pause is also dominated by time to scan card table.
As you can there is nothing much we can do, card table scan time will grow as we increasing heap size. Below is check list of CMS collector tuning:
- Check that demography of your application matches is good for generational GC.
- Choose young to old object promotion strategy.
- Choose size of young space.
- Configure CMS for short pauses.
- Choose old space size.
- Configure parallel GC options.
Check Demography
Check your demography, if it doesn’t fit “generational hypothesis” you may consider fixing you application. Typical problem is mixing in single JVM processing of online transaction (requiring low response time) and batch processing producing mid-age garbage (and for batch operations GC pauses are not that critical). If this is your case you should divide your application into separate JVM for online transactions and batches.
Caching of Object and Garbage Collection
One of potential treat for GC friendly demography is bad caching strategy. Application level caching can be unanticipated source of middle aged garbage. Following changes in caching strategy can solve GC problems due to application caching:
- add expiry to cache, and keep young GC periods few times longer than cache expiry (or delay tenuring of objects),
- increase young GC periods,
- use weak references for cache (though using of weak reference may cause other problem, you should test such solution carefully),
- reduce cache (it may be lesser evil than GC problems),
- increase cache size (this will reduce object eviction from cache, so death rate and GC problems, of cause you will have to pay with additional memory for this).
Object Promotion Strategy
JVM allocates all objects in young space, later surviving objects either relocated to old space or relocated in young space for each young collection. Coping of objects inside young space increases time of young collection pause. For our type of application two practical choices are
- copy object to old space during first collection,
- copy object to old space during second collection.
First option will leak few short lived objects to old space, but if period of young collection is much longer than average short lived object live time number of such object will be very small. Using second option (wait until second collection) may make sense if young collections are very frequent or number of long lived object is very small (so we do not spend much time to copy them inside young space).
Balance Size of Young Space
For large heaps main contributors to young collection pauses are time to scan card space (Tcard_scan) and time to copy live objects (Tcopy). Tcard_scan is fixed for your heap size, but Tcopy will be proportional to size of young space. Making young space large will make pause less frequent (which is good), but may increase pause length by increasing T. You should find balance for your application. Unfortunately Tcard_scan cannot be reduced; it is your lower bound for pause time. If you increasing young space you should also increase total heap size of JVM, otherwise size of your old space will be reduced. Remember you are not using young space for your data, but for garbage only. You should always size old space to be large enough to hold all your application data plus some amount of floating garbage.
Configure CMS for Short Pauses
Use advises from previous article to configure CMS for low pauses.
- Set –XX:CMSWaitDuration=<t> to be at least twice longer than max interval between young collection pauses (usually this interval increases if application is not loaded, you have to keep it in mind)
- Set –XX:+CMSScavengeBeforeRemark to avoid Eden scanning during collection (on large heaps using this flag makes pauses more stable at price of little increase in pause time, though for small heap this may not be a best option) .
Providing Head Room for CMS to Work
You should also reserve more memory for JVM than size of live objects expected to be in heap (jmap is excellent tools to measure space required by your application objects). As I said CMS can handle dense heaps pretty well, in my experience 20% is enough for CMS headroom. But remember what you should calculate 20% from old space size (Xmx – XX:MaxNewSize). Actually required headroom depends on death rate of old objects in your application and if it is high you may need more headroom for CMS to work.
Utilize all your cores
HotSpot has effective parallel implementation for most phases of GC. Usually specifying –server flag is enough for JVM to choose good defaults. In certain cases you may want to reduce number of parallel threads for GC (by default it is equals to number of cores), e.g. if it is affecting other application. But usually –server is good enough.
Conclusion
Using advises above and HotSpot’s CMS, I was able to keep GC pause on 32Gb Oracle Coherence storage node below 150ms on 8 core server. Though this may be good enough, modern garbage collectors have a lot room for improvements. My experiments with JRockit have shown what it can keep better young collection pauses than HotSpot, but compacting algorithm for old space makes it unstable on 32Gb JVM (pauses during old collections are just unreasonable). Unfortunately JRockit does not have option to use non compacting collector. HotSpot’s G1 also has potential but it is prone to same problem as JRockit – sporadically pause time becomes unreasonably long (few seconds). Also both JRockit (congen) and HotSpot’s G1 are requiring much more head room in old space (read memory wasted). So at the moment CMS is only algorithm providing stable performance on 32Gb heap.
See also
Opinions expressed by DZone contributors are their own.
Comments