How To Build Computer Vision-Driven Car Damage Detection
Let's explore the principles behind designing a two-model computer vision solution and assess the capabilities of the Mask R-CNN and U-Net AI algorithms.
Join the DZone community and get the full member experience.
Join For FreeComputer vision, as an integral component of artificial intelligence, is gaining increasing significance within the insurance sector. Its implementation yields manifold advantages, such as process automation, cost reduction, heightened precision, and an enhanced customer experience.
Computer vision technology brings many opportunities, including the replacement of manual inspection to a certain extent. That’s why the Intelliarts team found it promising to start working on an automated car damage assessment project.
In this exploration, we delve into the Intelliarts team's experience with solving car damage detection challenges using computer vision. We will examine specific algorithms that can be employed, elucidate the model training and evaluation process, and evaluate the potential benefits of popular algorithms in the realm of computer vision projects.
What Algorithms Can Solve Car Damage Detection Task
For this purpose, engineers utilize the image segmentation algorithm. Its work is to attribute one or another class to a particular pixel in the image based on certain visual characteristics, such as color, texture, intensity, or shape. In the case of vehicle inspection, the class is either with damage or without damage. The goal of image segmentation is to simplify or change the representation of an image into a more meaningful form, separate objects from the background, and make them easy to analyze.
The two major approaches to image segmentation are the following:
Instance Segmentation
With this computer vision technique, each individual object is identified and labeled with a unique identifier. The first step of instance segmentation is object detection. In this phase, a computer vision algorithm attempts to detect all objects in the image and provide a bounding box, i.e., rectangular or square-shaped figure surrounding an object, to each of them. During the classification done over areas inside bounding boxes, the algorithm calculates the confidence or the likelihood of the particular object of interest with a specific class, e.g., car, tree, human, etc., being inside the bounding box.
In the second step of the technique, the algorithm performs segmentation in each of the bounding boxes and labels each pixel, indicating whether it belongs to an object or not.
Another requirement of instance segmentation is the usage of pixel-wise masks. These are binary images that are used to identify the location of objects or regions of interest within an image. Each pixel in the mask is assigned a value of either 0 or 1, indicating whether that pixel belongs to the object or region of interest. Pixel-wise masks can be generated manually by annotating images.
The way this algorithm works ensures that multiple instances of the same object are differentiated from one another, even if they overlap or are partially obscured by other objects in the image.
Semantic Segmentation
The semantic segmentation technique involves dividing an image into multiple segments, each of which corresponds to a particular object or region of interest within the image, and classifying them separately. Unlike traditional image segmentation methods that simply partition an image into arbitrary regions based on pixel similarity, semantic segmentation aims to associate each segment with a meaningful semantic label, such as a person, car, building, tree, etc.
Semantic segmentation treats multiple objects belonging to the same class as a single entity. It can indicate boundaries of, for one, all people, all cars, or all buildings in the image, if necessary. It’s important to note that semantic segmentation allows for detecting damages only without distinguishing them. In construct, instance segmentation can distinguish multiple distinct damages from each other.
Once trained, the semantic segmentation model can be used to segment new images by propagating them through the network and generating a pixel-level segmentation mask. The latter works similarly to pixel-wise masks in instance segmentation yet assigns a label to each pixel in an image instead of generating multiple masks, one for each instance of an object.
The actual comparison of real-life instances and semantic segmentation algorithms with obtained insights is provided in the below sections.

Machine Learning Metrics for the Evaluation of a Trained Model’s Performance
Machine learning metrics are quantitative measures of how well a model is solving a given task. They help in assessing the model’s performance and provide insights into the model's strengths and weaknesses.
Values of machine learning metrics are calculated based on outcomes that the model shows after its testing on a previously unused dataset. This way, engineers can assess the potential performance of the model on real-life data. Obtained results guide further decision-making, as engineers may need to rework the model multiple times before its performance is proved satisfactory.
Here is the list of main image segmentation metrics to consider using while testing a model for solving damage detection tasks:
1. MIoU (Mean Intersection Over Union)
This metric measures the average overlap between the predicted and ground truth segmentation masks for each class in the dataset. MloU is calculated by computing the IoU for each class and then taking the mean across all classes. IoU = Intersection between predicted and ground truth masks for a class/union between predicted and ground truth masks for a class.
2. Pixel Accuracy
This metric measures the percentage of pixels in an image that are correctly classified by the model. Pixel accuracy = The number of correctly classified pixels / the total number of pixels in the image.
3. Dice Coefficient
In image segmentation, the dice coefficient measures the overlap between the pixels of the predicted and true segmentation masks on a scale of 0 to 1, where 0 means no overlap and 1 indicates the perfect match. Dice coefficient = 2 * the number of pixels that are correctly classified by both masks / the total number of pixels in both masks
In our research on the performance of instance segmentation and semantic segmentation models detailed below, the Intelliarts team used MloU and Dice Coefficient metrics for measuring the results of testing.
Examples of Real-Life AI Architectures
Selecting the right AI architecture is a crucial step in any ML project. A wisely chosen solution can benefit the outcomes by offering better accuracy of the segmentation process, higher speed of processing, and high efficiency of resource usage. Besides, it may happen that some architectures are better suited for real-time or near-real-time applications, while others may be more suitable for batch processing of large datasets, which also should be carefully considered.
There are some image segmentation architectures that have been extensively tested and are quite popular. Among such are Mask R-CNN and U-net, which were exactly the algorithms used by the Intelliarts team to test instance segmentation and semantic segmentation techniques for solving car damage detection tasks. They allow engineers to utilize fine-tuning techniques over ready-made weights, i.e., models that are pre-trained on a large dataset. This way, training a model from the ground up, which is a resource-extensive task, is unnecessary.
Let’s have an insight into what these algorithms are:
Mask R-CNN
Mask R-CNN (Region-based Convolutional Neural Network with masks) is a deep learning architecture for object detection and instance segmentation. It’s built upon the Faster R-CNN object detection model and has a segmentation part, i.e., a subset of layers operating on the input data.
Mask R-CNN works in two stages. In the first stage, it generates region proposals using a Region Proposal Network (RPN), which suggests regions of the image that are likely to contain objects. In the second stage, it performs object detection and segmentation by simultaneously predicting class labels, bounding boxes, and masks for each proposal.
U-Net
U-Net is a convolutional neural network architecture designed for image segmentation tasks. It is incredibly popular for solving medical image segmentation tasks such as brain tumor segmentation, cell segmentation, and lung segmentation. It has also been adapted for other image segmentation applications, such as road segmentation in autonomous driving.
The U-Net architecture has a distinctive "U" shape, which is formed by the downsampling and upsampling operations. The network has a contracting path, which captures context and downsamples the input image, and an expansive path, which enables precise localization and upsamples the feature maps. In essence, the network can retrieve detailed information about the objects being segmented while also capturing the context and global structure of the image.
Instance Segmentation (Mask R-CNN) vs. Semantic Segmentation (U-Net) Based on Real-Life Observation
In our recent research, the Intelliarts team tested two popular neural network architectures used for image segmentation tasks — Mask R-CNN and U-net. Both computer vision algorithms were trained and then tested using the same datasets. We used precleaned and prepacked data from the publicly available Coco car damage detection and the Segme image datasets.
Despite the fact that Mask R-CNN has a more complex architecture and processes the region proposals rather than the entire image, testing revealed that U-net, as a semantic segmentation-based algorithm, performs better.
U-net showed optimal outcomes in the first part of the test when the AI algorithms were used for identifying car damages and evaluating their magnitude. Besides, in the second part, when Intelliarts engineers made the computer vision models identify damaged car parts and recognize them, Mask R-CNN performed better as well. It brought our team to the conclusion that the semantic segmentation model, particularly the tested U-net, is currently a better choice when it comes to a vehicle damage inspection.
You may want to try an online demo that presents an interactive playground for the trained AI model. The demo shows the capabilities of a computer vision-enabled model to detect car damage based on an input image or video frame.
How To Train an AI Model
Deep neural networks are successfully utilized to solve computer vision and other tasks. Many state-of-the-art solutions built on this technology are successfully used in insurance and other niches. Training of a deep learning ML model encompasses the following steps:
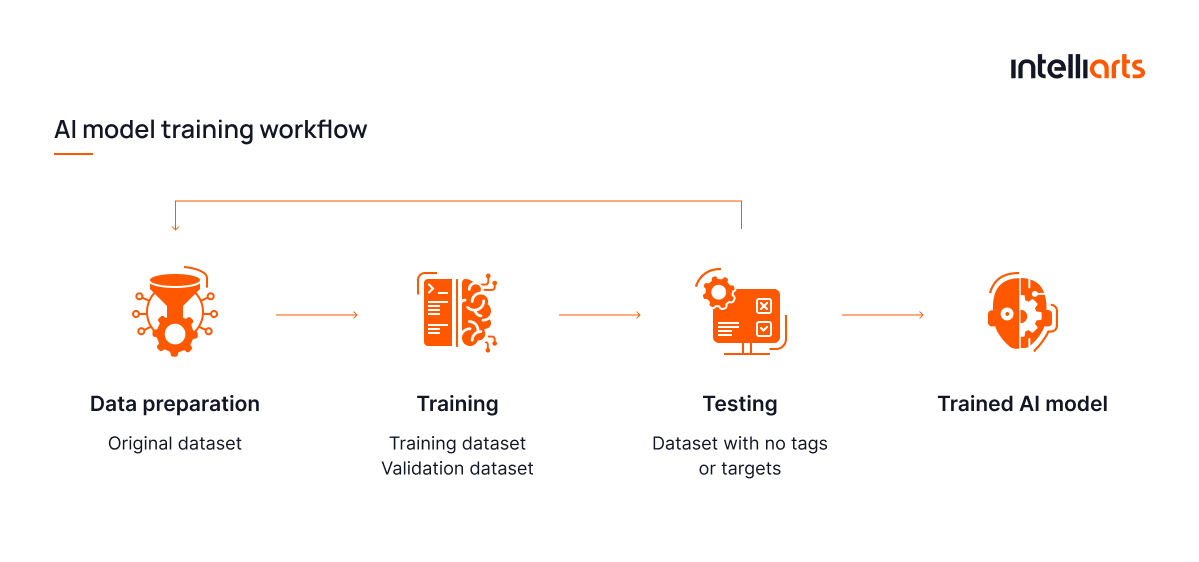
Data Preparation
AI algorithms require considerable amounts of digital data contained in photos and videos to train on. There is a strong correlation between the volume and quality of data and the training outcomes. There is even a concept known as garbage in, garbage out (GIGO), which means that nonsense input data produces nonsense output. So, it’s recommended to find or prepare extensive datasets. In the case of vehicle assessment, there is a need for high-quality samples of damaged vehicles with varying deteriorations from diverse angles, with different lighting, etc.
Data annotation, i.e., categorization and labeling of data for AI applications, is used to make the model understand what digital information in visual materials exactly is and why it is important. For training the AI model for vehicle assessment, engineers need datasets, the images of which were annotated in the following two ways:
- Damage detection: When a diverse set of different damage types is collected, it’s necessary to label and tag objects of interest with relevant metadata using a polygon or a brush. Adding bounding boxes is not required as the model generates them itself. Not to mention that unnecessary bounding boxes may create overlaps and confuse the model being trained.
- Car part detection: Such data annotation is a necessary parallel stage to damage detection. Tagging will help the model recognize particular vehicle parts that were exposed to damage and even calculate their area in preferred units of measurement.
Image labeling is nearly one of the most time and resource-extensive aspects of training an AI model for computer vision applications. Selecting objects on a pixel-by-pixel basis and assigning correct labels that would describe objects and their various attributes or features is time-extensive work. The method is manual labeling, when humans annotate images by hand. Yet, the assistance of machine learning algorithms may somewhat automate and simplify the task.
In our case, we used images that were correctly labeled already from the open-source datasets mentioned above. It’s considered the usage of precleaned and prepackaged data. Other methods of data collection include custom data crowdsourcing, building a private collection, and collecting data automatically through web scraping and web crawling.
There are some data collection best practices to keep in mind. They include determining the problem and the goal of the ML project, establishing data pipelines, establishing storage mechanisms, evaluating the collected data, and collecting concise data aligned with the project’s goals.
Training
Once data collection and annotation are complete, the prepared set of training data is input into the computer vision model. At this stage, it’s crucial to identify errors that the model makes to perform needed adjustments later in order to avoid incorrect bias/variance trade-off balance resulting in overfitting and underfitting problems.
The underfitting problem occurs when a model cannot capture the relationship between the input and output variables accurately. It can be solved by simplifying the model.
The overfitting problem is a scenario when the model is so familiar with the training data that the algorithm becomes restricted and biased. This way, it won’t function when there is any considerable discrepancy in the data. This problem can be solved by complicating the model, expanding the training dataset, or using data augmentation.
After training on the initial dataset, the model moves to the validation phase. In this phase, the AI algorithm works with the validation dataset, which enables engineers to prove their assumptions about the performance of the model. Any shortcomings, unconsiderable variables, and other errors should be revealed in this stage.
Testing
After the training and validation are finished successfully, the computer vision model should be tested for the last time. Normally, the final or holdout set is composed of data that the model hasn’t worked with yet. The data is labeled so engineers can calculate the model’s accuracy. The model is launched on such a dataset only once, and the outcomes are regarded as a potential accuracy that the model will be showing on real-world data. It’s important to find out whether the trained model is capable of making accurate results with acceptable consistency.
Usually, the entire training process is repeated from step one several times, as developers may need to prepare another dataset or modify the model. After multiple tries, the model that shows optimal results is chosen and is considered ready to go live.
The Two-Model AI Solution by Intelliarts
Intelliarts engineers built a software solution composed of two AI models, one of which is used for car damage detection and the other one for car part detection. So, when a user inputs a damaged car’s image in the resulting solution, it indicates the damage and identifies the affected car part separately. This way, outcomes of image processing are identified damages and specified car parts. If they intersect, the solution output results, for example, as “left door — dent.” The outcomes are then compared against similar cases in a prepared image database with repair cost estimations.

The Value of the AI Solution for Car Damage Detection
The finished software solution is capable of recognizing particular car parts, detecting and categorizing multiple types of damage, such as metal or glass damage and dislocation or replacement of car parts, evaluating the severity of the damage, and indicating the estimated repair costs. The functionality of a trained AI model should be enough to solve most of the simple car damage insurance claims with little human supervision.
Needless to say, choosing a particular algorithm or a combination of algorithms, training AI models, and then building a finished software solution should be tightly linked to performing a set of specialized tasks.
For product owners, the end goal of computer vision projects is to apply technology in the insurance industry and get business benefits that include the following:
- Cost optimization: Automated detection can be done at a much lower cost compared with manual inspection, resulting in significant savings for insurance companies.
- Reduction of labor-intensive tasks: Automating the lion’s share of car inspection cases can reduce the workload for insurance company staff and allow them to focus on other critical tasks.
- Improved accuracy: Automated systems can analyze images of the car with greater precision, identifying even small damages that may have been overlooked by human inspectors.
- Faster claim processing: Automated car damage detection can speed up the claim-processing time, enabling insurance companies to settle claims faster. This may result in improved customer satisfaction and retention rates.
Final Thoughts
Conducting vehicle inspections is a labor-intensive aspect of the insurance industry. To streamline claim processing, particularly in cases involving car damage assessment, companies can leverage computer vision methodologies. Image segmentation algorithms play a pivotal role in executing such tasks. However, the crucial step involves judiciously selecting an optimal neural network architecture, such as Mask R-CNN, U-net, or others, for model development. This entails thorough training using data annotation techniques and subsequent performance evaluation.
Published at DZone with permission of Oleksandr Stefanovskyi. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments