How to Get Code Ready for Microservices
Are you thinking about adapting a microservices architecture? Here are three steps to prepare your code base.
Join the DZone community and get the full member experience.
Join For FreeAre you thinking about whether to adapt microservices architecture? If you choose to adapt it, do you know how? I strongly recommend refactoring the code base first to make it ready for microservices. Even if you decide not to adapt microservices (for now), it’s good to go through this code evolution anyway. It has many advantages and just a few disadvantages. Let’s see it.
First of all: we use Java 11 and Spring Framework, which is considered an industry standard. Using Spring or, preferably, Spring Boot is highly recommended when you are even considering adapting microservices.
Component/Model Separation
The first step is separating the whole code base into Components and the Domain Model. Components contain most of the business logic, and the Domain Model contains data, state, and domain model logic. It would help if you separated them on a building level — components depend on Models, but not vice versa.
What are Components and Models, and what are their properties?
Component
- Is a Spring Bean — we can use injections, AOP, and other Spring stuff.
- Is a singleton — only one instance in Spring Context.
- Is stateless — doesn’t hold any state/any value.
- Is configurable — an exception in statelessness is a configuration possibility that can be injected by Spring or optionally changed in runtime.
- Should use good terminology — we use Spring, so we use Spring terminology: Controller, Service, Repository as suffixes (see below).
Model
- Is not a Spring Bean — spring injection is not possible.
- Is a POJO class — with data fields and related domain model logic.
- Is Immutable — all fields are final, collections unmodifiable, the constructor for creation.
- Can be Cloned — when you need to modify the object. Use .withXXX methods.
- Has valid creation — it shouldn’t be created in an invalid state. All conditions should be checked when creating in the constructor (NotNulls etc.).
- Contains domain model logic only — logically related to model data only, no external state-related logic. Usually, it’s formatting, parsing, validating, simple calculation, etc.
Domain Model Logic Limitation
Avoiding the external state is probably the most typical limitation of the domain model’s logic. For now, you can see the very last picture and see that the model doesn’t have any dependency on any other artifact. So, the logic there cannot call any other services and, of course, cannot store anything (or itself) in a database. It is also good not to deliver the external state indirectly (e.g., by passing parameter values for domain model logic into the model). Each parameter delivered there increases memory consumption, and those models can exist in huge numbers. In addition, the parameter values and the domain data are somewhat mixed.
Reasons for Using Component/Model Separation
- Simple pattern — easy to define, easy to understand, easy to maintain.
- Can be Thread-safe — together with other methods like Concurrent Collection or Locks.
- Multi-tenant environment — allow the use of the same instance for multiple tenant requests.
- Save some memory — with fewer and shorter-lived instances in the memory.
- Immutable classes — are better for Garbage Collector.
- Increase error-proofness — thanks to statelessness and immutability.
- Standardized terminology — allows faster understanding of the code.
Controller/Service/Repository Layers
The second step is separating Components into layers of Controller, Service, and Repository. We should also separate them on a building level in this manner: Controller -> Service -> Repository.

The internal decoupling of the code into layers is very useful for code evolution. We separate them into three layers:
- Controller — This contains all front-end communication like REST API. It allows you to replace the controller layer in case you want to use another technology (e.g., GraphQL) or batch processing while the business logic in Services stays as is.
- Service — This contains all business logic. Unless you change the input/output contract, changes shouldn’t affect any of the other layers.
- Repository — This contains all backend communication like SQL databases etc. Allows you to replace the repository layer with another persistent technology.
For communication between layers, we can use Data Transfer Objects (DTO). For simplification, we can use domain models, which belong primarily to the service layer. If we want to clearly separate (and strictly follow the Single Responsibility Principle), we can create extra DTOs for the Controller and Repository layers as well.
As we said, those layers should be separated on the building level (e.g., by Maven artifacts). Make sure that no unwanted dependency is leaking into the wrong layer (e.g., REST API into the Service layer or even DB libraries into the Controller layer). Also, make sure that controllers and repositories are clean from business logic and vice-versa. Use this rule of thumb: always ask yourself if the Controller/Repository is replaceable by a new one as is, and there is no need for re-implementing anything from the business logic to a new Controller/Repository.
Things are getting a little bit complicated now, so packages should be named well. The best practice seems to be that the artifact’s name should be created from part of the package name to easily be able to find the artifacts from the Stacktrace (e.g., artifact’s name: manta-controller derived from eu.manta.controller.user). We can avoid the package name prefix because, in most cases, it is obvious and the suffix (after layer name) because of its containment of the artifacts.
Reasons for Using Controller/Service/Repository Layers
- Allows replaceable Controllers and Repositories.
- Clean Controller/Repository from business code and vice versa.
- Code responsibility separation.
Ports/Adapters Architecture
The third step is to create contracts — Ports — between layers and Invert the direction of dependency between the Service and Repository layers. On the build level, the dependencies look like this: Controller -> InputPort <- Service -> OutputPort <- Repository. This architectural pattern is also known as Hexagonal architecture and was created by Alistar Cockburn.
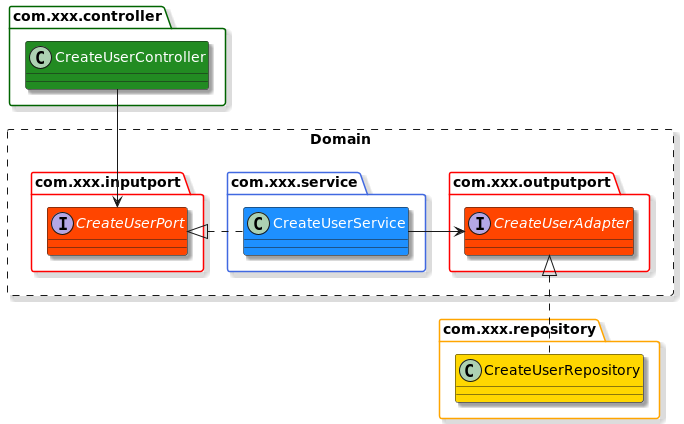
This is the next step further from Layered architecture. It solves the obvious problem that the Service layer depends on Repository, so the Repository is not replaceable as is. Also, we have two new artifacts here: input port and output port. They contain interfaces that define the contract between layers. They can also contain DTO if we consider them useful or if we want to be compliant with the Single Responsibility Principle.
Ports
- Clearly defines a contract for input — by interface and optionally by DTOs.
- From the point of view of the Service layer, it’s input.
- They can be called from the Controller layer.
- The xxxPort interface should be implemented by the Service layer.
- Easier tests — we can avoid Controller/Repository or replace by mock.
Adapters
- Clearly defines a contract for output.
- From the point of view of the Service layer, its output.
- They can be called from the Service layer.
- The xxxAdapter needs to be implemented by the Repository layer.
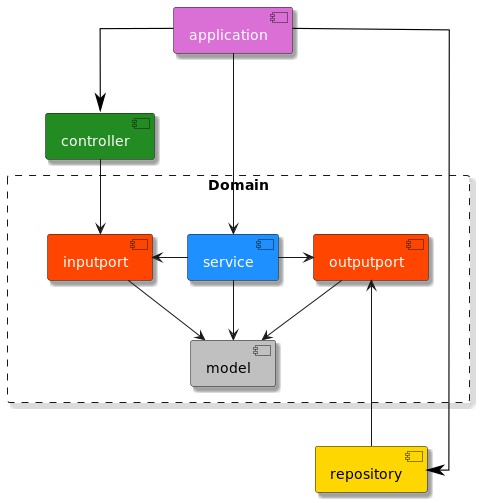
Reasons for Using Ports/Adapters Architecture
- Solves drawback of layered architecture — both Controller/Repository are replaceable.
- Enforces loosely coupled application components more than layer architecture.
- Removes undesired dependencies between layers.
- Completely decouples your application from the details like front-end and back-end choice.
That’s it. With those three steps, you should evolve your code base to be ready enough for microservices if you wish to do so. And more importantly, it’s easy to maintain and keep in the code as time goes on. Lastly, it’s simple enough that you can quickly join juniors into your team.
Published at DZone with permission of David Bucek. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments