How to Manage a Data Science Project for Successful Delivery
See how you should be managing your data science project for successful delivery.
Join the DZone community and get the full member experience.
Join For FreeDemand for data science projects is achieving a breakthrough in business. Many practitioners believe that data science is serving their business efficiently. But many data science projects fail due to improper workflow while providing services to the customer. The truth is that being successful in data science in a business setting is a complex challenge.
Ever had this great idea for a data science project or business? In the end, you didn't because you don't know how to make it successful?
In this article, we are giving a brief description of how you can manage a data science project for successful delivery.
What Is A Data Science Project?
Before proceeding further, it is necessary to understand what a data science project is. Very few companies understand the difference between data science and an analytical project. Analytical projects require stakeholders to make decisions before unlocking value. Data science projects create digital products that deliver value through fully automated micro-decisions.
Data science projects use a logically driven or statistical analysis process supported by data. The end result of any data science project is a recommendation or conclusion on which the stakeholder can make effective business decisions.
What Is the Data Science Problem?
There are some problems facing the data scientist while working on a data science project, some described below:
- Categorize or group data
- Identify patterns
- Identify anomalies
- Show correlations
- Predict outcomes
How to Solve Data Science Problems
A problem statement in data science can be solved by following the following steps:
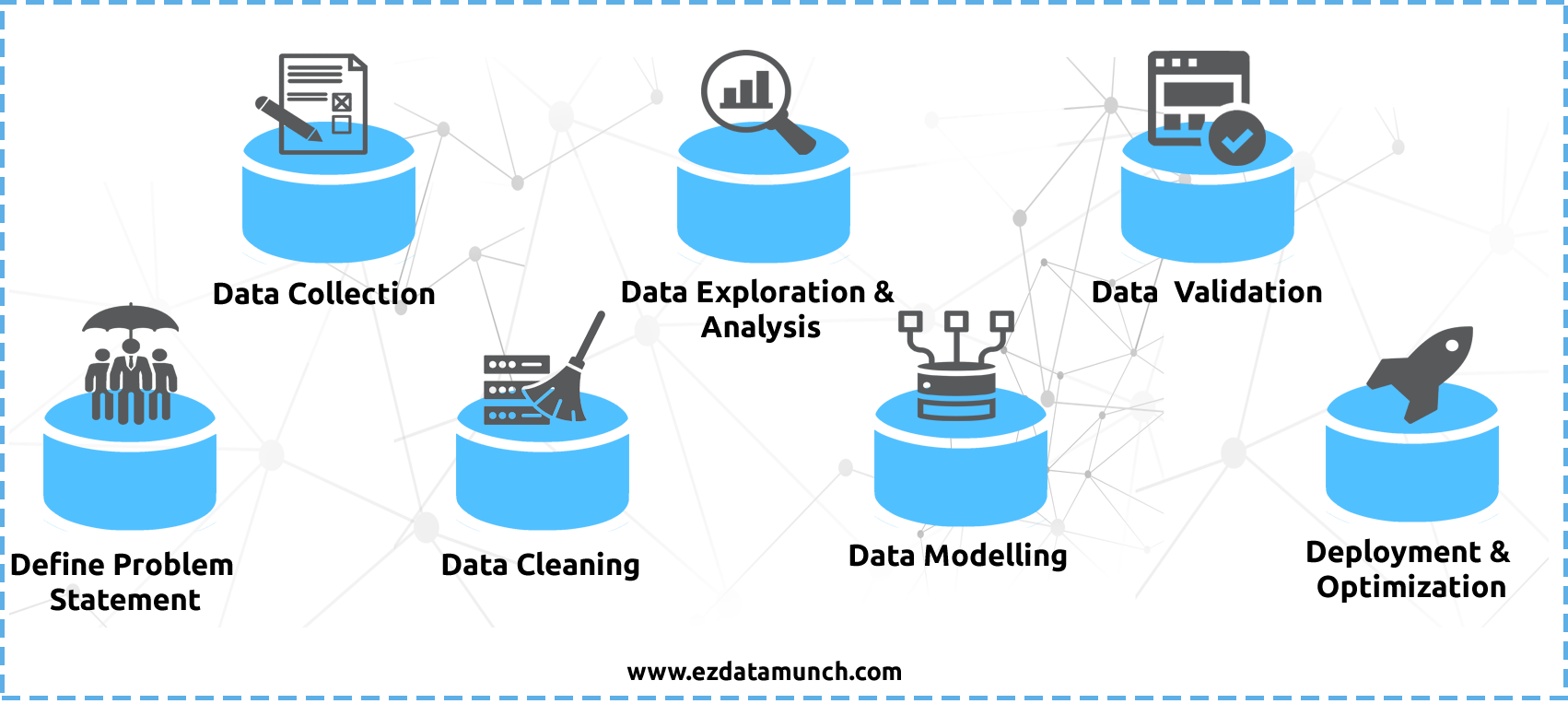
Step 1: Define Problem Statement
Before you start a data science project, first you have to define your problem, which you will face in the project lifecycle. At this stage, you should be clear about all the objectives of your business.
Step 2: Data Collection
At this stage, you need to collect all the data needed to solve the problem. This process will be easier if you do prior research on what the data should be and where it should be collected. This process is not as easy as we think because the data does not exist in any database so that we can get it easily, we have to put a lot of effort into finding the data.
Step 3: Cleaning the Data
Data cleaning is the least preferred task for any data scientist. The task of cleaning the data includes the removal of redundant, missing words, duplication, and redundant data. According to the data scientist, it was observed that one of the time-consuming processes. But if we need explicit output then this step becomes necessary.
Step 4: Data Analysis and Exploration
Once the process of cleaning your data is complete then the next step is data analysis and data exploration. In this step, you should find out the methods and patterns used on the data. At the end of this step, you should start making hypotheses about your data and the problem you are dealing with.
Step 5: Data Modelling
Data Modelling is the process of creating a data model on the data that are stored on a database. Data modeling helps solve your problem to some extent. A model can be a Machine Learning Algorithm that is trained and tested using the data.
Step 6: Optimization and Deployment
This is the end of the process. Here you have to try to improve the efficiency of the created data model so that to make more accurate predictions. This stage is also used for checking the issues and error if caught then solve within this stage before deploying.
What Needs to Be Considered to Make a Data Science Project a Success
No data science project can succeed on its own. It comes with some key points, which we have to think about.
Communication Factor:
Communication has proven to be an effective method for a successful data science project. The purpose of the business must be clearly understood before processing a project.
Business Understanding:
Business understanding, which occurs only through interactions with business stakeholders who are closest to the process or problem.
Proper Planning:
The plan should be solid. This applies to all team members and they have to understand the role of individuals to make projects successful.
Checklist:
Teams should always follow the checklist rules. It is the responsibility of the project manager to check the work in action.
Creating a Founder Layer for a Data Science Project
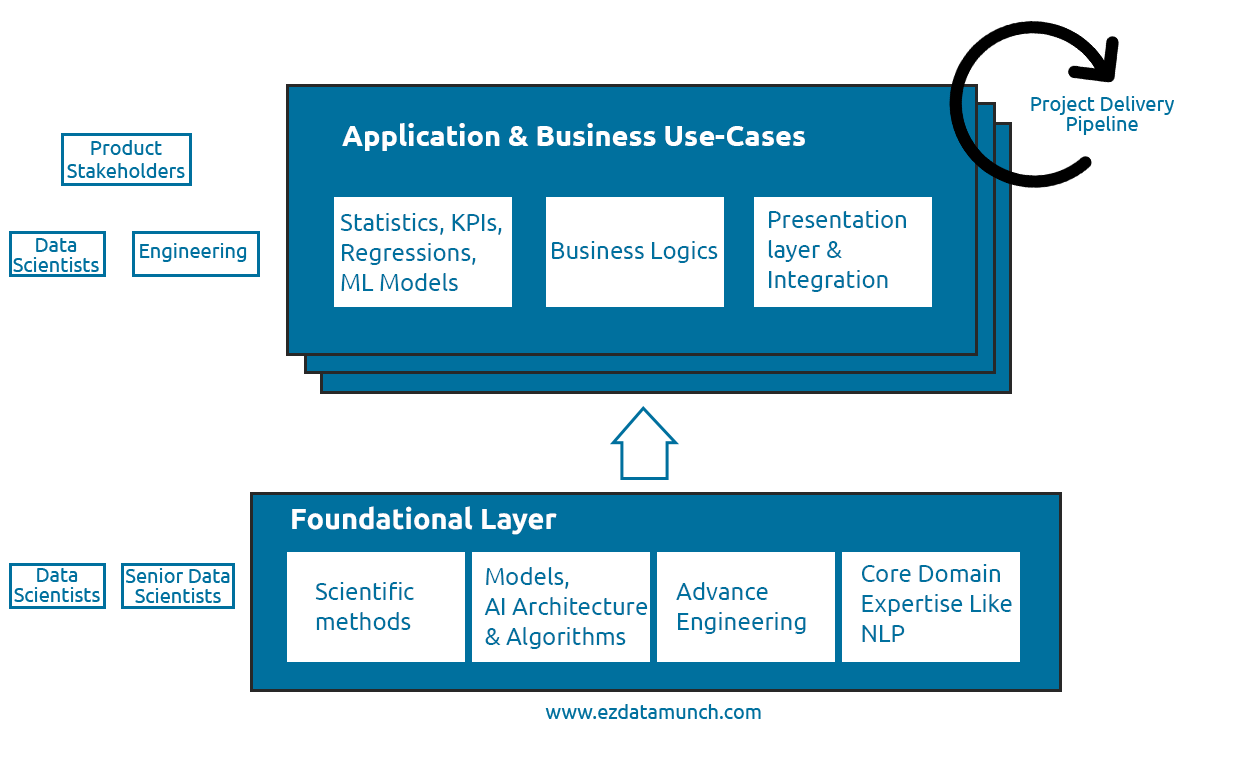
The factor that distinguishes the data science function from software development is the amount of open-ended research that comes in the role of a data scientist. Research is an essential part of data science but does not fit standard agile procedures very well.
Data scientists have to adjust their time for research to create an adjustable layer, where data science adopts a constantly evolving field in the specific context of the business.
A foundational layer can be classified into 3 layers:
Long term: Operated by specialized research teams in established data-driven high-tech companies.
Medium-term: Creating a measurable foundation by transforming key domains sometimes evolving in data science into a business-specific context.
Short term: Application-specific challenges such as solution design, presentation layers, algorithm selection, and validation methods of models and metrics.
Many reputable companies are hiring expertise and talented employees for related domains. There is a need to continuously invest in the foundation layer to keep resources relevant and to provide the data science team with opportunities for growth. This is important for team motivation and retention. Building the foundational layer and managing the workflow should be an internal responsibility for data scientists.
Data Science Project Management Requirement
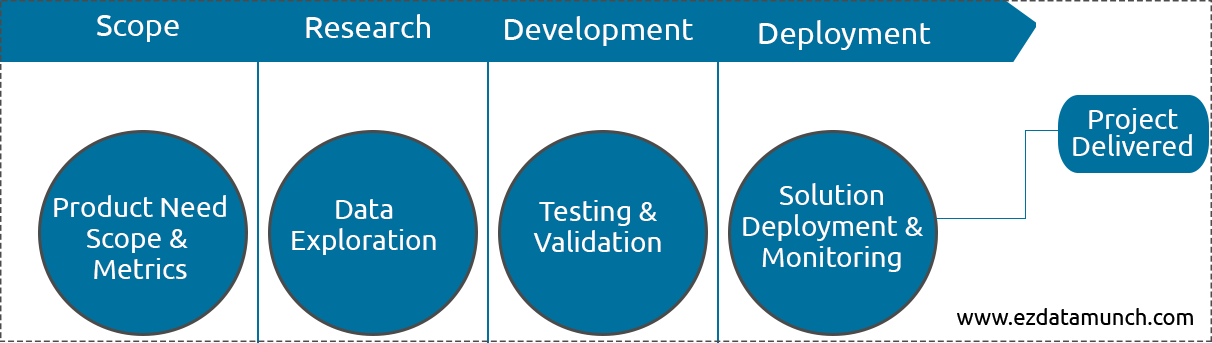
The scoping phase begins with the needs and requirements of the product. The main objectives will address a successful project to reach a scope between product and data science. The thought process must be heavily data-informed and lie heavily with the data science team to define the realistic project scope.
The research phase will be able to draw from the foundations built by the data science team. This final solution restricts excellent research to short-term application-specific challenges to designing (including presentation layers and APIs), algorithm selection and validation methods such as models and agreed metrics.
In the development phase, data scientists write code and implement how it works. But it is very different from the way software engineers work. This is why data scientists use notebooks instead of traditional IDEs.
The deployment of models is a challenging subject in itself. Typically, the model data scientists developed in the previous step required significant work to translate into an enterprise solution that could be deployed on an existing stack. This includes requirements for logging, monitoring, auditing, authentication, SLAs etc.
Opinions expressed by DZone contributors are their own.
Comments