How To Rewrite a Huge Codebase
Joel Spolsky was wrong. You *can* rewrite a huge code base if you learn modern tools.
Join the DZone community and get the full member experience.
Join For FreeOh no! You have to rewrite that huge legacy app! You've already argued that you can fix the legacy code and you've sent the managers the Joel Spolsky "never rewrite" article. Management responds by pointing out that both Basecamp and Visual Studio both had famously successful rewrites.
Do you update your CV or do you tuck in and get the job done?
Sometimes the rewrite is where you're at. Either you've made the decision or you were given the order. Maybe it's because your product is written in VB 6, or UniBasic, or Easytrieve (all of which I've programmed in), and you can't find developers. Or maybe the software is a slow, CPU-bound memory hog and Python or Perl just aren't great choices there.
Whatever your reasons, you need a clean strategy. A problem this hard can't be covered in a couple of paragraphs, but by the time we get to the end, I'll give you a fighting chance of not only making that rewrite succeed but also avoiding exchanging one plate of spaghetti code for another, a common problem with rewrites. This isn't the only way to approach this problem, but I've seen this work and as a bonus, you'll be developing an SOA (service-oriented architecture). If you're unsure why you should do that, read Steve Yegge's epic rant on the topic.
I will start by assuming you already understand the vertical layering of an application. The MVC pattern is common for a Web site, with the individual model, view, and controller layers themselves being layered. In vertical layering, no layer should talk to a layer that's not adjacent to it.
However, there's also horizontal layering. If you have a simple e-commerce site, you might have a search, a shopping cart, a payment system, and so on. Understanding horizontal layers are the key to successfully rewriting a legacy application.
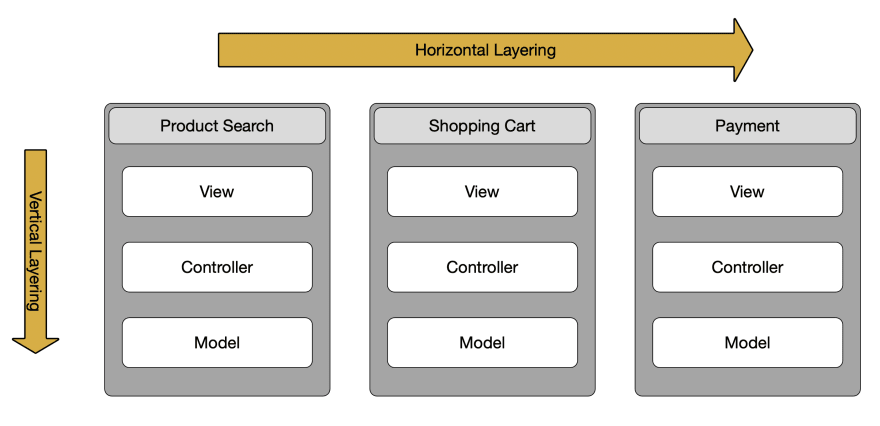 Now obviously, in a legacy code base, you're unlikely to have such a clean separation of concerns, but you will need to slowly start to tease apart your application, one horizontal layer at a time, to make this work.
Now obviously, in a legacy code base, you're unlikely to have such a clean separation of concerns, but you will need to slowly start to tease apart your application, one horizontal layer at a time, to make this work.
OpenAPI
First, we need to understand OpenAPI. OpenAPI, formerly known as Swagger, is a specification for defining your REST API. With that, you can generate clients and/or servers that conform to that API. To save time, you can use the OpenAPI generator to generate a working client or a server stub (you have to supply the actual logic for the server, of course) for a wide variety of languages.
Furthermore, if you design your OpenAPI document well, you can automate the documentation for it!
OpenAPI is truly a powerful tool. What makes it a good choice for rewrites is that it helps you create a black box with an extremely well-defined interface. We'll need that.
Here's what part of an OpenAPI document might look like. This is YAML, but you can use JSON if you prefer.
paths:
/product/category/{category}:
get:
summary: Returns a list of products for a given category.
responses:
'200':
description: A JSON array of product objects
content:
application/json:
schema:
type: array
items:
type: object
In the above snippet, we have routes like GET /product/category/some_category. Your server is expected to pass some_category to the endpoint which handles that route and for a 200 OK response, you must return an array of objects.
Of course, you can return other responses and define their response structure, too, allowing the client to know how to automatically handle 404s and 500s, rather than simply guessing.
Using OpenAPI To Rewrite
If you look at the diagram about layering, you're going to think of your horizontal layers (search, shopping cart, checkout, etc.) as potential services you can expose via OpenAPI. If you've never done anything like this before, you'll need to tread slowly.
You're going to take one of those horizontal layers and convert it to OpenAPI. This one is up to you, but I'd recommend the smallest, simplest layer you can find to start with. This will make the OpenAPI specification easier to write and will give you more experience in how to make this work.
First, identify the core functionality that this layer needs to expose. For search, maybe it's just searched by category and search by name. So you'll need at least two endpoints that are exposed.
Build out your OpenAPI spec, build out your server stubs, and then fill them in, writing tests against the API along the way.
Next, you start slowly disentangling the search layer from the rest of the code, like slowly picking apart a knot. Depending on how well your system is designed, this could be quick and easy, or slow and painful. Over time, this gets easier with other layers due to previous layers being removed and having more experience doing this.
As part of this disentangling, you have identified everywhere in your code that requires those searches. One by one, start having them call your OpenAPI routes and not call the search code directly.
When done, you've started on the path to creating an SOA (Service-Oriented Architecture). Before we go on, let's take a look at where we are.
First, more code can conceivably use the service because it's less coupled with the existing code. Second, you might find you have an actual product! If your service is interesting enough, you could potentially offer that to the outside world. Imagine selling something that hobbyists enjoy and now their websites, with an API key and a little bit of Javascript, could embed your search on their site.
Heck, you could even write the Javascript for them and publish it on your site to make it easier for others to include your content on their sites. OpenAPI is a game-changer.
Peeling Off the Layer
Now that we've gotten a good start on creating a service, we need to make it more robust. Specifically, you want to separate this code so that it can be deployed separately and removed from the original repository. The details of that are very much up to you and your team. However, when deployed separately, you could even deploy it on other servers to lighten the load on the main app servers. In fact, that's one of the nice benefits of SOA: decoupling components so you can manage them separately.
As part of this "peeling off", you also want to write even more tests against the OpenAPI endpoints, with particular emphasis on capturing corner cases that might not be obvious. What's important is that you try to avoid writing tests that depend on the particular programming language you use. Instead, treat the service as a black box and adopt a data-driven approach. You have a series of tests in, say, a YAML document, and each is a request/response cycle. The beginning of the document might look like this:
--- tests: - name: Fetch widgets categoryfixtures:- list- of- fixturesrequest: body: | GET /products/category/widgets HTTP/1.1 Accept-Encoding: gzip User-Agent: Mojolicious (Perl) Content-Length: 0 X-API-Key: 7777777 Host: localhost:7777 Content-Type: application/json response: body: | HTTP/1.1 200 OK Accept-Ranges: none Vary: accept-encoding Date: Thu, 25 Mar 2021 15:56:48 GMT Content-Length: 88 Content-Type: application/json; charset=utf-8 Connection: keep-alive [{...}]- to- load
Why a data-driven approach? First, it discourages "cheating" by using a white-box approach. The second deals with the rewrite phase.
The Actual Rewrite
You've peeled off a horizontal layer. It can be deployed separately. You run your data-driven, black-box tests against it. You use Redoc or something similar to have full documentation automatically written for it. Now you hand it off to the other team for a rewrite into the target language.
First, they use the OpenAPI generator to generate full server stubs for their language of choice. Now, they take the documentation and your tests and just fill in each server stub. They keep going until all tests pass. At that point, they can deploy and your sysadmins can switch the URL/port in your API gateway and away you go! If it fails, they switch it back and you figure out what when wrong.
Your test was data-driven to enforce the black-box approach, but also to allow them to easily port the tests to their target language, if they so desire, and extend them.
While this all seems very hand-wavy at the end, the reality is that most heavy lifting has been done at this point. It's taken a lot to get here, but it's a heck of a lot less than rewriting the entire application from scratch.
Once you've successfully pulled the first layer out into its own OpenAPI service, you keep doing this with successive layers, handing them off to the rewrite teams.
Why This Works
The "never rewrite" dogma got locked in hard after Joel Spolsky's article about it. And frankly, he makes very good points, but he was talking about monolithic applications. By deconstructing them into an SOA, you can do small chunks at a time, reducing the risk considerably. You can even stop the project partway through and still have a huge win. And with the OpenAPI approach outlined above, you have great documentation and tests to give your rewrite developers a fighting chance, something that is often lacking in traditional rewrite scenarios.
Obstacles
It wouldn't be fair to say it's all rainbows and unicorns. It's often not easy to extract a horizontal layer from a monolithic application.
You also have to worry about the quality of the tests being written. It's commonly easy to skimp on tests and only write a few to demonstrate the basics. It's even easier when you are writing tests for code that's already working. The new team won't have a working code, so the tests need extra diligence.
And if Perl is either the source or the destination language, you'll be disappointed to learn that the OpenAPI Generator doesn't have code to handle server stubs for Perl (it can generate a client, though). There's Mojolicious::Plugin::OpenAPI which can help, but not only does it require weaving in non-standard bits like x-mojo-to and x-mojo-name into your OpenAPI doc, but you have to wire all of the bits together yourself. We've done this and frankly, it's not fun. Further, some of our clients have very old codebases that run on older versions of Perl than Mojolicious supports, thus rendering it useless for them.
To address that, our company has started to develop Net::OpenAPI. It's framework agnostic and while it does rely on JSON::Validator, which in turns relies on Mojolicious, we are writing JSON::Validator58 and it should support older versions of Perl.
We still have a lot more work to do on this, but so far it will build out full server stubs, with a PSGI file, and working documentation using Redoc. You just need to fill in the endpoints:
endpoint 'get /pet/{petId}' => sub {
my ( $request, $params ) = @_;
# replace this code with your code
return Net::OpenAPI::App::Response->new(
status_code => HTTPNotImplemented,
body => {
error => 'Not Implemented',
code => HTTPNotImplemented,
info => 'get /pet/{petId}',
},
);
};
It's open-source, and free software, so if you'd like to contribute, pull requests welcome!
Digressions
As a final note, there are a couple of points we need to touch on.
SOA vs Microservices
What's the difference? Are we developing microservices here, or heading towards an SOA?
The easy answer is that microservices are small and self-contained applications, while the services in SOA are larger, more "enterprise-ready" tools. But that doesn't really help.
Microservices are generally expected to have all the logic and data they need to perform a task. They're not coordinating with a bunch of other services and thus are loosely coupled and fit well with agile development.
SOA services, however, need to coordinate with other services in the same way that your Order object needs a Collection of Item objects, along with a Customer object, and so on. In the layers diagram above, all three of the layers will need to know about items, but they'll frequently be treated as data instead of instantiated objects which are passed around.
Duplicate Code
But won't this result in a lot of duplicated code?
For microservices, if they're completely stand-alone but you have several which need to deal with the same business logic, then yes, you could easily have duplicated code and data. This IBM article sums up the dilemma nicely:
In SOA, reuse of integrations is the primary goal, and at an enterprise level, striving for some level of reuse is essential.
In microservices architecture, creating a microservices component that is reused at runtime throughout an application results in dependencies that reduce agility and resilience. Microservices components generally prefer to reuse code by copy and accept data duplication to help improve decoupling.
So when striving for an SOA, because different services coordinate, you can strive for the "single responsibility principle" and avoid duplication. However, if you're rewriting, you probably have a legacy mess. That means technical debt. That means hard decisions. You may have to copy code to get started.
Full or Partial Rewrite?
One of the benefits of this approach is that you can choose to go for a partial rewrite. Just as you might throw away your custom search engine code in favor of ElasticSearch or Typesense, so might you find that a CPU-intensive part of your application can be safely rewritten in Go or Rust. You don't have to make this an all-or-nothing scenario. You can also take the time to do it right, pausing as needed, rather than the death march scenario of the full rewrite.
A Top-Down View
This explanation of SOA has largely been "bottom-up." It's a complex topic, so here's a great "top-down" view of what they learned at Netflix. My overview has been far too brief and you need to understand some of the challenges involved.
TL;DR
The "never rewrite" mantra needs to stop. Instead, it should be "almost never rewrite", but if you must, do so incrementally. We've laid out a clean approach, but be warned: it's clean on paper. If you're backed into the rewrite corner, it's not easy getting out. But you can get out so long as you choose an incremental approach that's more likely to succeed—and bring plenty of patience and courage with you.
Opinions expressed by DZone contributors are their own.
Comments