How To Scale Your Python Services
This article breaks down strategies for scaling Python services, emphasizing on the challenges and solutions for CPU and I/O bound tasks.
Join the DZone community and get the full member experience.
Join For FreePython is becoming a more and more popular choice among developers for a diverse range of applications. However, as with any language, effectively scaling Python services can pose challenges. This article explains concepts that can be leveraged to better scale your applications. By understanding CPU-bound versus I/O-bound tasks, the implications of the Global Interpreter Lock (GIL), and the mechanics behind thread pools and asyncio, we can better scale Python applications.
CPU-Bound vs. I/O-Bound: The Basics
- CPU-Bound Tasks: These tasks involve heavy calculations, data processing, and transformations, demanding significant CPU power.
- I/O-Bound Tasks: These tasks typically wait on external resources, such as reading from or writing to databases, files, or network operations.
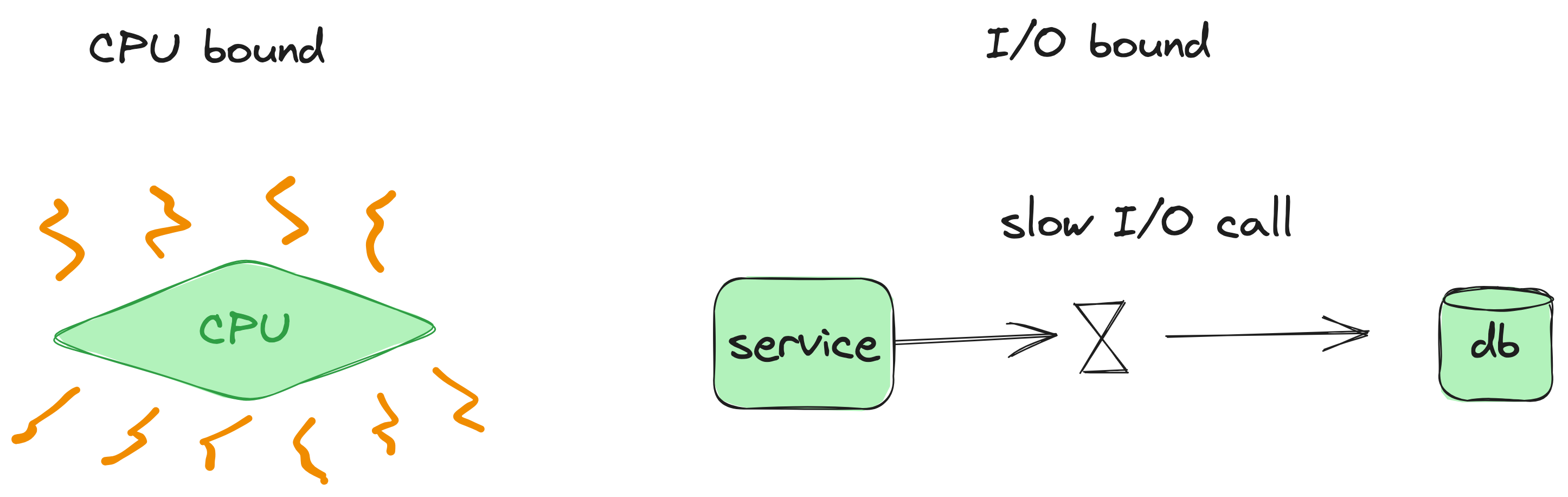
Recognizing if your service is primarily CPU-bound or I/O-bound is the foundation for effective scaling.
Concurrency vs. Parallelism: A Simple Analogy
Imagine multitasking on a computer:
- Concurrency: You have multiple applications open. Even if only one is active at a moment, you quickly switch between them, giving the illusion of them running simultaneously.
- Parallelism: Multiple applications genuinely run at the same time, like running calculations on a spreadsheet while downloading a file.
In a single-core CPU scenario, concurrency involves rapidly switching tasks, while parallelism allows multiple tasks to execute simultaneously.

Global Interpreter Lock: GIL
You might think scaling CPU-bound Python services is as simple as adding more CPU power. However, the Global Interpreter Lock (GIL) in Python's standard implementation complicates this. The GIL is a mutex ensuring only one thread executes Python bytecode at a time, even on multi-core machines. This constraint means that CPU-bound tasks in Python can't fully harness the power of multithreading due to the GIL.
Scaling Solutions: I/O-Bound and CPU-Bound
ThreadPoolExecutor
This class provides an interface for asynchronously executing functions using threads. Though threads in Python are ideal for I/O-bound tasks (since they can release the GIL during I/O operations), they are less effective for CPU-bound tasks due to the GIL.
Asyncio
Suited for I/O-bound tasks, asyncio offers an event-driven framework for asynchronous I/O operations. It employs a single-threaded model, yielding control back to the event loop for other tasks during I/O waits. Compared to threads, asyncio is leaner and avoids overheads like thread context switches.
Here's a practical comparison. We take an example of fetching URL data (I/O bound) and do this without threads, with a thread pool, and using asyncio.
import requests
import timeit
from concurrent.futures import ThreadPoolExecutor
import asyncio
URLS = [
"https://www.example.com",
"https://www.python.org",
"https://www.openai.com",
"https://www.github.com"
] * 50
# Function to fetch URL data
def fetch_url_data(url):
response = requests.get(url)
return response.text
# 1. Sequential
def main_sequential():
return [fetch_url_data(url) for url in URLS]
# 2. ThreadPool
def main_threadpool():
with ThreadPoolExecutor(max_workers=4) as executor:
return list(executor.map(fetch_url_data, URLS))
# 3. Asyncio with Requests
async def main_asyncio():
loop = asyncio.get_event_loop()
futures = [loop.run_in_executor(None, fetch_url_data, url) for url in URLS]
return await asyncio.gather(*futures)
def run_all_methods_and_time():
methods = [
("Sequential", main_sequential),
("ThreadPool", main_threadpool),
("Asyncio", lambda: asyncio.run(main_asyncio()))
]
for name, method in methods:
start_time = timeit.default_timer()
method()
elapsed_time = timeit.default_timer() - start_time
print(f"{name} execution time: {elapsed_time:.4f} seconds")
if __name__ == "__main__":
run_all_methods_and_time()Results
Sequential execution time: 37.9845 seconds ThreadPool execution time: 13.5944 seconds Asyncio execution time: 3.4348 seconds
The results reveal that asyncio is efficient for I/O-bound tasks due to minimized overhead and the absence of data synchronization requirements, as seen with multithreading.
For CPU-bound tasks, consider:
- Multiprocessing: Processes don't share the GIL, making this approach suitable for CPU-bound tasks. However, ensure that the overhead of spawning processes and inter-process communication doesn't diminish the performance benefits.
- PyPy: An alternative Python interpreter with a Just-In-Time (JIT) compiler. PyPy can deliver performance improvements, especially for CPU-bound tasks.
Here, we have an example of regex matching (CPU bound). We implement it using without any optimization and using multiprocessing.
import re
import timeit
from multiprocessing import Pool
import random
import string
# Complex regex pattern for non-repeating characters.
PATTERN_REGEX = r"(?:(\w)(?!.*\1)){10}"
def find_pattern(s):
"""Search for the pattern in a given string and return it, or None if not found."""
match = re.search(PATTERN_REGEX, s)
return match.group(0) if match else None
# Generating a dataset of random strings
data = [''.join(random.choices(string.ascii_letters + string.digits, k=1000)) for _ in range(1000)]
def concurrent_execution():
with Pool(processes=4) as pool:
results = pool.map(find_pattern, data)
def sequential_execution():
results = [find_pattern(s) for s in data]
if __name__ == "__main__":
# Timing both methods
concurrent_time = timeit.timeit(concurrent_execution, number=10)
sequential_time = timeit.timeit(sequential_execution, number=10)
print(f"Concurrent execution time (multiprocessing): {concurrent_time:.4f} seconds")
print(f"Sequential execution time: {sequential_time:.4f} seconds")
Results
Concurrent execution time (multiprocessing): 8.4240 seconds Sequential execution time: 12.8772 seconds
Clearly, multiprocessing is better than sequential execution. The results will be far more evident with a real-world use case.
Conclusion
Scaling Python services hinges on recognizing the nature of tasks (CPU-bound or I/O-bound) and choosing the appropriate tools and strategies. For I/O bound services, consider using thread pool executors or asyncio, whereas for CPU-bound services, consider leveraging multiprocessing.
Opinions expressed by DZone contributors are their own.
Comments