How to Spider a Site With JMeter
The team at Blazemeter talks about using the JMeter tool for a repeatable process to crawl a website and randomly click on links within the site.
Join the DZone community and get the full member experience.
Join For FreeWhen it comes to building a web application load test, you might want to simulate a group of users “crawling” the website and randomly clicking the links. Personally, I don’t like this form of testing, as I believe that the load test needs to be repeatable, so each consecutive test hits the same endpoints and assumes the same throughput as the previous one. If the entry criteria is different, it’s harder to analyze the load test results.
Sometimes this rule isn’t applicable, especially for dynamic websites like blogs, news portals, social networks, etc., where new content is being added very often or even in real time. This form of testing ensures the user will get a smooth browsing experience and also checks for broken links or any unexpected errors.
This article covers the 3 most common approaches of simulating website “crawling”: clicking all links found in the web page, using HTML Link Parser and the advanced spidering test plan.
1. Clicking All Links Found in the Web Page
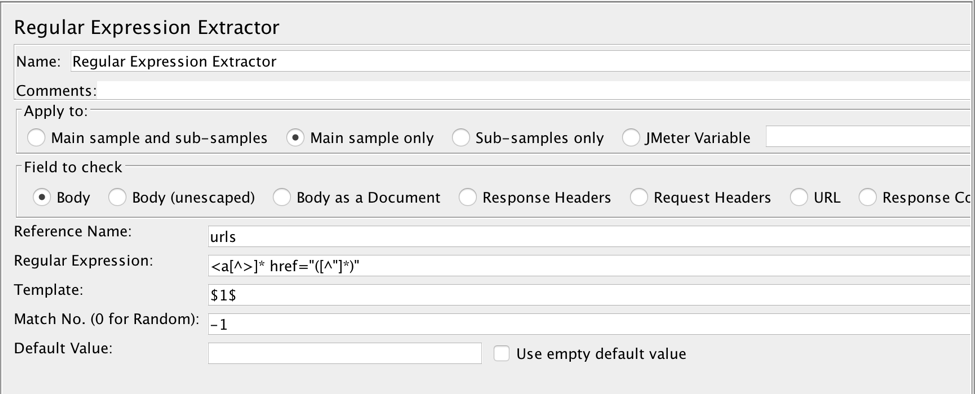
The process of getting the links using Regular Expression Extractor is described in the Using Regular Expressions in JMeter article. The algorithm is as simple as this:
1a. Extracting all the links from the response with the Regular Expression Extractor and store them into JMeter Variables. The relevant regular expression would be something like:
<a[^>]* href="([^"]*)"
Don’t forget to set Match No. to -1 to extract all links. If you leave it blank, only the first match will be returned.
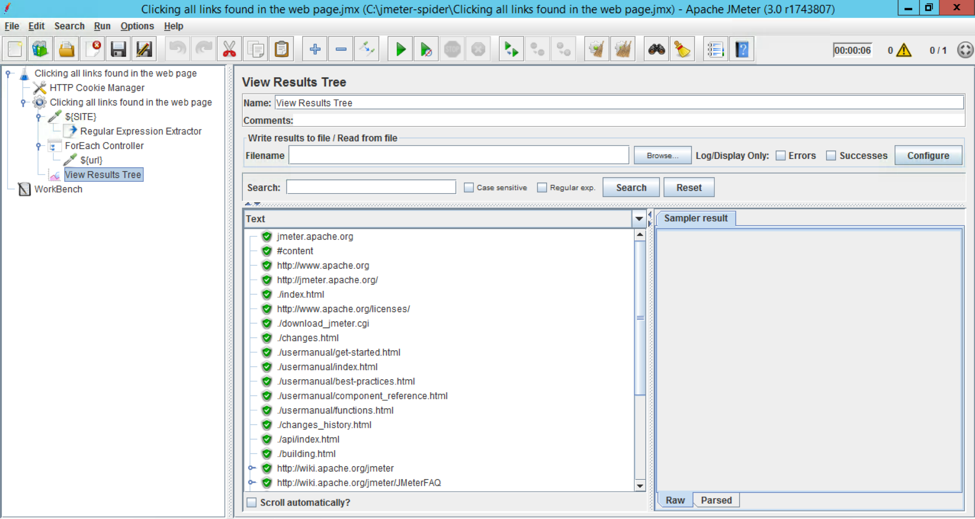
1b. Use ForEach Controller to iterate the extracted links.
1c. Use HTTP Request sampler to hit the URL living in the Output Variable Name.
Demo
Pros
Simplicity of configuration.
Stability.
Failover and resilience .
Cons
Regular Expressions are hard to develop and sensitive to markup change hence fragile.
Not actually a “crawler” or “spider,” just consequential requests to links.
2. Using HTML Link Parser
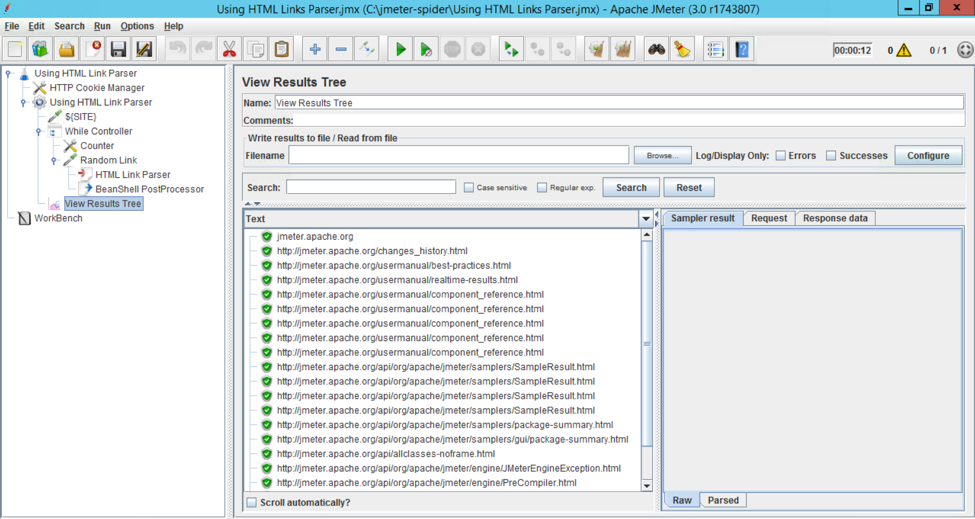
JMeter provides a special Test Element, HTML Link Parser. This element is designed for extracting HTML links and forms and substituting matching HTTP Request Sampler relevant fields with the extracted values. Therefore, HTML Link Parser can be used to simulate crawling the website with minimal configuration. Here’s how:
2a. Put the HTML Link Parser under a Logic Controller (i.e., Simple Controller if you just need a “container” or While Controller to set a custom condition like maximum number of hits)
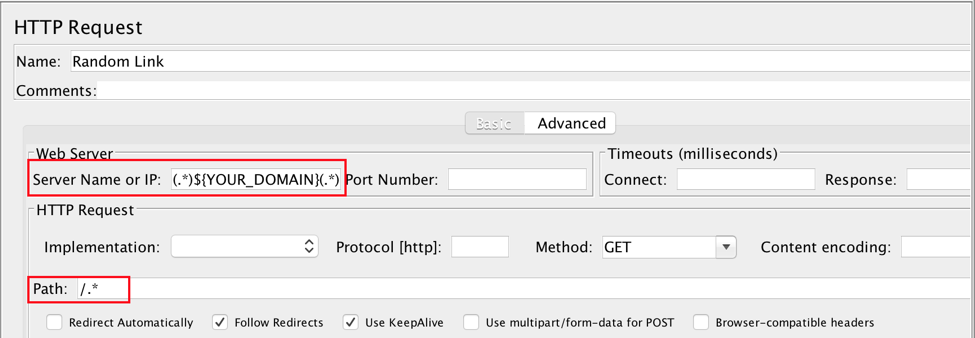
2b. Put the HTTP Request Sampler under the Logic Controller and configure Server Name or IP and Path fields to limit the extracted values to an “interesting” scope. You probably want to focus on domain(s) belonging to the application under test and don’t want it to crawl over the Internet, because if your application has any link that leads to an external resource; JMeter will go outside. Perl5-style regular expressions can be used to set the extracted links scope.
Demo
Pros
Easy to configure and use.
Acts like a “spider.”
Cons
Zero error tolerance; any failure to extract links from the response will cause cascade failures of subsequent requests.
3. Advanced “Spidering” Test Plan
Assuming the limitations of the above approaches, you might want to come up with a solution that won’t break on errors and will be crawling the whole application under test. Below you can find a reference Test Plan outline which can be used as a skeleton for your “spider”:
3a. Open the main page.
Extract all the links from it.
Click on a random link.
If the returned value has “good” MIME type (if link results in an image or PDF document or whatever link extraction will be skipped); extract all links from the response.
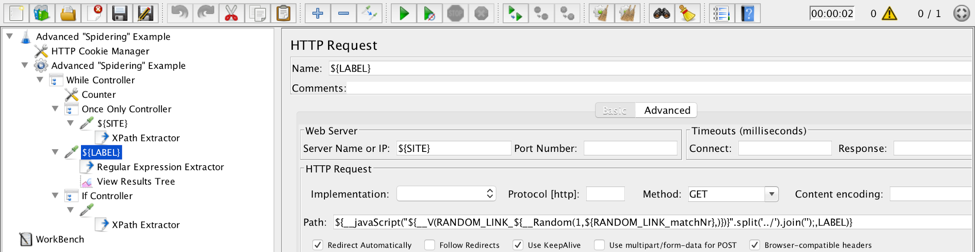
Explanation of the used elements:
While Controller is used to set the maximum amount of requests so the test won’t last forever. If you limit via scheduling, you can skip it.
Once Only Controller is used to execute a call to the main page only once.
XPath Extractor is used to filter out URLs that don’t belong to the application under test and other links that are not interesting like mailto, callto, etc. An Example XPath query will look like:
//a[starts-with(@href,'/') or starts-with(@href,'.') or contains(@href,'${SITE}') and not(contains(@href,'mailto'))]/@href
Using XPath is not a must, and in some cases, it may be very memory intensive. You may need to consider other ways of fetching the links from the response. It is used for demonstration purposes as normally XPath queries are more human-readable than CSS/JQuery and especially Regular Expressions.
__javaScript() function actually does three things:
Chooses a random link out of the extracted by the XPath Extractor.
Removes ../ from the beginning of the URLs.
Sets HTTP Request title to the current random URL.
Regular Expression Extractor is used to extract Content-Type header from the response
If Controller makes it so that the next round of extracting links from the response will start only if the response has matching content type.
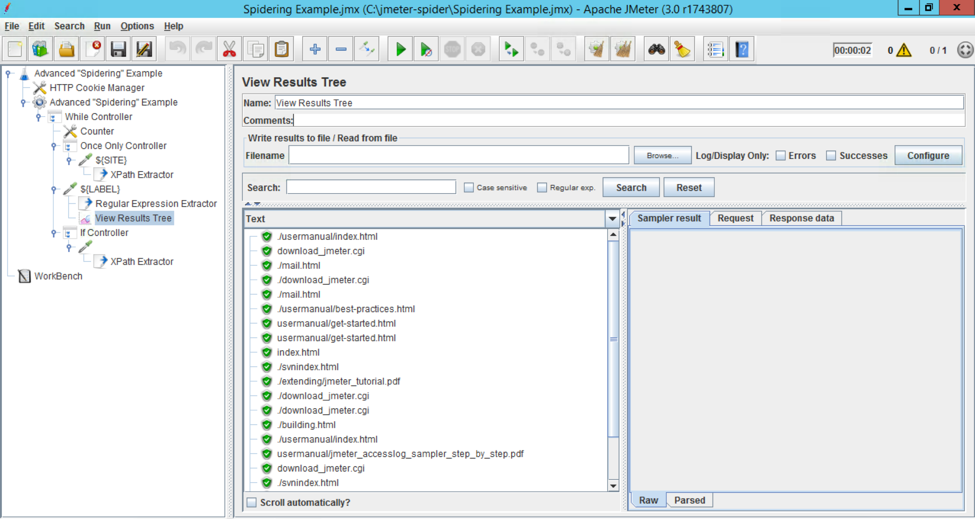
Demo
Pros
Extreme flexibility and configurability.
Cons
Complexity.
If you want to try the above scripts yourself, they are available at jmeter-spider repository. As usual, feel free to use the below discussion box to express any form of feedback.
Published at DZone with permission of Ilan Hertz. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments