How Vector Search Can Optimize Retail Trucking Routes
A look at how to find the best route to gain efficiency in delivery times as well as in loading the trucks with vector search.
Join the DZone community and get the full member experience.
Join For FreeVectors and vector search are key components of large language models (LLMs), but they are useful in a host of other applications across many use cases that you might not have considered. How about the most efficient way to deliver retail goods?
In two prior articles in this series, I told a story of a hypothetical contractor who was hired to help implement AI/ML solutions at a big-box retailer, and then explored how this distributed systems and AI specialist used vector search to drive results with customer promotions at the company. Now, I’ll walk you through how this contractor uses vector search to optimize trucking routes.
The Problem
While we were looking at our options for scaling-down (and ultimately disabling) the recommendation batch job from the first story in this series, we were invited to a meeting with the Transportation Services team. They had heard how we assisted the Promotions team and were wondering if we could take a look at a problem of theirs.
BigBoxCo has its products trucked in from airports and shipping ports. Once at the distribution center (DC), they are tagged and separated into smaller shipments for the individual brick-and-mortar stores. While we have our own semi trailers for this part of the product journey, the fleet isn’t efficiently organized.
Currently, the drivers are given a list of stores on the truck’s digital device, and the supervisor suggests a route. However, the drivers often balk about the order of store stops, and they often disregard their supervisors’ route suggestions. This, of course, leads to variances in expected shipment and restock times, as well as in total time taken.
Knowing this, the DC staff is unable to fill each truck container completely, because they have to leave space in the truck for access to the product pallets for each store. Ideally, the product pallets would be ordered with the first store's pallet in the most accessible position in the trailer.
Improving the Experience
The Transportation Services team would like us to examine the available data and see if there is a smarter way to approach this problem. For instance, what if there was a way that we could pre-determine the best possible route to take by determining the order in which the driver should visit the stores?
This is similar to the “traveling salesman problem” (TSP), a hypothetical problem in which a salesman is given a list of cities to visit, and needs to figure out the most efficient route between them. While coded implementations of the TSP can become quite complex, we might be able to use a vector database like Apache Cassandra’s for vector search capability to solve this.
The obvious approach is to plot out each of the geolocation coordinates of each destination city. However, the cities are only spread out over a local, metropolitan area, which means that latitude and longitude whole numbers would be mostly the same. That isn’t going to lead to a lot of easily detectable variance, so we should refocus that data by just considering the numbers to the right of the Geo URI scheme decimal point.
For example, the city of Rogersville (the location of one of our BigBoxCo stores) has a Geo URI of 45.200,-93.567. We’ll be able to detect variance from this and other vectors more easily if we look to the right of each decimal point of our coordinates, arriving at adjusted coordinates of 200,-567 (instead of 45.200,-93.567).
Taking this approach with the local metro cities with our stores gives us the following data:
adjusted Lat |
adjusted Lon |
|
Rogersville |
200 |
-567 |
Maplewood |
73 |
-456 |
Rockton |
11 |
-456 |
Victoriaville |
94 |
-356 |
Parktown |
-52 |
-348 |
Zarconia |
37 |
-359 |
Farley |
86 |
-263 |
Table 1: Adjusted geo URI scheme coordinates for each of the cities with BigBoxCo stores, as well as the distribution center in Farley.
With a list of simplified coordinates like these, let’s look at getting something to work with them.
Implementation
Now that we have data, we can create a table in our Cassandra cluster with a two-dimensional vector. We will also need to create a SSTable attached secondary index (SASI) on the vector column:
CREATE TABLE bigbox.location_vectors (
location_id text PRIMARY KEY,
location_name text,
location_vector vector<float, 2>);
CREATE CUSTOM INDEX ON bigbox.location_vectors (location_vector) USING 'StorageAttachedIndex';This will enable us to use a vector search to determine the order in which to visit each city. It’s important to note, however, that vector searches are based on cosine-based calculations for distance, assuming that the points are on a flat plane. As we know, the Earth is not a flat plane. Calculating distances over a large geographic area should be done using another approach like the Haversine formula, which takes the characteristics of a sphere into account. But for our purposes in a small, local metro area, computing an approximate nearest neighbor (ANN) should work just fine.
Now let us load our city vectors into the table, and we should be able to query it:
INSERT INTO bigbox.location_vectors (location_id, location_name, location_vector) VALUES ('B1643','Farley',[86, -263]);
INSERT INTO bigbox.location_vectors (location_id, location_name, location_vector) VALUES (B9787,'Zarconia',[37, -359]);
INSERT INTO bigbox.location_vectors (location_id, location_name, location_vector) VALUES (B2346,'Parktown',[-52, -348]);
INSERT INTO bigbox.location_vectors (location_id, location_name, location_vector) VALUES ('B1643','Victoriaville',[94, -356]);
INSERT INTO bigbox.location_vectors (location_id, location_name, location_vector) VALUES ('B6789','Rockton',[11, -456]);
INSERT INTO bigbox.location_vectors (location_id, location_name, location_vector) VALUES ('B2345','Maplewood',[73, -456]);
INSERT INTO bigbox.location_vectors (location_id, location_name, location_vector) VALUES ('B5243','Rogersville',[200, -567]);To begin a route, we will first consider the warehouse distribution center in Farley, which we have stored with a vector of 86, -263. We can begin by querying the location_vectors table for the ANNs of Farley’s vector:
SELECT location_id, location_name, location_vector, similarity_cosine(location_vector,[86, -263]) AS similarity
FROM location_vectors
ORDER BY location_vector
ANN OF [86, -263] LIMIT 7;The results of the query look like this:
location_id | location_name | location_vector | similarity
-------------+---------------+-----------------+------------
B1643 | Farley | [86, -263] | 1
B5243 | Rogersville | [200, -567] | 0.999867
B1566 | Victoriaville | [94, -356] | 0.999163
B2345 | Maplewood | [73, -456] | 0.993827
B9787 | Zarconia | [37, -359] | 0.988665
B6789 | Rockton | [11, -456] | 0.978847
B2346 | Parktown | [-52, -348] | 0.947053(7 rows)
Note that we have also included the results of the similarity_cosine function, so that the similarity of the ANN results is visible to us. As we can see, after disregarding Farley at the top (100% match for our starting point), the city of Rogersville is coming back as the approximate nearest neighbor.
Next, let’s build a microservice endpoint that essentially traverses the cities based on a starting point and the top ANN returned. It will also need to disregard cities that it’s already been to. Therefore, we build a method that we can POST to, so that we can provide the ID of the starting city, as well as the list of cities for the proposed route in the body of the request:
curl -s -XPOST http://127.0.0.1:8080/transportsvc/citylist/B1643 \
-d'["Rockton","Parktown","Rogersville","Victoriaville","Maplewood","Zarconia"]' -H 'Content-Type: application/json'Calling this service with the location_id B1643 (Farley) returns the following output:
["Rogersville","Victoriaville","Maplewood","Zarconia","Rockton","Parktown"]
So this works great in the sense that it’s providing some systematic guidance for our trucking routes. However, our service endpoint and (by proxy) our ANN query don’t have an understanding of the highway system that connects each of these cities. For now, it’s simply assuming that our trucks can travel to each city directly “as the crow flies.”
Realistically, we know this isn’t the case. In fact, let’s look at a map of our metro area, with each of these cities and connecting highways marked (Figure 1).
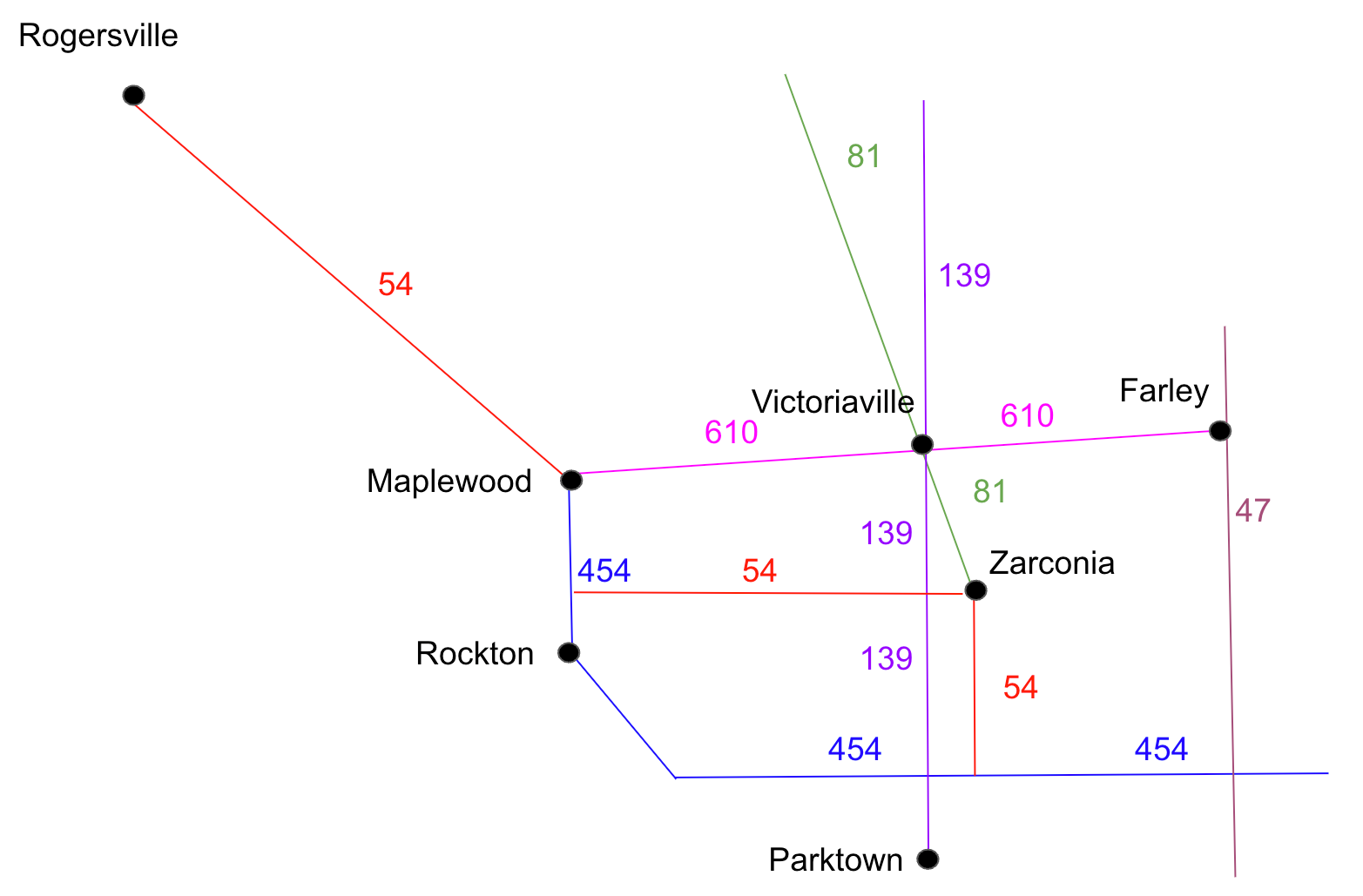
Figure 1: A map of our local metropolitan area showing each of the cities with BigBoxCo stores, as well as the connecting highway system.
Each highway is shown with their names, colored differently to clearly distinguish themselves from each other.
One way to increase accuracy here would be to create vectors for the segments of the highways. In fact, we could create a highway table, and generate vectors for each by their starting and ending coordinates based on how they intersect with each other and our cities.
CREATE TABLE highway_vectors (
highway_name TEXT PRIMARY KEY,
highway_vector vector<float,4>);CREATE CUSTOM INDEX ON highway_vectors(highway_vector) USING 'StorageAttachedIndex';
We can then insert vectors for each highway. We will also create entries for both directions of the highway segments, so that our ANN query can use either city as the starting or ending points. For example:
INSERT INTO highway_vectors(highway_name,highway_vector)
VALUES('610-E2',[94,-356,86,-263]);
INSERT INTO highway_vectors(highway_name,highway_vector)
VALUES('610-W2',[86,-263,94,-356]);Going off of the result from our original query, we can run another query to pull back highway vectors with an ANN of the coordinates for the DC in Farley (86,-263) and our store in Rogersville (200,-567):
SELECT * FROM highway_vectors ORDER BY highway_vector ANN OF [86,-263,200,-567] LIMIT 4;
highway_name | highway_vector
--------------+-----------------------
610-W2 | [86, -263, 94, -356]
54NW | [73, -456, 200, -567]
610-W | [94, -356, 73, -456]
81-NW | [37, -359, 94, -356](4 rows)
If we look at the map shown in Figure 1, we can see that Farley and Rogersville are indeed connected by highways 610 and 54. Now we’re on to something!
We could build another service endpoint to build a highway route from one city to another, based on the coordinates of the starting and ending cities. To really make this service complete, we would want it to eliminate any “orphan” highways returned (highways that aren’t on our expected route) and include any cities with stores that we may want to stop at on the way.
If we used the location_ids of Farley (B1643) and Rogersville (B5243), we should get output that looks like this:
curl -s -XGET http://127.0.0.1:8080/transportsvc/highways/from/B1643/to/B5243 \
-H 'Content-Type: application/json'
{"highways":[
{"highway_name":"610-W2",
"Highway_vector":{"values":[86.0,-263.0,94.0,-356.0]}},
{"highway_name":"54NW",
"highway_vector":{"values":[73.0,-456.0,200.0,-567.0]}},
{"highway_name":"610-W",
"highway_vector":{"values":[94.0,-356.0,73.0,-456.0]}}],
"citiesOnRoute":["Maplewood","Victoriaville"]}
Conclusions and Next Steps
These new transportation services should be a significant help to our drivers and DC management. They should now be getting mathematically-significant results for route determination between stores. A nice side benefit to this is that DC staff can also fill the truck more efficiently. With access to the route ahead of time, they can load pallets into the truck in a first-in-last-out (LIFO) approach, using more of the available space.
While this is a good first step, there are some future improvements that we could make, once this initiative is deemed successful. A subscription to a traffic service will help in the route planning and augmentation. This would allow a route recalculation based on significant local traffic events on one or more highways.
We could also use the n-vector approach for coordinate positioning, instead of using the abbreviated latitude and longitudinal coordinates. The advantage here is that our coordinates would already be converted to vectors, which would likely lead to more accurate nearest-neighbor approximations.
Published at DZone with permission of Aaron Ploetz. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments