How We Rebuilt a Legacy HBase + Elasticsearch System Using Apache Iceberg, Spark, Trino, and Doris
We replaced HBase + Elasticsearch with an Iceberg lakehouse, cutting cost and complexity while supporting analytics and near-real-time access.
Join the DZone community and get the full member experience.
Join For FreeBusiness Logic Description
We had an audit system that analyzed all entries into our platform and the specific actions performed inside the system. The main stakeholders were two groups:
- The data science team, which used this data as a foundation for building future machine learning models.
- Our customers, who wanted to run regular queries on the database to analyze their companies’ activity.
Because of these use cases, we needed a platform that could support both analytical workloads and near-real-time querying.
The Current Architecture and Its Problems
Our original technical stack was quite old. It was built around a monolithic Java service that received HTTP bulk requests and wrote data to HBase (our source of truth) and Elasticsearch. The queuing mechanism was based on the HDFS file system, where each service read messages from its own directory.
This architecture was:
- Expensive – due to the maintenance and infrastructure costs of HBase, Elasticsearch, and HDFS.
- Slow – with a complex and heavy monolith that was hard to scale efficiently.
- Hard to change – any modification to the business logic or any database issue could affect all APIs (both insert and search).
At the same time, we realized we did not need such a heavy and expensive architecture. The audit system was mainly used for analytical purposes in a near-real-time pipeline, where a delay of 2–3 minutes for data ingestion was acceptable. 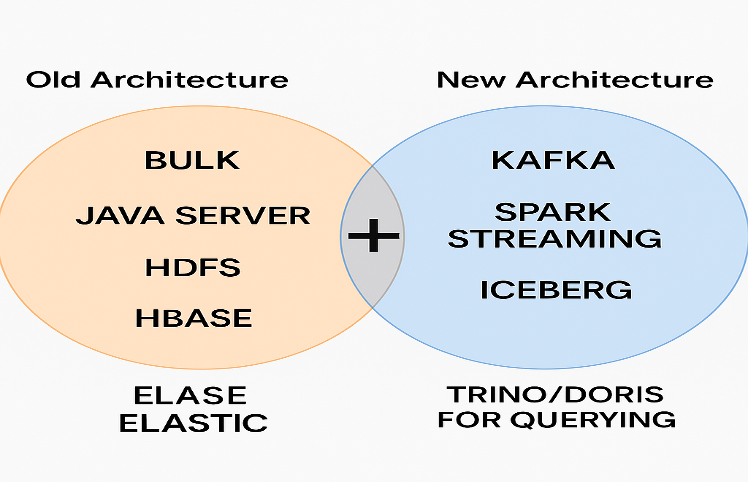
Lakehouse and Why We Chose Iceberg ![Data Lake vs. Data Warehouse Features]()
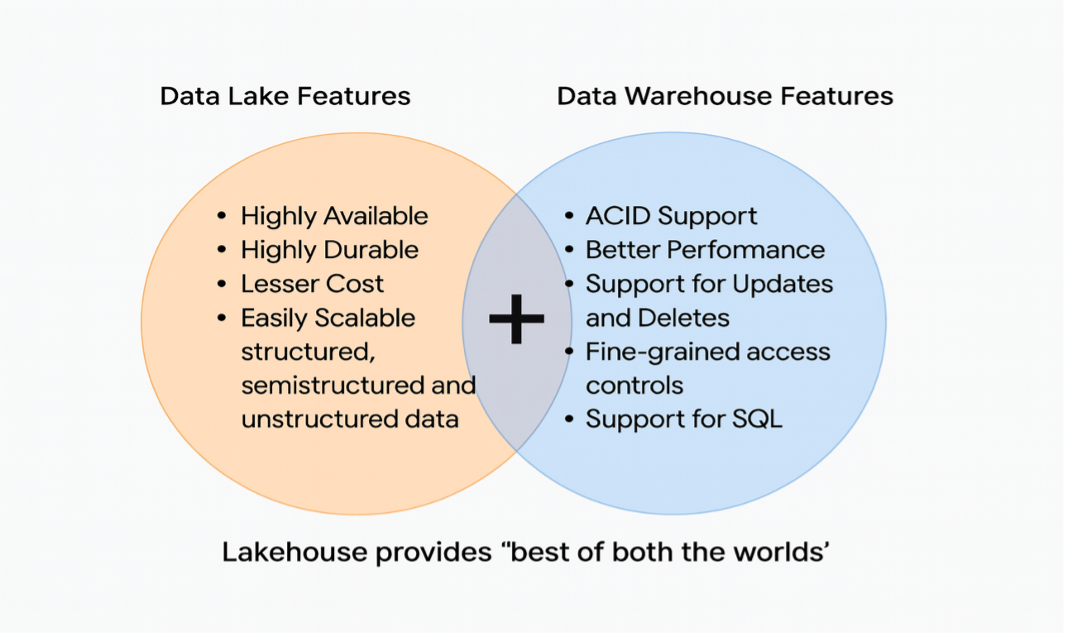
To modernize our platform, we decided to adopt a lakehouse architecture using Apache Iceberg as the table format and Parquet as the file format.
Like a data lake, a lakehouse uses cloud object storage such as Amazon S3, ADLS, or GCS and stores data in open file formats like Apache Parquet, Apache Avro, or Apache ORC. This cloud storage model gives the lakehouse all the main advantages of data lakes:
- High availability
- High durability
- Lower cost
- Scalability
- Support for structured, semi-structured, and unstructured data
- Support for AI/ML use cases
We chose Iceberg specifically because of several important features:
- ACID transactions. We needed strong guarantees because multiple Spark jobs can write to the same storage. Iceberg’s ACID support ensures consistency even with concurrent writers.
- Partition evolution. At the beginning, our queries always included
partnerId. Later, our business logic changed, and every query started including time as a key filter. Iceberg allowed us to evolve the partitioning scheme without rewriting the entire table and to do this “on the fly.” - Versioning and rollback. It was very important for us to be able to roll back to a previous version of a table in case of a bad deployment or data corruption. Iceberg’s snapshot and rollback mechanisms gave us this ability.
For file formats, after performance testing, we found that Parquet worked best for our business logic. It also provided better compression compared to Avro in our specific use cases.
Data Migration
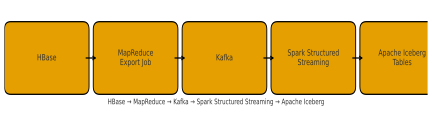
First, we needed to migrate data from HBase to our cloud storage. Due to a lack of time and resources, we used our existing MapReduce jobs on Hadoop to extract data from HBase. The diagram below describes our data migration process.
How We Implemented It and Why We Chose Spark
For data ingestion, we chose Apache Spark Structured Streaming. It offers:
- Good compatibility with Iceberg
- A convenient API
- Strong performance characteristics
To save costs, we used a pattern where Spark reads from Kafka, processes a micro-batch, writes the results to Iceberg, and then stops instead of running continuously. For orchestration, we used Airflow, which triggered our Spark job every five minutes to read data from Kafka.
Spark also provides good support for optimizing Iceberg tables, including file compaction and other maintenance operations that are important when working with Iceberg over time.
We did encounter several issues while tuning Spark and writing files:
- At one point, we configured a very large batch size for writes, which led to corrupted files. We fixed this by reducing the batch size and changing the
maxOffsetsPerTriggerflag. - We also needed to increase the number of Kafka partitions to improve Spark parallelism and fully utilize the cluster.
For implementation, we used PySpark, which allowed us to iterate quickly and integrate easily with other components in our environment.
Below is a simple PySpark code example:
schema_stream = StructType([StructField("user", StringType(), True), StructField("action", StringType(), True),StructField("ts", StringType(), True)])
stream = (spark.readStream.format("kafka")
.schema(schema_stream)
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "test").load())Trino: Its Disadvantages and Why We Moved to Doris
One of our main tasks was to find the best solution for querying data in cloud object storage. Our load was not extremely high, and we could allow up to two minutes per query. According to company policy, however, we had to maintain two separate clusters for the query engine to ensure high availability for our customers.
Our original idea was to give the secondary cluster minimal resources and use it only in emergency situations. We started with Trino as the main query engine. However, Trino did not provide the real-time search performance we expected for our specific workload.
This was probably related to how we used it. Trino is very good at combining data from multiple sources and performing federated analytical queries, but it is not always the best choice when you need very fast, real-time search on a single lakehouse source.
Because of this, we started looking for an alternative query engine that would better fit our needs. We evaluated two engines: StarRocks and Apache Doris. We tried to implement a StarRocks-based solution, but deployment and configuration took too much time, so we ultimately chose Apache Doris.
With Doris, we especially liked the caching mechanism, which gave us a noticeable performance boost for search queries—typically 2–3× faster in our tests. Doris also provides external table support, which we plan to use when migrating our higher-load systems.

Conclusion
Migrating from our old tech stack with HBase and Elasticsearch to a lakehouse architecture significantly reduced our costs and resource usage. When considering a move from a traditional stack to a lakehouse, it is very important to understand the final purpose of the system.
- If you have an analytical workload with low to medium query load, a lakehouse architecture is often the best choice.
- If you need extremely fast search with very high load, it may still be better to stay with a more traditional streaming architecture and specialized databases tuned for real-time queries.
It is also important to carefully choose the table format, file format, and query engine:
- For fast real-time search on lakehouse data, our preferred solution is Apache Doris (or StarRocks).
- For aggregating data from different sources and running federated analytical queries, Trino remains an excellent choice.
Our experience shows that combining a lakehouse built on Iceberg and Parquet with Spark for ingestion and Doris for querying can be a powerful and cost-effective alternative to a legacy HBase + Elasticsearch stack.
Opinions expressed by DZone contributors are their own.
Comments