I Trained a Machine Learning Model in Pure SQL
In this post, I’ll share how I trained a machine learning model in pure SQL on TiDB, an open-source distributed SQL database.
Join the DZone community and get the full member experience.
Join For FreeIn the article Deep Neural Network implemented in pure SQL over BigQuery, the author claimed to use pure SQL to implement a deep neural network model. But after I opened his repo, I found that he used Python to implement iterative training, which was not truly pure SQL.
In this post, I’ll share how I trained a machine learning model in pure SQL on TiDB, an open-source distributed SQL database. Major steps included:
- Choosing the Iris dataset
- Choosing the softmax logistic regression model for training
- Writing an SQL statement to implement model inference
- Training the model
In my test, I trained a softmax logistic regression model. During the test, I found that TiDB did not allow subqueries and aggregate functions in recursive common table expressions (CTEs). By modifying TiDB’s code, I bypassed the limitations and successfully trained a model, and got a 98% accuracy rate on the Iris dataset.
Why Did I Choose TiDB for Implementing the Machine Learning Model?
TiDB 5.1 has introduced many new features, including common table expressions (CTEs) of the ANSI SQL 99 standard. We can use a CTE as a statement for a temporary view to decouple a complex SQL statement and develop code more efficiently. What’s more, a recursive CTE can refer to itself. This is important for improving SQL functionality. Moreover, CTEs and window functions make SQL a Turing-complete language.
Because recursive CTEs can “iterate,” I wanted to try and see whether I could use pure SQL to implement machine learning model training and inference on TiDB.
The Iris Dataset
I chose the Iris dataset at scikit-learn. This data set contains 150 records of 3 types, each with 50 records. Each record has 4 features: sepal length (SL), sepal width (SW), petal length (PL), and petal width (PW). We can use these features to predict whether an iris belongs to iris-setosa, iris-versicolor, or iris-virginica.
After I downloaded the data in CSV format, I imported it into TiDB.
create table iris(sl float, sw float, pl float, pw float, type varchar(16));
LOAD DATA LOCAL INFILE 'iris.csv' INTO TABLE iris FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' ;
select * from iris limit 10;
+------+------+------+------+-------------+
| sl | sw | pl | pw | type |
+------+------+------+------+-------------+
| 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 4.9 | 3 | 1.4 | 0.2 | Iris-setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 5 | 3.6 | 1.4 | 0.2 | Iris-setosa |
| 5.4 | 3.9 | 1.7 | 0.4 | Iris-setosa |
| 4.6 | 3.4 | 1.4 | 0.3 | Iris-setosa |
| 5 | 3.4 | 1.5 | 0.2 | Iris-setosa |
| 4.4 | 2.9 | 1.4 | 0.2 | Iris-setosa |
| 4.9 | 3.1 | 1.5 | 0.1 | Iris-setosa |
+------+------+------+------+-------------+
10 rows in set (0.00 sec)
select type, count(*) from iris group by type;
+-----------------+----------+
| type | count(*) |
+-----------------+----------+
| Iris-versicolor | 50 |
| Iris-setosa | 50 |
| Iris-virginica | 50 |
+-----------------+----------+
3 rows in set (0.00 sec)Softmax Logistic Regression
I chose a simple machine learning model: softmax logistic regression for multi-class classification. In softmax regression, the probability of classifying x into category y is:
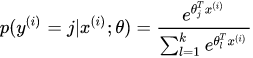
The cost function is:
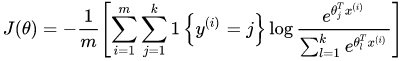
The gradient is:
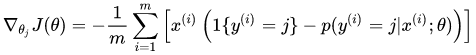
Therefore, we can use gradient descent to upgrade gradient:
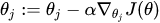
Model Inference
I wrote an SQL statement to implement inference. Based on the model and data defined above, the input data x had five dimensions (SL, SW, PL, PW, and a constant 1.0). The output used one-hot encoding.
create table data(
x0 decimal(35, 30), x1 decimal(35, 30), x2 decimal(35, 30), x3 decimal(35, 30), x4 decimal(35, 30),
y0 decimal(35, 30), y1 decimal(35, 30), y2 decimal(35, 30)
);
insert into data
select
sl, sw, pl, pw, 1.0,
case when type='Iris-setosa'then 1 else 0 end,
case when type='Iris-versicolor'then 1 else 0 end,
case when type='Iris-virginica'then 1 else 0 end
from iris;There were 15 parameters: 3 types * 5 dimensions.
create table weight(
w00 decimal(35, 30), w01 decimal(35, 30), w02 decimal(35, 30), w03 decimal(35, 30), w04 decimal(35, 30),
w10 decimal(35, 30), w11 decimal(35, 30), w12 decimal(35, 30), w13 decimal(35, 30), w14 decimal(35, 30),
w20 decimal(35, 30), w21 decimal(35, 30), w22 decimal(35, 30), w23 decimal(35, 30), w24 decimal(35, 30));I initialized the input data to 0.1, 0.2, 0.3. I used different numbers for the convenience of demonstration. Initializing all of them to 0.1 is OK.
insert into weight values (
0.1, 0.1, 0.1, 0.1, 0.1,
0.2, 0.2, 0.2, 0.2, 0.2,
0.3, 0.3, 0.3, 0.3, 0.3);Next, I wrote a SQL statement to count the result accuracy for data inference. For better understanding, I used pseudo code to describe this process:
weight = (
w00, w01, w02, w03, w04,
w10, w11, w12, w13, w14,
w20, w21, w22, w23, w24
)
for data(x0, x1, x2, x3, x4, y0, y1, y2) in all Data:
exp0 = exp(x0 * w00, x1 * w01, x2 * w02, x3 * w03, x4 * w04)
exp1 = exp(x0 * w10, x1 * w11, x2 * w12, x3 * w13, x4 * w14)
exp2 = exp(x0 * w20, x1 * w21, x2 * w22, x3 * w23, x4 * w24)
sum_exp = exp0 + exp1 + exp2
// softmax
p0 = exp0 / sum_exp
p1 = exp1 / sum_exp
p2 = exp2 / sum_exp
// inference result
r0 = p0 > p1 and p0 > p2
r1 = p1 > p0 and p1 > p2
r2 = p2 > p0 and p2 > p1
data.correct = (y0 == r0 and y1 == r1 and y2 == r2)
return sum(Data.correct) / count(Data)In the code above, I calculated elements in each row of the data. To make a sample’s inference:
- I got the EXP of the weighted vectors.
- I got the softmax value.
- I chose the largest of p0, p1, and p2 as 1; I set the rest to 0.
If the inference result of a sample is consistent with its original classification, it is a correct prediction. Then, I summed the correct numbers of all samples to get the final accuracy rate.
The following code shows the implementation of the SQL statement. I joined each row of data with a weight (only one row of data), calculated the inference result of each row, and summed the correct numbers of samples:
select sum(y0 = r0 and y1 = r1 and y2 = r2) / count(*)
from
(select
y0, y1, y2,
p0 > p1 and p0 > p2 as r0, p1 > p0 and p1 > p2 as r1, p2 > p0 and p2 > p1 as r2
from
(select
y0, y1, y2,
e0/(e0+e1+e2) as p0, e1/(e0+e1+e2) as p1, e2/(e0+e1+e2) as p2
from
(select
y0, y1, y2,
exp(
w00 * x0 + w01 * x1 + w02 * x2 + w03 * x3 + w04 * x4
) as e0,
exp(
w10 * x0 + w11 * x1 + w12 * x2 + w13 * x3 + w14 * x4
) as e1,
exp(
w20 * x0 + w21 * x1 + w22 * x2 + w23 * x3 + w24 * x4
) as e2
from data, weight) t1
)t2
)t3;The SQL statement above almost implements the calculation process of the pseudo-code step by step. I got the result:
+-----------------------------------------------+
| sum(y0 = r0 and y1 = r1 and y2 = r2)/count(*) |
+-----------------------------------------------+
| 0.3333 |
+-----------------------------------------------+
1 row in set (0.01 sec)Next, I’ll learn the model parameters.
Model Training
Note: To simplify the problem, I did not consider the “training set” and “validation set” issues, and I used all the data only for training.
I wrote pseudo-code and then wrote a SQL statement based on it:
weight = (
w00, w01, w02, w03, w04,
w10, w11, w12, w13, w14,
w20, w21, w22, w23, w24
)
for iter in iterations:
sum00 = 0
sum01 = 0
...
sum23 = 0
sum24 = 0
for data(x0, x1, x2, x3, x4, y0, y1, y2) in all Data:
exp0 = exp(x0 * w00, x1 * w01, x2 * w02, x3 * w03, x4 * w04)
exp1 = exp(x0 * w10, x1 * w11, x2 * w12, x3 * w13, x4 * w14)
exp2 = exp(x0 * w20, x1 * w21, x2 * w22, x3 * w23, x4 * w24)
sum_exp = exp0 + exp1 + exp2
// softmax
p0 = y0 - exp0 / sum_exp
p1 = y1 - exp1 / sum_exp
p2 = y2 - exp2 / sum_exp
sum00 += p0 * x0
sum01 += p0 * x1
sum02 += p0 * x2
...
sum23 += p2 * x3
sum24 += p2 * x4
w00 = w00 + learning_rate * sum00 / Data.size
w01 = w01 + learning_rate * sum01 / Data.size
...
w23 = w23 + learning_rate * sum23 / Data.size
w24 = w24 + learning_rate * sum24 / Data.sizeBecause I manually expanded the sum and w vectors, this code looked a little cumbersome. Then, I started to write SQL training. First, I wrote an SQL statement with only one iteration.
I set the learning rate and the number of samples:
set @lr = 0.1;
Query OK, 0 rows affected (0.00 sec)
set @dsize = 150;
Query OK, 0 rows affected (0.00 sec)The code iterated once:
select
w00 + @lr * sum(d00) / @dsize as w00, w01 + @lr * sum(d01) / @dsize as w01, w02 + @lr * sum(d02) / @dsize as w02, w03 + @lr * sum(d03) / @dsize as w03, w04 + @lr * sum(d04) / @dsize as w04 ,
w10 + @lr * sum(d10) / @dsize as w10, w11 + @lr * sum(d11) / @dsize as w11, w12 + @lr * sum(d12) / @dsize as w12, w13 + @lr * sum(d13) / @dsize as w13, w14 + @lr * sum(d14) / @dsize as w14,
w20 + @lr * sum(d20) / @dsize as w20, w21 + @lr * sum(d21) / @dsize as w21, w22 + @lr * sum(d22) / @dsize as w22, w23 + @lr * sum(d23) / @dsize as w23, w24 + @lr * sum(d24) / @dsize as w24
from
(select
w00, w01, w02, w03, w04,
w10, w11, w12, w13, w14,
w20, w21, w22, w23, w24,
p0 * x0 as d00, p0 * x1 as d01, p0 * x2 as d02, p0 * x3 as d03, p0 * x4 as d04,
p1 * x0 as d10, p1 * x1 as d11, p1 * x2 as d12, p1 * x3 as d13, p1 * x4 as d14,
p2 * x0 as d20, p2 * x1 as d21, p2 * x2 as d22, p2 * x3 as d23, p2 * x4 as d24
from
(select
w00, w01, w02, w03, w04,
w10, w11, w12, w13, w14,
w20, w21, w22, w23, w24,
x0, x1, x2, x3, x4,
y0 - e0/(e0+e1+e2) as p0, y1 - e1/(e0+e1+e2) as p1, y2 - e2/(e0+e1+e2) as p2
from
(select
w00, w01, w02, w03, w04,
w10, w11, w12, w13, w14,
w20, w21, w22, w23, w24,
x0, x1, x2, x3, x4, y0, y1, y2,
exp(
w00 * x0 + w01 * x1 + w02 * x2 + w03 * x3 + w04 * x4
) as e0,
exp(
w10 * x0 + w11 * x1 + w12 * x2 + w13 * x3 + w14 * x4
) as e1,
exp(
w20 * x0 + w21 * x1 + w22 * x2 + w23 * x3 + w24 * x4
) as e2
from data, weight) t1
)t2
)t3;The result was model parameters after one iteration:
+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+
| w00 | w01 | w02 | w03 | w04 | w10 | w11 | w12 | w13 | w14 | w20 | w21 | w22 | w23 | w24 |
+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+
| 0.242000022455130986666666666667 | 0.199736070114635900000000000000 | 0.135689102774125773333333333333 | 0.104372938417325687333333333333 | 0.128775320011717430666666666667 | 0.296128284590438133333333333333 | 0.237124925707748246666666666667 | 0.281477497498236260000000000000 | 0.225631554555397960000000000000 | 0.215390025342499213333333333333 | 0.061871692954430866666666666667 | 0.163139004177615846666666666667 | 0.182833399727637980000000000000 | 0.269995507027276353333333333333 | 0.255834654645783353333333333333 |
+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+----------------------------------+
1 row in set (0.03 sec)The following is the core part. I used recursive CTEs for iterative training:
set @num_iterations = 1000;
Query OK, 0 rows affected (0.00 sec)The core idea is that the input of each iteration was the result of the previous iteration, and I added an incremental iteration variable to control the number of iterations. The general framework was:
with recursive cte(iter, weight) as
(
select 1, init_weight
union all
select iter+1, new_weight
from cte
where ites < @num_iterationsNext, I combined the SQL statement of an iteration with this iteration framework. To improve the calculation accuracy, I added type conversions to the intermediate results:
with recursive weight( iter,
w00, w01, w02, w03, w04,
w10, w11, w12, w13, w14,
w20, w21, w22, w23, w24) as
(
select 1,
cast(0.1 as DECIMAL(35, 30)), cast(0.1 as DECIMAL(35, 30)), cast (0.1 as DECIMAL(35, 30)), cast(0.1 as DECIMAL(35, 30)), cast(0.1 as DECIMAL(35, 30)),
cast(0.1 as DECIMAL(35, 30)), cast(0.1 as DECIMAL(35, 30)), cast(0.1 as DECIMAL(35, 30)), cast(0.1 as DECIMAL(35, 30)), cast(0.1 as DECIMAL(35, 30)),
cast(0.1 as DECIMAL(35, 30)), cast(0.1 as DECIMAL(35, 30)), cast(0.1 as DECIMAL(35, 30)), cast(0.1 as DECIMAL(35, 30)), cast(0.1 as DECIMAL(35, 30))
union all
select
iter + 1,
w00 + @lr * cast(sum(d00) as DECIMAL(35, 30)) / @dsize as w00, w01 + @lr * cast(sum(d01) as DECIMAL(35, 30)) / @dsize as w01, w02 + @lr * cast(sum(d02) as DECIMAL(35, 30)) / @dsize as w02, w03 + @lr * cast(sum(d03) as DECIMAL(35, 30)) / @dsize as w03, w04 + @lr * cast(sum(d04) as DECIMAL(35, 30)) / @dsize as w04 ,
w10 + @lr * cast(sum(d10) as DECIMAL(35, 30)) / @dsize as w10, w11 + @lr * cast(sum(d11) as DECIMAL(35, 30)) / @dsize as w11, w12 + @lr * cast(sum(d12) as DECIMAL(35, 30)) / @dsize as w12, w13 + @lr * cast(sum(d13) as DECIMAL(35, 30)) / @dsize as w13, w14 + @lr * cast(sum(d14) as DECIMAL(35, 30)) / @dsize as w14,
w20 + @lr * cast(sum(d20) as DECIMAL(35, 30)) / @dsize as w20, w21 + @lr * cast(sum(d21) as DECIMAL(35, 30)) / @dsize as w21, w22 + @lr * cast(sum(d22) as DECIMAL(35, 30)) / @dsize as w22, w23 + @lr * cast(sum(d23) as DECIMAL(35, 30)) / @dsize as w23, w24 + @lr * cast(sum(d24) as DECIMAL(35, 30)) / @dsize as w24
from
(select
iter, w00, w01, w02, w03, w04,
w10, w11, w12, w13, w14,
w20, w21, w22, w23, w24,
p0 * x0 as d00, p0 * x1 as d01, p0 * x2 as d02, p0 * x3 as d03, p0 * x4 as d04,
p1 * x0 as d10, p1 * x1 as d11, p1 * x2 as d12, p1 * x3 as d13, p1 * x4 as d14,
p2 * x0 as d20, p2 * x1 as d21, p2 * x2 as d22, p2 * x3 as d23, p2 * x4 as d24
from
(select
iter, w00, w01, w02, w03, w04,
w10, w11, w12, w13, w14,
w20, w21, w22, w23, w24,
x0, x1, x2, x3, x4,
y0 - e0/(e0+e1+e2) as p0, y1 - e1/(e0+e1+e2) as p1, y2 - e2/(e0+e1+e2) as p2
from
(select
iter, w00, w01, w02, w03, w04,
w10, w11, w12, w13, w14,
w20, w21, w22, w23, w24,
x0, x1, x2, x3, x4, y0, y1, y2,
exp(
w00 * x0 + w01 * x1 + w02 * x2 + w03 * x3 + w04 * x4
) as e0,
exp(
w10 * x0 + w11 * x1 + w12 * x2 + w13 * x3 + w14 * x4
) as e1,
exp(
w20 * x0 + w21 * x1 + w22 * x2 + w23 * x3 + w24 * x4
) as e2
from data, weight where iter < @num_iterations) t1
)t2
)t3
having count(*) > 0
)
select * from weight where iter = @num_iterations;There were two differences between this code block and the code block with one iteration above. In this code block:
- After
data join weight, I addedwhere iter <@num_iterationsto control the number of iterations and theiter + 1 as itercolumn to the output. - I added
having count(*)> 0to prevent the aggregation from outputting data when there was no input data at the end. This error might cause the iteration to fail to end.
The result was:
ERROR 3577 (HY000): In recursive query block of Recursive Common Table Expression 'weight', the recursive table must be referenced only once, and not in any subqueryThis showed that recursive CTEs did not allow subqueries in the recursive part. But I could merge all the subqueries above. After I merged them manually, I got this:
ERROR 3575 (HY000): Recursive Common Table Expression 'cte' can contain neither aggregation nor window functions in recursive query blockIt showed that aggregate functions were not allowed.
Then, I decided to change TiDB’s implementation.
According to the introduction in the proposal, the implementation of recursive CTEs followed the basic execution framework of TiDB. After I consulted Wenjun Huang, an R and D at PingCAP, I learned that there were two reasons why subqueries and aggregate functions were not allowed:
- MySQL did not allow them.
- If allowed, there would be a lot of complicated corner cases.
But I just wanted to test the features. I deleted the check of subqueries and aggregate functions temporarily in diff.
I executed the code again:
+------+----------------------------------+----------------------------------+-----------------------------------+-----------------------------------+----------------------------------+----------------------------------+-----------------------------------+-----------------------------------+-----------------------------------+----------------------------------+-----------------------------------+-----------------------------------+----------------------------------+----------------------------------+-----------------------------------+
| iter | w00 | w01 | w02 | w03 | w04 | w10 | w11 | w12 | w13 | w14 | w20 | w21 | w22 | w23 | w24 |
+------+----------------------------------+----------------------------------+-----------------------------------+-----------------------------------+----------------------------------+----------------------------------+-----------------------------------+-----------------------------------+-----------------------------------+----------------------------------+-----------------------------------+-----------------------------------+----------------------------------+----------------------------------+-----------------------------------+
| 1000 | 0.988746701341992382020000000002 | 2.154387045383744124308666666676 | -2.717791657467537500866666666671 | -1.219905459264249309799999999999 | 0.523764101056271250025665250523 | 0.822804724410132626693333333336 | -0.100577045244777709968533333327 | -0.033359805866941626546666666669 | -1.046591158370568595420000000005 | 0.757865074561280001352887284083 | -1.511551425752124944953333333333 | -1.753810000138966371560000000008 | 3.051151463334479351666666666650 | 2.566496617634817948266666666655 | -0.981629175617551201349829226980 |
+------+----------------------------------+----------------------------------+-----------------------------------+-----------------------------------+----------------------------------+----------------------------------+-----------------------------------+-----------------------------------+-----------------------------------+----------------------------------+-----------------------------------+-----------------------------------+----------------------------------+----------------------------------+-----------------------------------+It was a success! I got the parameters after 1,000 iterations.
Next, I used the new parameters to recalculate the correct rate:
+-------------------------------------------------+
| sum(y0 = r0 and y1 = r1 and y2 = r2) / count(*) |
+-------------------------------------------------+
| 0.9867 |
+-------------------------------------------------+
1 row in set (0.02 sec)This time, the accuracy rate reached 98%.
Conclusion
By using recursive CTEs in TiDB 5.1, I successfully used pure SQL to train a softmax logistic regression model on TiDB.
During the test, I found that TiDB’s recursive CTEs did not allow subqueries and aggregate functions, so I modified TiDB’s code to bypass these limitations. Finally, I successfully trained a model and obtained a 98% accuracy rate on the Iris dataset.
My work also uncovered a couple of ideas:
- After I did some tests, I found that neither PostgreSQL nor MySQL supported aggregate functions in recursive CTEs. There might be corner cases that were difficult to handle.
- In this test, I manually expanded all dimensions of the vectors. In fact, I also wrote an implementation that did not need to expand all dimensions. For example, the schema of the data table was (idx, dim, value), but in this implementation, the weight table needed to be joined twice. This means that it needed to be accessed twice in the CTE. This also required modification of the implementation of the TiDB executor. Therefore, I didn’t talk about it in this article. But in fact, this implementation was more general, which could handle models with more dimensions, for example, the MNIST dataset.
Published at DZone with permission of Mingcong Han. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments