IBM App Connect Operators
What is an Operator and why did we create one for IBM App Connect?
Join the DZone community and get the full member experience.
Join For FreeIf you’re relatively new to Kubernetes, or not entirely sure what an Operator is, and why IBM created one for IBM App Connect, this post is for you.
You do not have to use the Operator to use IBM App Connect in containers. However, we aim to show how the Operator significantly simplifies Kubernetes deployment.
Let’s begin by exploring what it takes to deploy a component to Kubernetes, and then we’ll look at what part an Operator can play in reducing complexity.
Kubernetes Complexity
Deploying a simple application in a container to Kubernetes requires quite a lot of knowledge about the underlying Kubernetes constructs. Let’s say for instance, that we wanted to simply deploy an integration flow, in an IBM App Connect integration server, in a container in Kubernetes. We do provide a pre-built “certified container” in the IBM Container Registry, so that’s part of the work done, but where do you go from here?
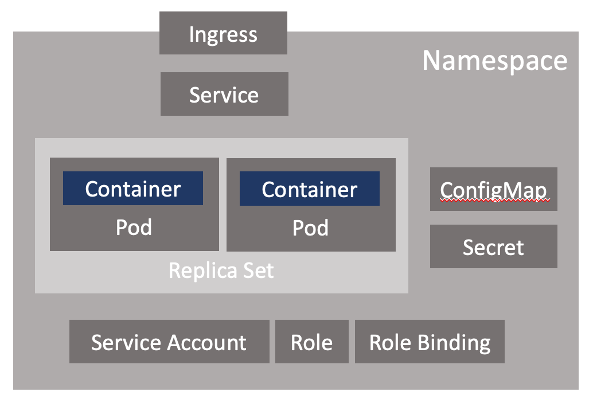
For a start, you don’t just deploy a container at all, but instead define a “Pod” that has containers within it. Furthermore, you can’t simply deploy a Pod, you have to wrap it in a construct that describes how you want it deployed, including things such as replication policy. Depending on how your container works this wrapper might be a “Deployment”, “ReplicaSet”, or “StatefulSet”. If you want other containers to be able to access your container you need to also create a “Service”, and possibly an “Ingress” too if you want it to be exposed beyond the cluster.
We could go on, but you get the idea that even the simplest deployment of an integration in a container on Kubernetes, requires quite a lot of Kubernetes knowledge. You need to know how to define, deploy and maintain all these low-level objects.
Helm Charts
Since a given type of container deployment will typically need the same set of complementary objects, the first technology commonly used to simplify Kubernetes deployments was Helm.
Helm is a piece of software that made it easy to provide templates for all the objects you needed. You could then simply provide a file containing values for the few things that changed per deployment, such as the name of your application, the container image it needed to be built from, and perhaps its replication policy. The templates would then be merged with the values resulting in the correctly populated set of objects required to deploy your application to Kubernetes. This was the initial approach we took for IBM App Connect, and you can of course still use Helm Charts to deploy integration servers should you want to.
However, Helm only gets us so far. It’s good for the initial deployment of something like an Integration Server, and it can achieve basic updates, but what about setting up monitoring and continuous health checking of the environment? How will it maintain and upgrade our integrations and the associated runtimes once deployed, and other lifecycle issues such as storage management? What about managing the more complex, multi-container installations of things like the Designer Authoring capability?
The Operator Pattern
Subsequently, an alternative mechanism for simplifying the deployment of an application emerged, known as the “operator pattern”. This is in fact the pattern used behind all the native Kubernetes objects themselves, but it is possible to extend the Kubernetes such that you can work with your own custom objects too via the standard Kubernetes API. You provide to the API a file describing the state you would like your application to reach, and the Operator works out how to turn that into all the underlying Kubernetes objects required.
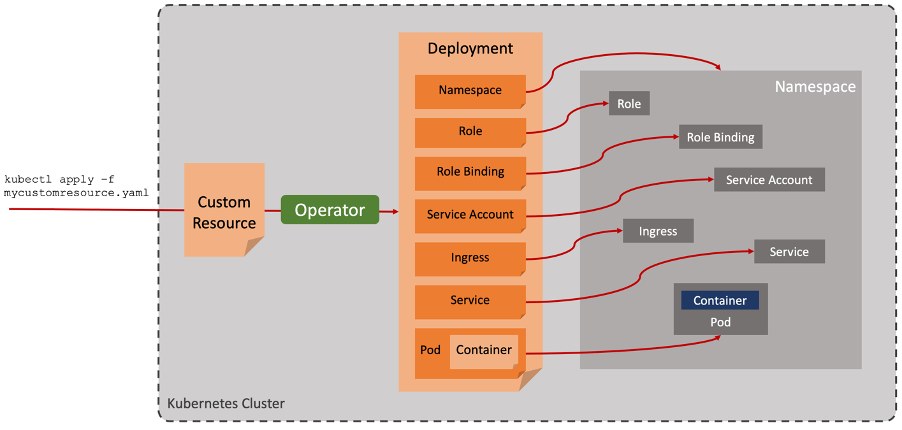
This means that in the same way we can create and manipulate native Kubernetes objects such as ReplicaSets, and Services, we can use the same “kubectl” commands to deploy and manage our own custom objects. In fact, if you think about it, it’s operators all the way down! Our operator will mostly be creating Kubernetes native objects, which in turn will invoke their controllers and so on.
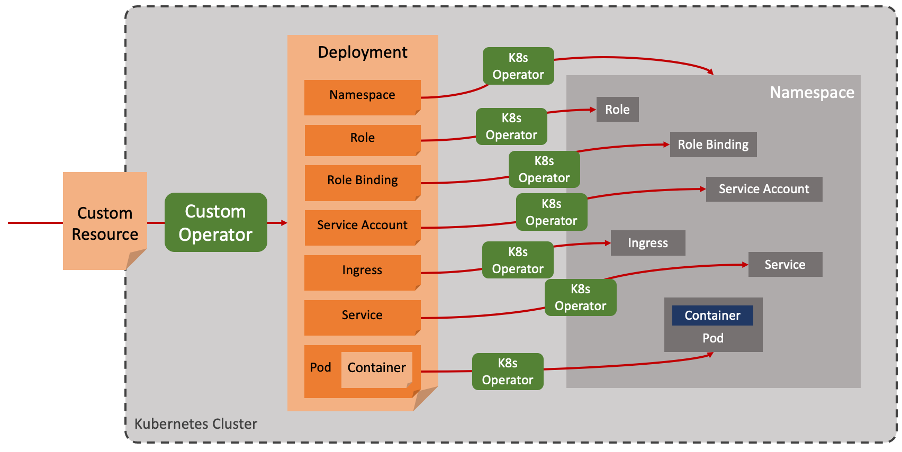
The Operator then performs all the necessary work to bring that application to life and keep it running. An Operator is a running component, written in code (typically Go, but there are alternatives). It can be made to do essentially anything required by the application - install it, upgrade it, monitor it, and so on. The name “operator” comes from the idea that it will do all the work that a manual operator would otherwise have had to do. It is, if you like, a digital operator. To quote from the Operator Framework home page
“The goal of an Operator is to put operational knowledge into software”.
For a slightly deeper but still very approachable perspective on the Operator Pattern, it is certainly worth checking out Andre Tost’s summary of Kubernetes Operators and his subsequent post on Making the Case for Kubernetes Operators.
Reinforcing the “Declarative” Pattern
One of the most powerful underlying principles of the way that Kubernetes works is its declarative deployment model. The idea is that you tell Kubernetes what you would like the world to look like, and it sets about doing it. You give it high-level instructions like “make this application highly available” (provide multiple replicas), “make it resilient” (spread the replicas across data centres) and Kubernetes works out how to make that happen. It also keeps monitoring the current state to ensure those requirements continue to be met, for example, recycling and moving containers if necessary and ensuring continued load balancing across them wherever they are.
This is an extremely powerful abstraction, enabling those deploying things to Kubernetes to stay focused on the business value of their applications rather than getting tied up in the operational nuances.
We really want to bring that same benefit to the deployment of integrations on Kubernetes, too. We want to be able to simply instruct Kubernetes to create an integration, give it minimum requirements, and let it get on with it. Creating custom Operators for our integration capabilities is the best approach to achieving this currently and is completely in line with the way the underlying Kubernetes platform works.
Operators in Cloud Pak for Integration
An Operator is typically targeted at looking after a specific capability. Early examples of customer operators were those for etcd and Prometheus to enable the creation and administration of an etcd datastore or an instance of Prometheus monitoring. We have created Operators for each of the capabilities in the Cloud Pak for Integration. There are Operators for API management (IBM API Connect), Kafka (IBM Event Streams), and messaging (IBM MQ). It is the one for application integration (IBM App Connect) that we will discuss in this post.
The existence of these Operators means any of the integration capabilities can be created using standard Kubernetes commands. For example, the creation of an integration server is (almost) as simple as:
kubectl apply -f my-integration.yaml
Where the my-integration.yaml file contains just the minimal information needed in order to specify the requirements. Essentially just its name, the BAR file to include, the version of the IBM App Connect runtime to run it on, some CPU/memory requirements, and a replication policy. The Operator locates and downloads the appropriate image, links it to the BAR file, pulls in any relevant configuration, and starts it up. You don’t need a detailed knowledge of all the underlying Kubernetes objects required, the Operator handles all that for you.
For an example of what it looks like to deploy an integration server using the IBM App Connect Operator, take a look at a previous article.
What Does the IBM App Connect Operator Do?
Operators are designed to create and manage specific types of resources on the Kubernetes platform. The IBM App Connect Operator looks after the following resource types:
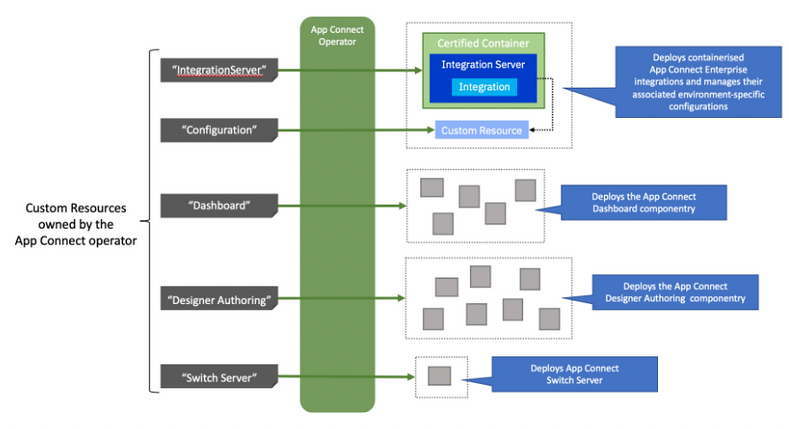
- IntegrationServer: For creating instances of an IBM App Connect integration server in a container to run integrations created using the IBM App Connect “Toolkit”. Many separate IntegrationServer resources may be deployed onto the Kubernetes platform, each containing perhaps just a handful of integrations.
- Configuration: For storing important configuration information required by integrations. Each integration may have a number of different configuration object types such as for an odbc.ini file for connecting to a database, or an MQ policy file for connecting to IBM MQ. There may be several versions of each configuration containing details required for each environment (development, test, production, etc.).
- Dashboard: For creating an instance of the App Connect “Dashboard” for viewing and administering integrations. The Dashboard capability is shared, so it is typically instantiated once and then used by many users to administer IntegrationServer resources.
- SwitchServer: For creating an instance of an IBM App Connect “Switch Server” that is sometimes required for hybrid integrations
- Trace: Allows you to enable and administer trace for IntegrationServers.
- DesignerAuthoring: For creating an instance the infrastructure required for creating and running web-authored integrations using IBM App Connect “Designer”. The DesignerAuthoring capability is shared, so it is typically instantiated once and then used by many users to perform web-based authoring of integrations.
In summary, the IBM App Connect operator makes it easy to instantiate integration-related capabilities on a Kubernetes environment by providing a definition file and applying it using a standard Kubernetes command. This reduces the learning curve when moving to containers, and significantly simplifies the automation of integration deployment such as the preparation of CI/CD pipelines, and the administration of environment-specific parameters.
Acknowledgement and thanks to Kim Clark and Ben Thompson for providing valuable input to this article.
Published at DZone with permission of Rob Convery. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments