Implementing RAG: How To Write a Graph Retrieval Query in LangChain
We will look at how LangChain implements RAG so you can apply the same principles to any application with LangChain and an LLM.
Join the DZone community and get the full member experience.
Join For FreeDocumentation abounds for any topic or questions you might have, but when you try to apply something to your own uses, it suddenly becomes hard to find what you need. This problem doesn't only exist for you.
In this blog post, we will look at how LangChain implements RAG so that you can apply the same principles to any application with LangChain and an LLM.
What Is RAG?
This term is used a lot in today's technical landscape, but what does it actually mean? Here are a few definitions from various sources:
- "Retrieval-Augmented Generation (RAG) is the process of optimizing the output of a large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response." — Amazon Web Services
- "Retrieval-augmented generation (RAG) is a technique for enhancing the accuracy and reliability of generative AI models with facts fetched from external sources." — NVIDIA
- "Retrieval-augmented generation (RAG) is an AI framework for improving the quality of LLM-generated responses by grounding the model on external sources of knowledge to supplement the LLM's internal representation of information." — IBM Research
In this blog post, we'll be focusing on how to write the retrieval query that supplements or grounds the LLM's answer. We will use Python with LangChain, a framework used to write generative AI applications that interact with LLMs.
The Data Set
First, let's take a quick look at our data set. We'll be working with the SEC (Securities and Exchange Commission) filings from the EDGAR (Electronic Data Gathering, Analysis, and Retrieval system) database. The SEC filings are a treasure trove of information, containing financial statements, disclosures, and other important information about publicly-traded companies.
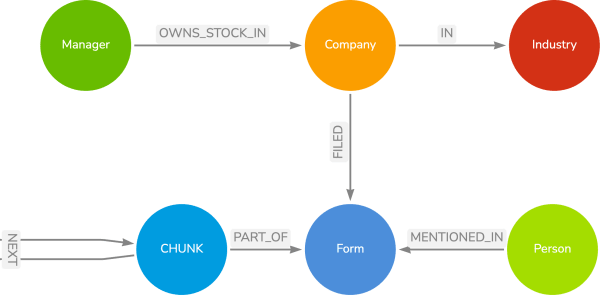
The data contains companies who have filed financial forms (10k, 13, etc.) with the SEC. Different managers own stock in these companies, and the companies are part of different industries. In the financial forms themselves, various people are mentioned in the text, and we have broken the text down into smaller chunks for the vector search queries to handle. We have taken each chunk of text in a form and created a vector embedding that is also stored on the CHUNK node. When we run a vector search query, we will compare the vector of the query to the vector of the CHUNK nodes to find the most similar text.
Let's see how to construct our query!
Retrieval Query Examples
I used a few sources to help me understand how to write a retrieval query in LangChain. The first was a blog post by Tomaz Bratanic, who wrote a post on how to work with the Neo4j vector index in LangChain using Wikipedia article data. The second was a query from the GenAI Stack, which is a collection of demo applications built with Docker and utilizes the StackOverflow data set containing technical questions and answers.
Both queries are included below.
# Tomaz's blog post retrieval query
retrieval_query = """
OPTIONAL MATCH (node)<-[:EDITED_BY]-(p)
WITH node, score, collect(p) AS editors
RETURN node.info AS text,
score,
node {.*, vector: Null, info: Null, editors: editors} AS metadata
"""
# GenAI Stack retrieval query
retrieval_query="""
WITH node AS question, score AS similarity
CALL { with question
MATCH (question)<-[:ANSWERS]-(answer)
WITH answer
ORDER BY answer.is_accepted DESC, answer.score DESC
WITH collect(answer)[..2] as answers
RETURN reduce(str='', answer IN answers | str +
'\n### Answer (Accepted: '+ answer.is_accepted +
' Score: ' + answer.score+ '): '+ answer.body + '\n') as answerTexts
}
RETURN '##Question: ' + question.title + '\n' + question.body + '\n'
+ answerTexts AS text, similarity as score, {source: question.link} AS metadata
ORDER BY similarity ASC // so that best answers are the last
"""Now, notice that these queries do not look complete. We wouldn't start a Cypher query with an OPTIONAL MATCH or WITH clause. This is because the retrieval query is added on to the end of the vector search query. Tomaz's post shows us the implementation of the vector search query.
read_query = (
"CALL db.index.vector.queryNodes($index, $k, $embedding) "
"YIELD node, score "
) + retrieval_querySo LangChain first calls the db.index.vector.queryNodes() procedure (more info in documentation) to find the most similar nodes and passes (YIELD) the similar node and the similarity score, and then it adds the retrieval query to the end of the vector search query to pull additional context. This is very helpful to know, especially as we construct the retrieval query, and for when we start testing results!
The second thing to note is that both queries return the same three variables: text, score, and metadata. This is what LangChain expects, so you will get errors if those are not returned. The text variable contains the related text, the score is the similarity score for the chunk against the search text, and the metadata can contain any additional information that we want for context.
Constructing the Retrieval Query
Let's build our retrieval query! We know the similarity search query will return the node and score variables, so we can pass those into our retrieval query to pull connected data of those similar nodes. We also have to return the text, score, and metadata variables.
retrieval_query = """
WITH node AS doc, score as similarity
# some more query here
RETURN <something> as text, similarity as score,
{<something>: <something>} AS metadata
"""Ok, there's our skeleton. Now what do we want in the middle? We know our data model will pull CHUNK nodes in the similarity search (those will be the node AS doc values in our WITH clause above). Chunks of text don't give a lot of context, so we want to pull in the Form, Person, Company, Manager, and Industry nodes that are connected to the CHUNK nodes. We also include a sequence of text chunks on the NEXT relationship, so we can pull the next and previous chunks of text around a similar one. We also will pull all the chunks with their similarity scores, and we want to narrow that down a bit...maybe just the top 5 most similar chunks.
retrieval_query = """
WITH node AS doc, score as similarity
ORDER BY similarity DESC LIMIT 5
CALL { WITH doc
OPTIONAL MATCH (prevDoc:Chunk)-[:NEXT]->(doc)
OPTIONAL MATCH (doc)-[:NEXT]->(nextDoc:Chunk)
RETURN prevDoc, doc AS result, nextDoc
}
# some more query here
RETURN coalesce(prevDoc.text,'') + coalesce(document.text,'') + coalesce(nextDoc.text,'') as text,
similarity as score,
{<something>: <something>} AS metadata
"""Now we keep the 5 most similar chunks, then pull the previous and next chunks of text in the CALL {} subquery. We also change the RETURN to concatenate the text of the previous, current, and next chunks all into text variable. The coalesce() function is used to handle null values, so if there is no previous or next chunk, it will just return an empty string.
Let's add a bit more context to pull in the other related entities in the graph.
retrieval_query = """
WITH node AS doc, score as similarity
ORDER BY similarity DESC LIMIT 5
CALL { WITH doc
OPTIONAL MATCH (prevDoc:Chunk)-[:NEXT]->(doc)
OPTIONAL MATCH (doc)-[:NEXT]->(nextDoc:Chunk)
RETURN prevDoc, doc AS result, nextDoc
}
WITH result, prevDoc, nextDoc, similarity
CALL {
WITH result
OPTIONAL MATCH (result)-[:PART_OF]->(:Form)<-[:FILED]-(company:Company), (company)<-[:OWNS_STOCK_IN]-(manager:Manager)
WITH result, company.name as companyName, apoc.text.join(collect(manager.managerName),';') as managers
WHERE companyName IS NOT NULL OR managers > ""
WITH result, companyName, managers
ORDER BY result.score DESC
RETURN result as document, result.score as popularity, companyName, managers
}
RETURN coalesce(prevDoc.text,'') + coalesce(document.text,'') + coalesce(nextDoc.text,'') as text,
similarity as score,
{documentId: coalesce(document.chunkId,''), company: coalesce(companyName,''), managers: coalesce(managers,''), source: document.source} AS metadata
"""The second CALL {} subquery pulls in any related Form, Company, and Manager nodes (if they exist, OPTIONAL MATCH). We collect the managers into a list and ensure the company name and manager list are not null or empty. We then order the results by a score (doesn't currently provide value but could track how many times the doc has been retrieved).
Since only the text, score, and metadata properties get returned, we will need to map these extra values (documentId, company, and managers) in the metadata dictionary field. This means updating the final RETURN statement to include those.
Wrapping Up!
In this post, we looked at what RAG is and how retrieval queries work in LangChain. We also looked at a few examples of Cypher retrieval queries for Neo4j and constructed our own. We used the SEC filings data set for our query and saw how to pull extra context and return it mapped to the three properties LangChain expects.
If you are building or interested in more Generative AI content, check out the resources linked below. Happy coding!
Resources
- Demo application: Demo project that uses this retrieval query
- GitHub repository: Code for demo app that includes retrieval query
- Documentation: LangChain for Neo4j vector store
- Free online courses: Graphacademy: LLMs + Neo4j
Published at DZone with permission of Jennifer Reif. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments